本文主要是介绍郝斌数据结构--链表,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
模块一:线性结构
连续存储【数组】
1.数组定义
元素类型相同, 大小相等
2.数组的优缺点
# include <stdio.h>
# include <malloc.h>
# include <stdlib.h>
# include <stdbool.h>
//定义了一个数据类型,struct Arr
struct Arr
{int *pBase; //存储的使数组的第一个元素的地址int len; //数组所能容纳的最大元素的个数int cnt; // 当前数组有效元素的个数
};void init_arr();
bool append_arr(struct Arr *pArr, int val);
bool insert_arr(struct Arr *pArr, int pos, int val);
bool delete_arr(struct Arr *pArr, int pos, int *val);
bool is_empty(struct Arr *pArr);
bool is_full(struct Arr *pArr);
void sort_arr(struct Arr *pArr);
void show_arr(struct Arr *pArr);
void inversion_arr(struct Arr *pArr);int main(void)
{struct Arr arr; //定义了一个变量int val;init_arr(&arr, 6);append_arr(&arr, 3);append_arr(&arr, 5);append_arr(&arr, 6);//append_arr(&arr, 8);append_arr(&arr, 1);//append_arr(&arr, 6);insert_arr(&arr, 4, 9);if (delete_arr(&arr, 3, &val))printf("元素%d删除成功\n", val);elseprintf("删除操作失败\n"); show_arr(&arr);sort_arr(&arr);show_arr(&arr);inversion_arr(&arr);show_arr(&arr);return 0;
}void init_arr(struct Arr *pArr, int length)
{pArr->pBase = (int *)malloc(sizeof(int) * length);if (NULL == pArr->pBase){printf("动态内存分配失败!\n");exit(-1); //终止整个程序}else{pArr->len = length;pArr->cnt = 0;}return;
}bool is_empty(struct Arr *pArr)
{if (0 == pArr->cnt)return true;elsereturn false;
}
bool is_full(struct Arr *pArr)
{if (pArr->cnt == pArr->len)return true;elsereturn false;
}
void show_arr(struct Arr *pArr)
{if (is_empty(pArr))printf("数组为空\n");else{for (int i = 0; i < pArr->cnt; ++i)printf("%d ", pArr->pBase[i]);}printf("\n");
}bool append_arr(struct Arr *pArr, int val)
{if (is_full(pArr))return false;elsepArr->pBase[pArr->cnt] = val;pArr->cnt++;
}bool insert_arr(struct Arr *pArr, int pos, int val)
{if (is_full(pArr)){printf("数组已满\n");return false;}if (pos<1 || pos>pArr->cnt+1){printf("pos 参数不合法\n");return false;}for (int i = pArr->cnt - 1; i >= pos - 1; i--) // 3 5 6 1 8{pArr->pBase[i + 1] = pArr->pBase[i];}pArr->pBase[pos-1] = val;pArr->cnt++;return ;
}bool delete_arr(struct Arr *pArr, int pos, int *val)
{if (is_empty(pArr)){printf("数组为空\n");return false;}if (pos < 1 || pos > pArr->cnt){printf("pos 参数不合法\n");return false;}*val = pArr->pBase[pos - 1];for (int i = pos; i < pArr->cnt; i++) // 3 5 6 1 9{pArr->pBase[i-1] = pArr->pBase[i];}pArr->cnt--;}
void sort_arr(struct Arr *pArr)
{int tmp;for (int i = 0; i < pArr->cnt; i++){for (int j = i+1; j < pArr->cnt; j++){if (pArr->pBase[i] > pArr->pBase[j]){tmp = pArr->pBase[i];pArr->pBase[i] = pArr->pBase[j];pArr->pBase[j] = tmp;}}}
}
void inversion_arr(struct Arr *pArr)
{int tmp;for (int i = 0, j = pArr->cnt - 1; i < j; i++, j--){tmp = pArr->pBase[i];pArr->pBase[i] = pArr->pBase[j];pArr->pBase[j] = tmp;}
}
预备知识 typedef用法
typedef struct Student{
int id;
int age;
}ST; // 为数据类型起新的名字
typedef struct Student{
int id;
int age;
}* PST; //PST等价于struct Student *
typedef struct Student{
int id;
int age;
}* PST ST; //等价于 PST代表了struct Student *, ST代表了struct Student
离散存储【链表】
定义:n个节点离散分配,彼此通过指针相连,每个节点只有一个前驱结点、一个后续节点,
首节点没有前驱节点 尾节点没有后续节点
# include <stdio.h>
typedef struct Node
{
int data; //数据域
struct Node *pNext; //指针域
}NODE, *PNODE;//NODE等价于 struct Node, PNODE等价于struct Node*
int main(void)
{
return 0;
}
专业术语:
- 首节点 第一个有效节点
- 尾节点 最后一个有效节点
- 头节点 第一个有效节点之前的那个节点
- 头节点并不存放有效数据
- 头节点的数据类型与其他的节点的数据类型相同
- 加头节点的目的主要为了对链表的操作
- 头指针 指向头节点的指针变量
- 尾指针 指向尾节点的指针变量

分类:
- 单链表
- 双链表 每一个节点又两个指针域
- 循环链表 能通过一个节点找到其他的所有的节点
- 非循环链表
算法:
- 遍历
- 查找
- 清空
- 销毁
- 求长度
- 排序
- 删除节点
- 插入节点
非循环链表的插入的伪算法
(1)r = p->pNext;
(2)p->pNext = q;
(3)q->pNext = r;
如何把q指向的结点放在p指向节点的后面(看图再看下面的步骤)
(1)取出p所指向的结点的指针域
(2)p的指针域指向q
(3)把p的指针域的值(指向p后面的一个元素)赋值给q的指针域,
则q就指向p后面的一个元素
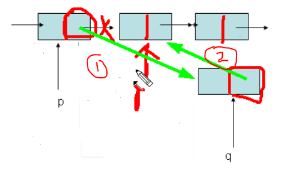
第二种方法(看同目录下的图)
q->pNext = p->pNext;
p->pNext = q;
(1)先使q指向后面一个结点(后面一个结点的地址存放在p的指针域部分)
(2)使p的指针域指向q
(q不是结点,,是一个指针变量,存放了节点的地址)

删除一个非循环链表的节点的伪算法
r = p->pNext;
p->pNext = p->pNext->pNext;//这样写会导致内存泄漏,所以需要释放
free(r);
删除一个链表的结点
(1)找不到第二个结点的地址,所以就不能释放,所以需要先指向然后释放
(2) p->pNext->pNext //p指针域指向的元素的指针域。
# include <stdio.h>
# include <malloc.h>
# include <stdlib.h>
# include <stdbool.h>
typedef struct Node
{int data; //数据域struct Node *pNext; //指针域
}NODE, *PNODE;//NODE等价于 struct Node, PNODE等价于struct Node*
void traverse_list(PNODE pHead);
PNODE create_list(void);
bool is_empty(PNODE pHead);
int length_list(PNODE pHead);
bool insert_list(PNODE pHead, int pos, int val);
bool delete_list(PNODE pHead, int pos, int *pval);
void sort_list(PNODE pHead);int main(void)
{PNODE pHead = NULL; //等价于struct Node* pHead = NULL;pHead = create_list(); //create_list()功能, 创建一个非循环单链表,并将该链表的头节点的地址赋给pHeadint len;int val;if (is_empty(pHead)){return;}else{len = length_list(pHead);printf("链表的长度为%d\n", len);traverse_list(pHead);sort_list(pHead);traverse_list(pHead);if (delete_list(pHead, 5, &val)){printf("删除元素%d成功!\n", val);}else{printf("删除元素失败!\n");}traverse_list(pHead);if (insert_list(pHead, 5, 66)){printf("插入元素成功\n");traverse_list(pHead);}else{printf("插入元素失败\n");}}return 0;
}PNODE create_list(void)
{int len;int val;PNODE pHead = (PNODE)malloc(sizeof(NODE));if (pHead == NULL){printf("内存分配失败,程序终止!\n");exit(-1);}PNODE pTail = pHead;pTail->pNext = NULL;printf("请输入链表节点的个数:len= ");scanf_s("%d", &len);for (int i = 0; i < len; i++){PNODE pNew = (PNODE)malloc(sizeof(NODE));if (pNew == NULL){printf("内存分配失败,程序终止!\n");exit(-1);}printf("请输入%d个链表数据", i + 1);scanf_s("%d", &val);pTail->pNext = pNew;pNew->data = val;pNew->pNext = NULL;pTail=pNew;}return pHead;}void traverse_list(PNODE pHead)
{PNODE p = pHead->pNext;while (NULL != p){printf("%d ", p->data);p = p->pNext;}printf("\n");
}bool is_empty(PNODE pHead)
{PNODE p = pHead;if (p->pNext == NULL){printf("链表为空!\n");return true;}else{return false;}
}
int length_list(PNODE pHead)
{PNODE p = pHead;int len=0;while (p->pNext != NULL){++len;p = p->pNext;}return len;
}void sort_list(PNODE pHead)
{PNODE p;PNODE q;int i, j, t;int len = length_list(pHead);for (i=0, p=pHead->pNext; i<len-1; p=p->pNext, i++){for (j=i+1, q=p->pNext; j<len; q=q->pNext, j++){if (p->data > q->data){t = p->data;p->data = q->data;q->data = t;}}}
}
bool insert_list(PNODE phead, int pos, int val)
{PNODE p = phead;int i = 0;while (NULL!=p && i<pos-1){p = p->pNext;i++;}if (NULL==p && i>pos-1)return false;PNODE pNew = (PNODE)malloc(sizeof(NODE));if (NULL == pNew){printf("内存分配失败\n");exit(-1);}pNew->pNext = p->pNext;pNew->data = val;p->pNext = pNew;return true;
}
bool delete_list(PNODE pHead, int pos, int *pval)
{PNODE p = pHead;int i = 0;while (NULL!=p->pNext && i<pos-1){p = p->pNext;i++;}if (i>pos-1 || NULL==p->pNext)return false;//删除操作PNODE q = p->pNext;*pval = q->data;p->pNext = p->pNext->pNext;free(q);return true;
}
这篇关于郝斌数据结构--链表的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







