本文主要是介绍【C++干货基地】深度理解C++中的高效内存管理方式 new delete,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

引入
哈喽各位铁汁们好啊,我是博主鸽芷咕《C++干货基地》是由我的襄阳家乡零食基地有感而发,不知道各位的城市有没有这种实惠又全面的零食基地呢?C++ 本身作为一门篇底层的一种语言,世面的免费课程大多都没有教明白。所以本篇专栏的内容全是干货让大家从底层了解C++,把更多的知识由抽象到简单通俗易懂。
⛳️ 推荐
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。
文章目录
- 引入
- ⛳️ 推荐
- 一、C/C++内存分布
- 1.1 内存布局图:
- 1.2 C/C++程序内存分配的几个区域:
- 二、C语言的内存管理方法
- 三、C/C++ 中的内存管理方法
- 3.1 new 和 delete 的使用
- 3.2 new 和 delete 在创建自定义类型时候的动作
- 四、new和delete的实现原理
- 4.1 operator new与函数
- 4.3 使用new 和new[ ] 是如何获取大小的
- 4.4 delete 和 delete[ ] 的区别
- 五、 malloc/free和new/delete的区别
一、C/C++内存分布
1.1 内存布局图:
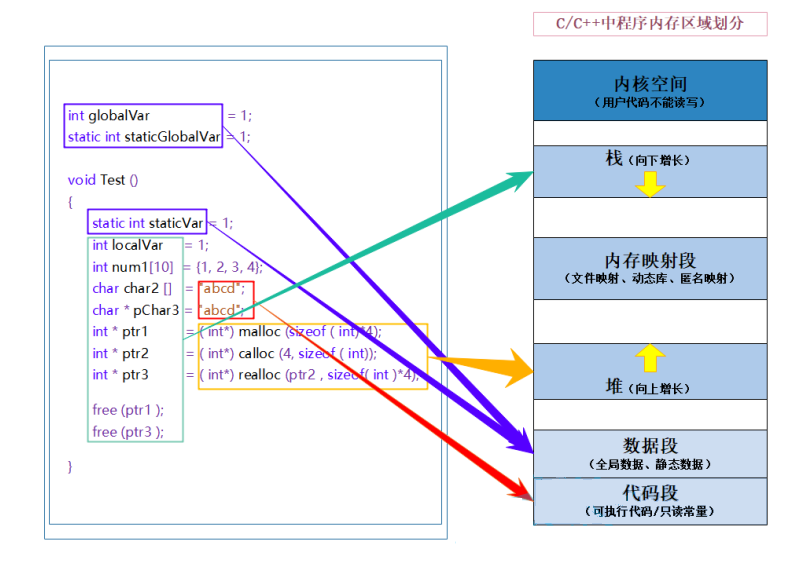
用通俗易懂的话来描述就是:
栈区(stack):存放的是我们平常创建的变量 形参 等 临时变量!堆区(heap):目前我们学的动态内存分配 都是在堆区开辟的!数据段(静态区)(static)存放全局变量、静态数据。程序结束后由系统释放。代码段: 可执行代码 和 只读 常量
1.2 C/C++程序内存分配的几个区域:
栈区(stack):在执行函数时,函数内局部变量的存储单元都可以在栈上创建,函数执行结束时这些存储单元自动被释放。栈内存分配运算内置于处理器的指令集中,效率很高,但是分配的内存容量有限。 栈区主要存放运行函数而分配的局部变量、函数参数、返回数据、返回地址等。堆区(heap):一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收 。分
配方式类似于链表。数据段(静态区)(static)存放全局变量、静态数据。程序结束后由系统释放。代码段:存放函数体(类成员函数和全局函数)的二进制代码。
二、C语言的内存管理方法
在C 语言中 我们通常都是使用 malloc 来申请空间,使用 free 来释放空间
void Test()
{int* p1 = (int*)malloc(sizeof(int));free(p1);// 1.malloc/calloc/realloc的区别是什么?int* p2 = (int*)calloc(4, sizeof(int));int* p3 = (int*)realloc(p2, sizeof(int) * 10);free(p3);
}但是malloc 还有 realloc 开辟空间都有失败的风向因此再项目中如果有开辟空间的行为是我们还得专门去写一个判断语句来避免空间开辟失败的其他报错。
void Test()
{int* tmp = (int*)malloc(sizeof(int));if (tmp == NULL){perror("malloc file");exit(-1);}int* p1 = tmp;free(p1);
}
三、C/C++ 中的内存管理方法
C语言内存管理方式在C++中可以继续使用,但有些地方就无能为力,而且使用起来比较麻烦,因此C++又提出了自己的内存管理方式:通过new和delete操作符进行动态内存管理。
- 在使用C语言的内存管理方式是不能进行自己去创建类对象的
- 而这也是我们设计 new 和 delete 的原因,更方便的开辟空间
3.1 new 和 delete 的使用
int main()
{// 1、用法上,变简洁了int* p0 = (int*)malloc(sizeof(int));int* p1 = new int;int* p2 = new int[10]; // new 10个int对象// 2、可以控制初始化int* p3 = new int(10); // new 1个int对象,初始化成10int* p4 = new int[10]{ 1,2,3,4,5 };return 0;
}
以上就是new 和 delete 的简单使用方法相信大家看一眼就会了非常的简单好上手。
3.2 new 和 delete 在创建自定义类型时候的动作
struct ListNode
{ListNode* _next;int _val;ListNode(int val):_next(nullptr), _val(val){}
};struct ListNode* CreateListNode(int val)
{struct ListNode* newnode = (struct ListNode*)malloc(sizeof(struct ListNode));if (newnode == NULL){perror("malloc fail");return NULL;}newnode->_next = NULL;newnode->_val = val;return newnode;
}以上是我们在C语言中开辟链表的方式,申请空间时书写非常麻烦还要去检查一下开辟空间是否失败。
- 而new是可以直接去给我们生成空间和自动调用构造函数初始化的
struct ListNode
{ListNode* _next;int _val;ListNode(int val):_next(nullptr), _val(val){}
};int main()
{// 1、用法上,变简洁了int* p0 = (int*)malloc(sizeof(int));int* p1 = new int;int* p2 = new int[10]; // new 10个int对象// 2、可以控制初始化int* p3 = new int(10); // new 1个int对象,初始化成10int* p4 = new int[10]{ 1,2,3,4,5 };// 3、自定义类型,开空间+构造函数// 4、new失败了以后抛异常,不需要手动检查ListNode* node1 = new ListNode(1);ListNode* node2 = new ListNode(2);ListNode* node3 = new ListNode(3);//...return 0;
}
四、new和delete的实现原理
new 关键字的好用我们已经体验过,malloc 和 new相比简直一个天上一个地下,用过new的人都不会再选择malloc 了, 那他的底层究竟是怎么实现的呢?
- 从下面这段代码我们可以看对内置类型进行new 开辟空间是去调用
operator new函数来进行开辟空间的。
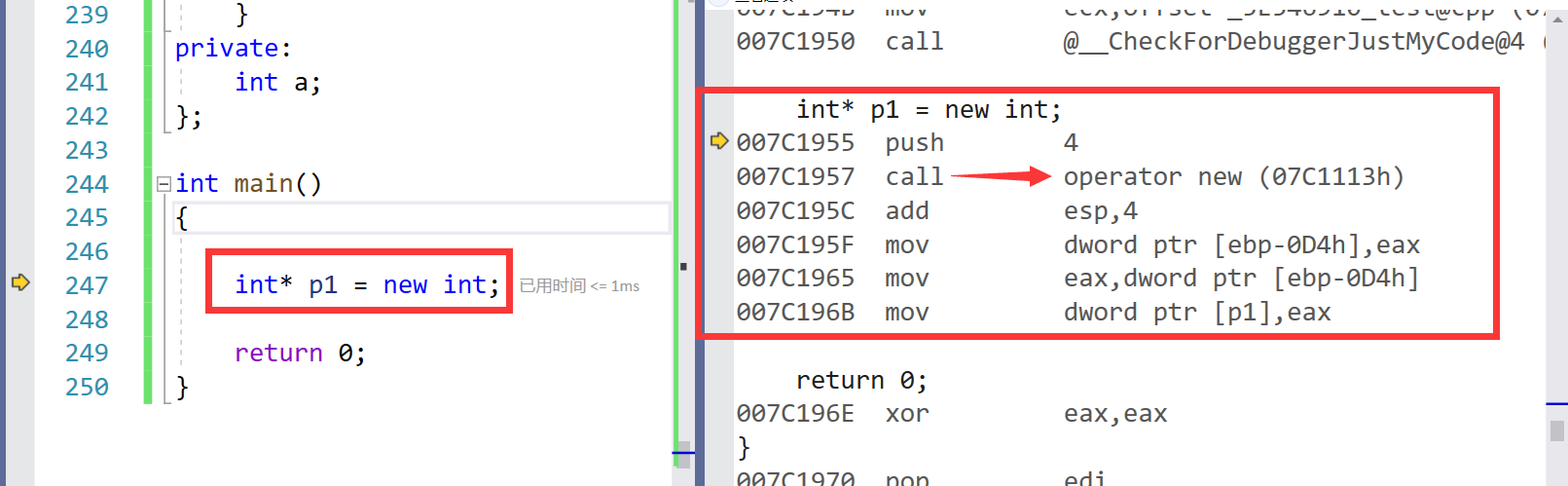
4.1 operator new与函数
- 那么operator new 函数是怎么实现的呢?
/*
operator new:该函数实际通过malloc来申请空间,当malloc申请空间成功时直接返回;申请空间
失败,尝试执行空 间不足应对措施,如果改应对措施用户设置了,则继续申请,否
则抛异常。
*/
void* __CRTDECL operator new(size_t size) _THROW1(_STD bad_alloc)
{// try to allocate size bytesvoid* p;while ((p = malloc(size)) == 0)if (_callnewh(size) == 0){// report no memory// 如果申请内存失败了,这里会抛出bad_alloc 类型异常static const std::bad_alloc nomem;_RAISE(nomem);}return (p);
}
/*
operator delete: 该函数最终是通过free来释放空间的
*/
void operator delete(void* pUserData)
{_CrtMemBlockHeader* pHead;RTCCALLBACK(_RTC_Free_hook, (pUserData, 0));if (pUserData == NULL)return;_mlock(_HEAP_LOCK); /* block other threads */__TRY/* get a pointer to memory block header */pHead = pHdr(pUserData);/* verify block type */_ASSERTE(_BLOCK_TYPE_IS_VALID(pHead->nBlockUse));_free_dbg(pUserData, pHead->nBlockUse);__FINALLY_munlock(_HEAP_LOCK); /* release other threads */__END_TRY_FINALLYreturn;
}
/*
free的实现
*/
#define free(p) _free_dbg(p, _NORMAL_BLOCK)
从这里我们就可以看到 operator new 实际上用 malloc 来封装实现开辟空间的
- 也就是说,new 的底层是 调用 operator new 而 operator new 的底层是malloc
- 那么new的底层实际上是对 malloc 封装实现的。
delete 也是同理在 delete 中我们发现 delete 是通过调用 operator delete 来实现开辟空间的而 operator delete 是通过 _free_dbg 来释放空间,_free_dbg 是free宏的 调用函数。
- 所以 delete 的底层就是 对 free 进行封装实现的。
4.3 使用new 和new[ ] 是如何获取大小的
这个问题就很简单了,我们编译器其实是可以自动获取类型大小的,我们使用sizeof() 关键字都可以获取大小为什么编译器不可以呢?
- 所以我们看到了,在汇编代码中一个 push 的大小就是我们要开空间的字节
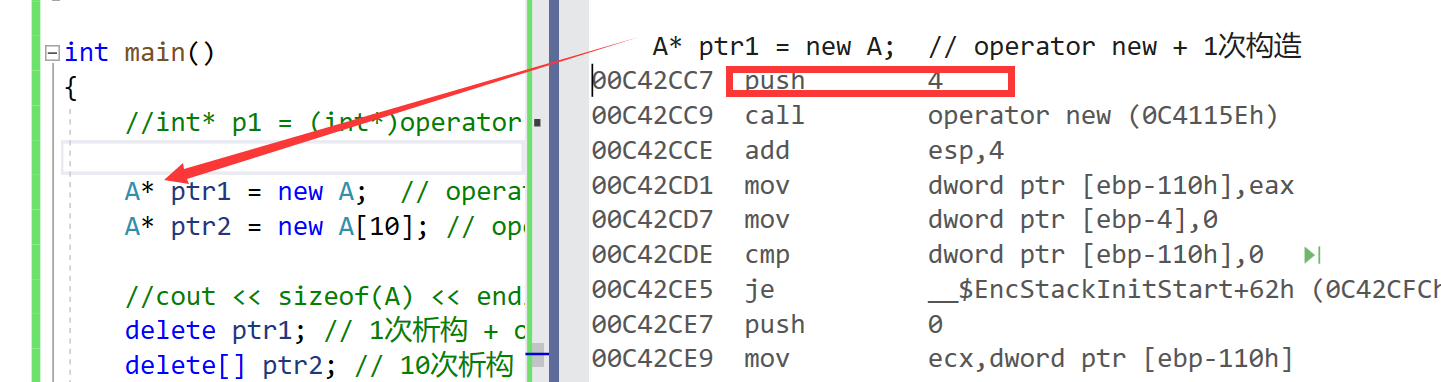
- 而 new[ ] 进行开辟连续的空间时我们就要注意了
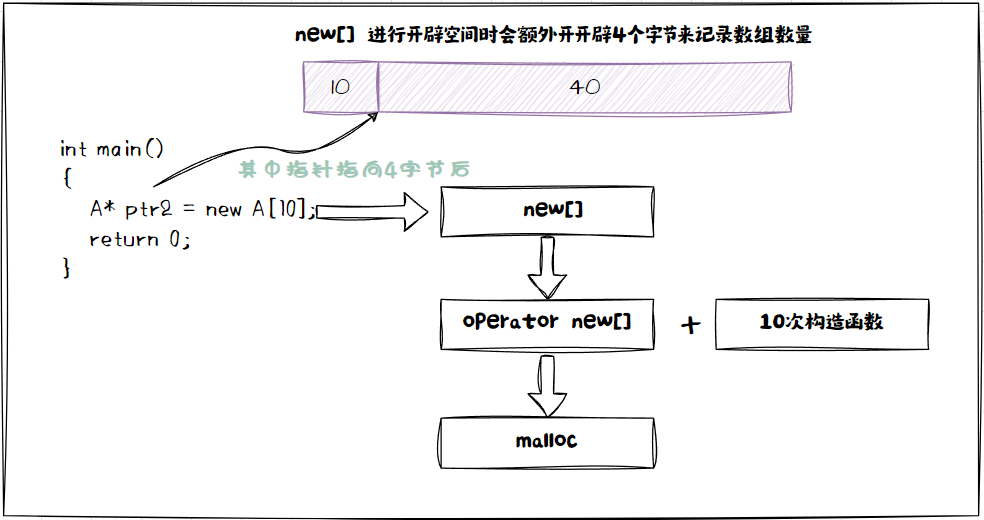
本来我申请个连续的空间难道不是40个字节嘛,为什么给我多开辟了4个字节?
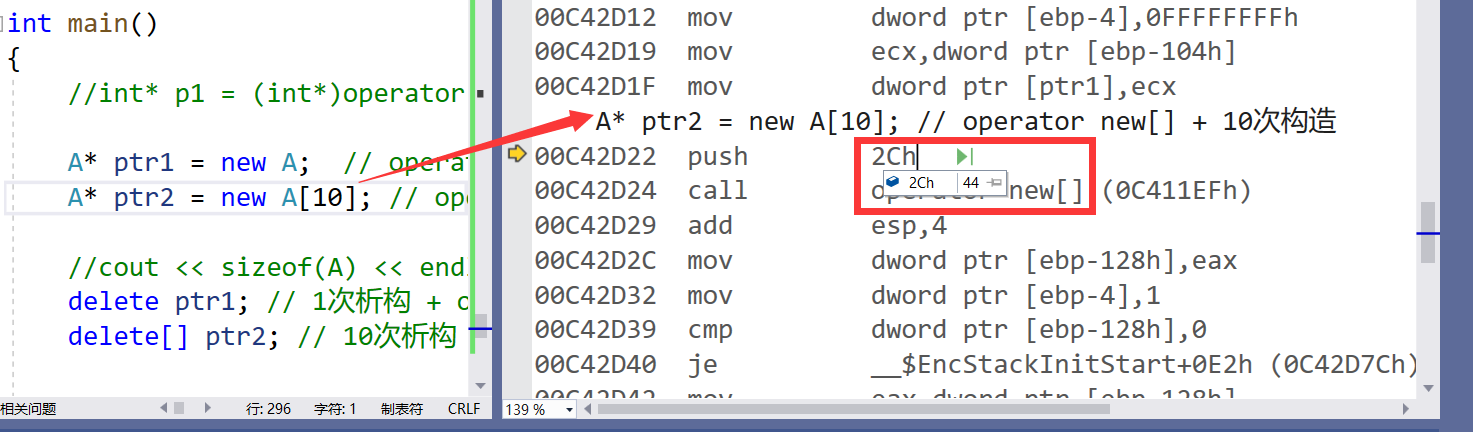
其实多出来的4个字节是为了在调用构造函数的时候记录需要构造的次数,已经析构的时候需要析构多少次。
- new[10]进行开辟空间时的步骤是这样的
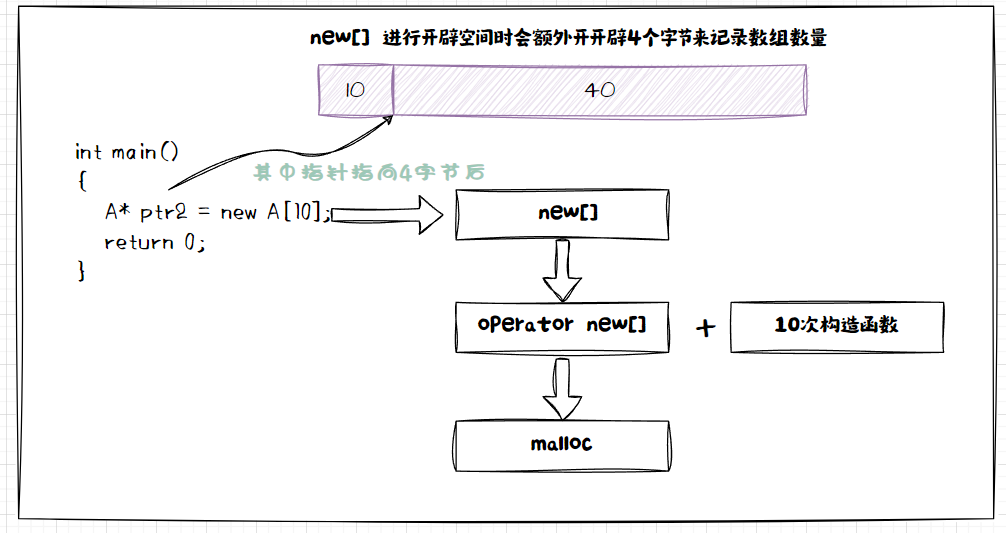
4.4 delete 和 delete[ ] 的区别
前面我们看到了 在使用 new[ ] 进行开辟数组空间的时候其实会多开4个字节记录数组个数那么这个数组个数的作用是干嘛呢?
- 记录数组的作用是为了给我们调用析构函数来用的
- 大家看一下下面的这段代码,使用
new[ ]创建的空间不使用deletet[ ]释放空间居然不报错。
class A
{
public:A(int a = 0): _a(a){cout << "A():" << this << endl;}private:int _a;
};int main()
{A* ptr1 = new A[10];delete ptr1;return 0;
}
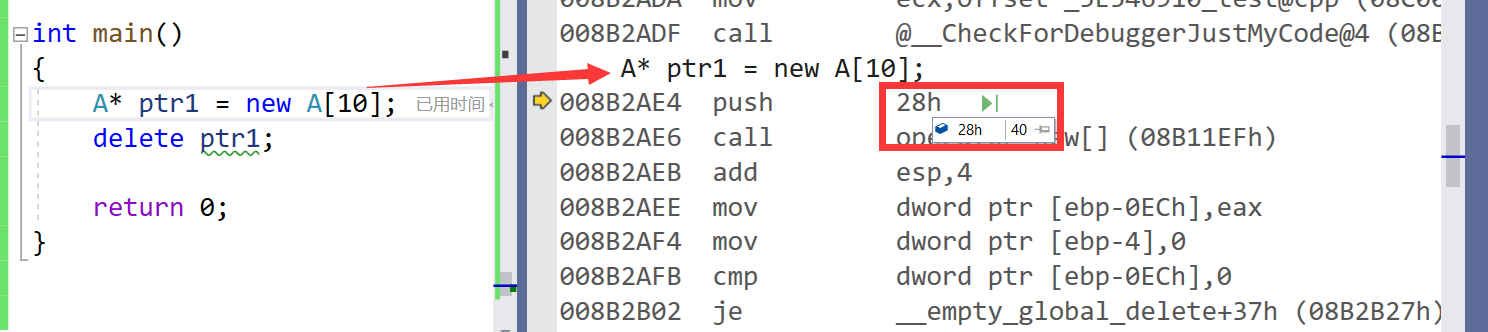
这是因为我们一旦没有写析构函数的话,new[ ] 就不会多开4个字节。那么我们就行free的时候指针就是在开头的位置不要往前偏移才能释放
- 而我们一旦写了析构函数new[ ] 就会为我们多开 4个字节存放数量
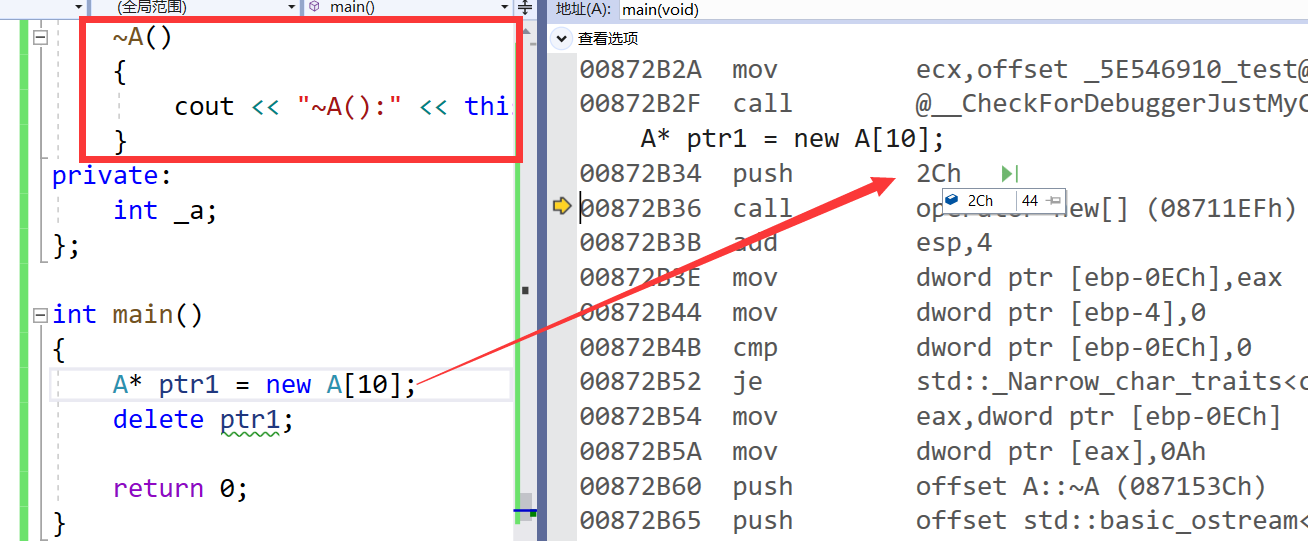
五、 malloc/free和new/delete的区别
malloc/free和new/delete的共同点是:都是从堆上申请空间,并且需要用户手动释放。不同的地方是:
- malloc和free是函数,new和delete是操作符
- malloc申请的空间不会初始化,new可以初始化
- malloc申请空间时,需要手动计算空间大小并传递,new只需在其后跟上空间的类型即可,如果是多个对象,[]中指定对象个数即可
- malloc的返回值为void*, 在使用时必须强转,new不需要,因为new后跟的是空间的类型
- malloc申请空间失败时,返回的是NULL,因此使用时必须判空,new不需要,但是new需要捕获异常
- 申请自定义类型对象时,malloc/free只会开辟空间,不会调用构造函数与析构函数,而new在申请空间后会调用构造函数完成对象的初始化,delete在释放空间前会调用析构函数完成空间中资源的清理

这篇关于【C++干货基地】深度理解C++中的高效内存管理方式 new delete的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




