本文主要是介绍共享单车数据分析与需求预测项目,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
注意:本文引用自专业人工智能社区Venus AI
更多AI知识请参考原站 ([www.aideeplearning.cn])
项目背景
自动自行车共享系统是传统自行车租赁的新一代,整个会员、租赁和归还过程都变得自动化。通过这些系统,用户可以轻松地在一个位置租赁自行车,然后在另一个位置归还。目前,全球有超过500个自行车共享计划,涵盖了超过50万辆自行车。由于这些系统在交通、环境和健康问题中的重要作用,它们引起了极大的关注。
除了自行车共享系统的有趣的实际应用之外,这些系统生成的数据特征使它们成为研究的有吸引力的对象。与其他交通服务(如公交或地铁)不同,这些系统明确记录了旅行的持续时间、出发地点和到达地点。这一特性将自行车共享系统转变成了一个可以用于城市移动性监测的虚拟传感器网络。因此,通过监测这些数据,预计可以检测到城市中的大多数重要事件。
项目目标
我们的项目旨在利用自动自行车共享系统的数据来实现城市移动性监测。具体目标包括:
- 分析城市中不同时间段的自行车共享模式,以了解城市的移动性趋势。
- 预测未来自行车共享需求,帮助共享系统优化自行车的分布和维护。
- 监测城市中的重要事件,如假期、天气和交通状况,以改进城市规划和交通管理。
项目应用
我们的项目有广泛的应用潜力,包括但不限于以下方面:
- 城市交通规划:通过了解自行车共享模式和需求,城市规划者可以更好地规划自行车道和交通设施。
- 环境保护:鼓励更多人使用自行车共享系统可以减少汽车尾气排放,有助于改善城市空气质量。
- 交通管理:监测特殊天气条件下的共享自行车使用情况可以帮助交通管理部门采取相应措施,以确保道路安全。
数据集描述
- instant:记录索引
- dteday:日期
- season:季节(1:冬季,2:春季,3:夏季,4:秋季)
- yr:年份(0: 2011, 1:2012)
- mnth:月份(1到12)
- hr:小时(0到23)
- holiday:天气是否为假日
- weekday:星期几
- workingday:是否是工作日
- weathersit:天气状况(1:晴天,2:多云,3:雨雪,4:暴雨)
- temp:标准化温度(摄氏度)
- atemp:标准化体感温度(摄氏度)
- hum:标准化湿度
- windspeed:标准化风速
- casual:非注册用户租赁数量
- registered:注册用户租赁数量
- cnt:总租赁自行车数量(包括非注册和注册用户)
模型选择与依赖库
为了实现项目目标,我们计划使用以下机器学习模型:
- 线性回归(LinearRegression)
- 岭回归(Ridge)
- Huber回归(HuberRegressor)
- 弹性网络回归(ElasticNetCV)
- 决策树回归(DecisionTreeRegressor)
- 随机森林回归(RandomForestRegressor)
- 极端随机树回归(ExtraTreesRegressor)
- 梯度提升回归(GradientBoostingRegressor)
我们将使用Python编程语言,并依赖于以下库来处理数据、构建模型和可视化结果:
- Pandas:用于数据清洗和预处理。
- NumPy:用于数值计算。
- Matplotlib和Seaborn:用于数据可视化。
- Scikit-learn:用于构建和评估机器学习模型。
代码实现
导入模块
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import warnings
%matplotlib inline
warnings.filterwarnings('ignore')
pd.options.display.max_columns = 999加载数据集
df = pd.read_csv('hour.csv')
df.head()| instant | dteday | season | yr | mnth | hr | holiday | weekday | workingday | weathersit | temp | atemp | hum | windspeed | casual | registered | cnt | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2011-01-01 | 1 | 0 | 1 | 0 | 0 | 6 | 0 | 1 | 0.24 | 0.2879 | 0.81 | 0.0 | 3 | 13 | 16 |
| 1 | 2 | 2011-01-01 | 1 | 0 | 1 | 1 | 0 | 6 | 0 | 1 | 0.22 | 0.2727 | 0.80 | 0.0 | 8 | 32 | 40 |
| 2 | 3 | 2011-01-01 | 1 | 0 | 1 | 2 | 0 | 6 | 0 | 1 | 0.22 | 0.2727 | 0.80 | 0.0 | 5 | 27 | 32 |
| 3 | 4 | 2011-01-01 | 1 | 0 | 1 | 3 | 0 | 6 | 0 | 1 | 0.24 | 0.2879 | 0.75 | 0.0 | 3 | 10 | 13 |
| 4 | 5 | 2011-01-01 | 1 | 0 | 1 | 4 | 0 | 6 | 0 | 1 | 0.24 | 0.2879 | 0.75 | 0.0 | 0 | 1 | 1 |
# 统计信息
df.describe()| instant | season | yr | mnth | hr | holiday | weekday | workingday | weathersit | temp | atemp | hum | windspeed | casual | registered | cnt | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 17379.0000 | 17379.000000 | 17379.000000 | 17379.000000 | 17379.000000 | 17379.000000 | 17379.000000 | 17379.000000 | 17379.000000 | 17379.000000 | 17379.000000 | 17379.000000 | 17379.000000 | 17379.000000 | 17379.000000 | 17379.000000 |
| mean | 8690.0000 | 2.501640 | 0.502561 | 6.537775 | 11.546752 | 0.028770 | 3.003683 | 0.682721 | 1.425283 | 0.496987 | 0.475775 | 0.627229 | 0.190098 | 35.676218 | 153.786869 | 189.463088 |
| std | 5017.0295 | 1.106918 | 0.500008 | 3.438776 | 6.914405 | 0.167165 | 2.005771 | 0.465431 | 0.639357 | 0.192556 | 0.171850 | 0.192930 | 0.122340 | 49.305030 | 151.357286 | 181.387599 |
| min | 1.0000 | 1.000000 | 0.000000 | 1.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1.000000 | 0.020000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 1.000000 |
| 25% | 4345.5000 | 2.000000 | 0.000000 | 4.000000 | 6.000000 | 0.000000 | 1.000000 | 0.000000 | 1.000000 | 0.340000 | 0.333300 | 0.480000 | 0.104500 | 4.000000 | 34.000000 | 40.000000 |
| 50% | 8690.0000 | 3.000000 | 1.000000 | 7.000000 | 12.000000 | 0.000000 | 3.000000 | 1.000000 | 1.000000 | 0.500000 | 0.484800 | 0.630000 | 0.194000 | 17.000000 | 115.000000 | 142.000000 |
| 75% | 13034.5000 | 3.000000 | 1.000000 | 10.000000 | 18.000000 | 0.000000 | 5.000000 | 1.000000 | 2.000000 | 0.660000 | 0.621200 | 0.780000 | 0.253700 | 48.000000 | 220.000000 | 281.000000 |
| max | 17379.0000 | 4.000000 | 1.000000 | 12.000000 | 23.000000 | 1.000000 | 6.000000 | 1.000000 | 4.000000 | 1.000000 | 1.000000 | 1.000000 | 0.850700 | 367.000000 | 886.000000 | 977.000000 |
# 数据类型信息
df.info()<class 'pandas.core.frame.DataFrame'> RangeIndex: 17379 entries, 0 to 17378 Data columns (total 17 columns):# Column Non-Null Count Dtype --- ------ -------------- ----- 0 instant 17379 non-null int64 1 dteday 17379 non-null object 2 season 17379 non-null int64 3 yr 17379 non-null int64 4 mnth 17379 non-null int64 5 hr 17379 non-null int64 6 holiday 17379 non-null int64 7 weekday 17379 non-null int64 8 workingday 17379 non-null int64 9 weathersit 17379 non-null int64 10 temp 17379 non-null float6411 atemp 17379 non-null float6412 hum 17379 non-null float6413 windspeed 17379 non-null float6414 casual 17379 non-null int64 15 registered 17379 non-null int64 16 cnt 17379 non-null int64 dtypes: float64(4), int64(12), object(1) memory usage: 2.3+ MB
# 每个特征中不重复的值
df.apply(lambda x: len(x.unique()))instant 17379 dteday 731 season 4 yr 2 mnth 12 hr 24 holiday 2 weekday 7 workingday 2 weathersit 4 temp 50 atemp 65 hum 89 windspeed 30 casual 322 registered 776 cnt 869 dtype: int64
预处理数据集
# 检查是否有空值
df.isnull().sum()instant 0 dteday 0 season 0 yr 0 mnth 0 hr 0 holiday 0 weekday 0 workingday 0 weathersit 0 temp 0 atemp 0 hum 0 windspeed 0 casual 0 registered 0 cnt 0 dtype: int64
df = df.rename(columns={'weathersit':'weather','yr':'year','mnth':'month','hr':'hour','hum':'humidity','cnt':'count'})
df.head()| instant | dteday | season | year | month | hour | holiday | weekday | workingday | weather | temp | atemp | humidity | windspeed | casual | registered | count | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2011-01-01 | 1 | 0 | 1 | 0 | 0 | 6 | 0 | 1 | 0.24 | 0.2879 | 0.81 | 0.0 | 3 | 13 | 16 |
| 1 | 2 | 2011-01-01 | 1 | 0 | 1 | 1 | 0 | 6 | 0 | 1 | 0.22 | 0.2727 | 0.80 | 0.0 | 8 | 32 | 40 |
| 2 | 3 | 2011-01-01 | 1 | 0 | 1 | 2 | 0 | 6 | 0 | 1 | 0.22 | 0.2727 | 0.80 | 0.0 | 5 | 27 | 32 |
| 3 | 4 | 2011-01-01 | 1 | 0 | 1 | 3 | 0 | 6 | 0 | 1 | 0.24 | 0.2879 | 0.75 | 0.0 | 3 | 10 | 13 |
| 4 | 5 | 2011-01-01 | 1 | 0 | 1 | 4 | 0 | 6 | 0 | 1 | 0.24 | 0.2879 | 0.75 | 0.0 | 0 | 1 | 1 |
df = df.drop(columns=['instant', 'dteday', 'year'])# 将 int 列更改为类别
cols = ['season','month','hour','holiday','weekday','workingday','weather']for col in cols:df[col] = df[col].astype('category')
df.info()<class 'pandas.core.frame.DataFrame'> RangeIndex: 17379 entries, 0 to 17378 Data columns (total 14 columns):# Column Non-Null Count Dtype --- ------ -------------- ----- 0 season 17379 non-null category1 month 17379 non-null category2 hour 17379 non-null category3 holiday 17379 non-null category4 weekday 17379 non-null category5 workingday 17379 non-null category6 weather 17379 non-null category7 temp 17379 non-null float64 8 atemp 17379 non-null float64 9 humidity 17379 non-null float64 10 windspeed 17379 non-null float64 11 casual 17379 non-null int64 12 registered 17379 non-null int64 13 count 17379 non-null int64 dtypes: category(7), float64(4), int64(3) memory usage: 1.0 MB
探索性数据分析
fig, ax = plt.subplots(figsize=(20,10))
sns.pointplot(data=df, x='hour', y='count', hue='weekday', ax=ax)
ax.set(title='工作日和周末的自行车数量')[Text(0.5, 1.0, '工作日和周末的自行车数量')]

fig, ax = plt.subplots(figsize=(20,10))
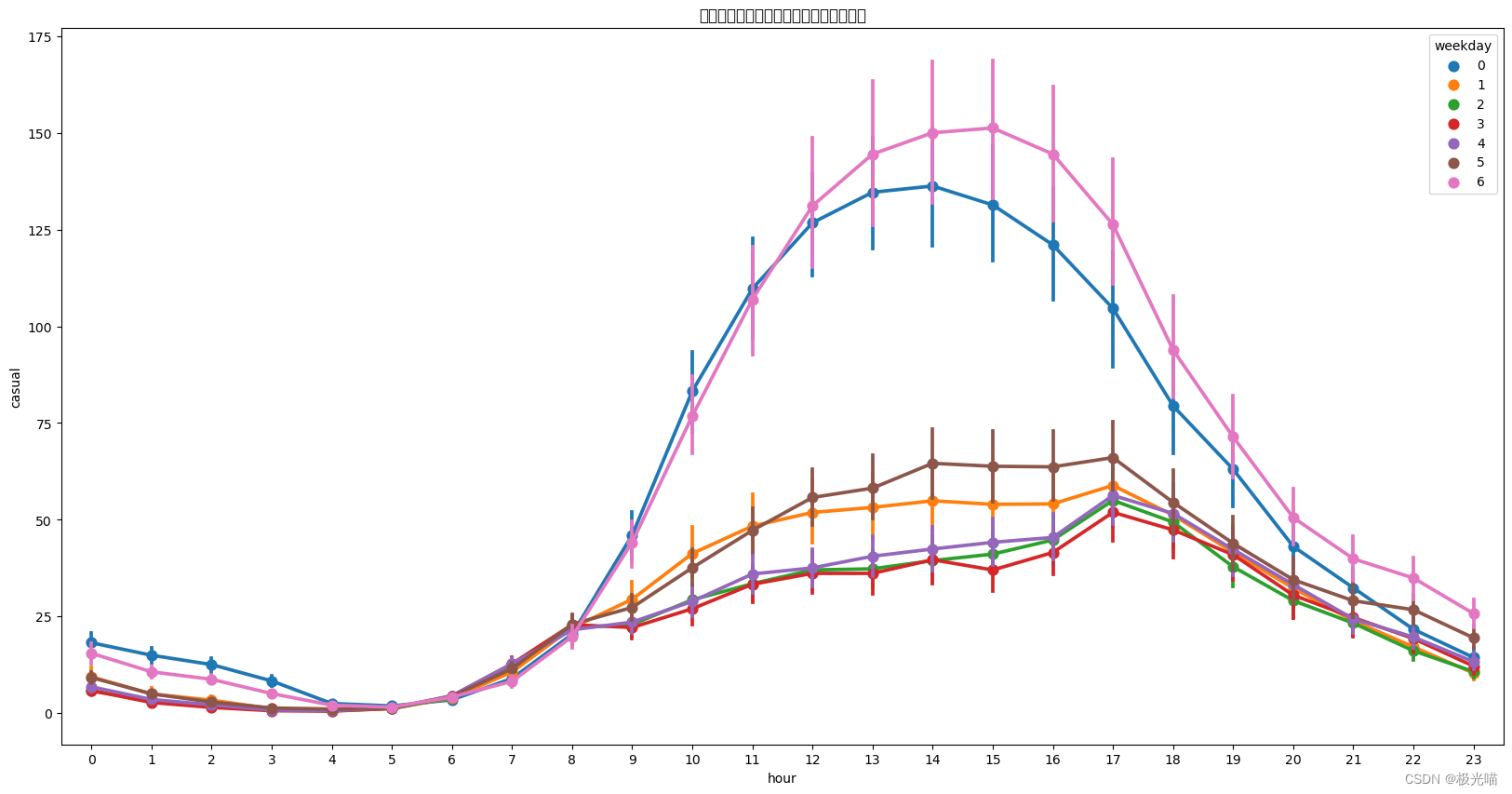
sns.pointplot(data=df, x='hour', y='casual', hue='weekday', ax=ax)
ax.set(title='工作日和周末的自行车数量:未注册用户')[Text(0.5, 1.0, '工作日和周末的自行车数量:未注册用户')]
fig, ax = plt.subplots(figsize=(20,10))
sns.pointplot(data=df, x='hour', y='registered', hue='weekday', ax=ax)
ax.set(title='工作日和周末的自行车数量:注册用户')
[Text(0.5, 1.0, '工作日和周末的自行车数量:注册用户')]

fig, ax = plt.subplots(figsize=(20,10))
sns.pointplot(data=df, x='hour', y='count', hue='weather', ax=ax)
ax.set(title='不同天气下的自行车数量')[Text(0.5, 1.0, '不同天气下的自行车数量')]

fig, ax = plt.subplots(figsize=(20,10))
sns.pointplot(data=df, x='hour', y='count', hue='season', ax=ax)
ax.set(title='不同季节下的自行车数量')[Text(0.5, 1.0, '不同季节下的自行车数量')]

fig, ax = plt.subplots(figsize=(20,10))
sns.barplot(data=df, x='month', y='count', ax=ax)
ax.set(title='不同月份下的自行车数量')[Text(0.5, 1.0, '不同月份下的自行车数量')]

fig, ax = plt.subplots(figsize=(20,10))
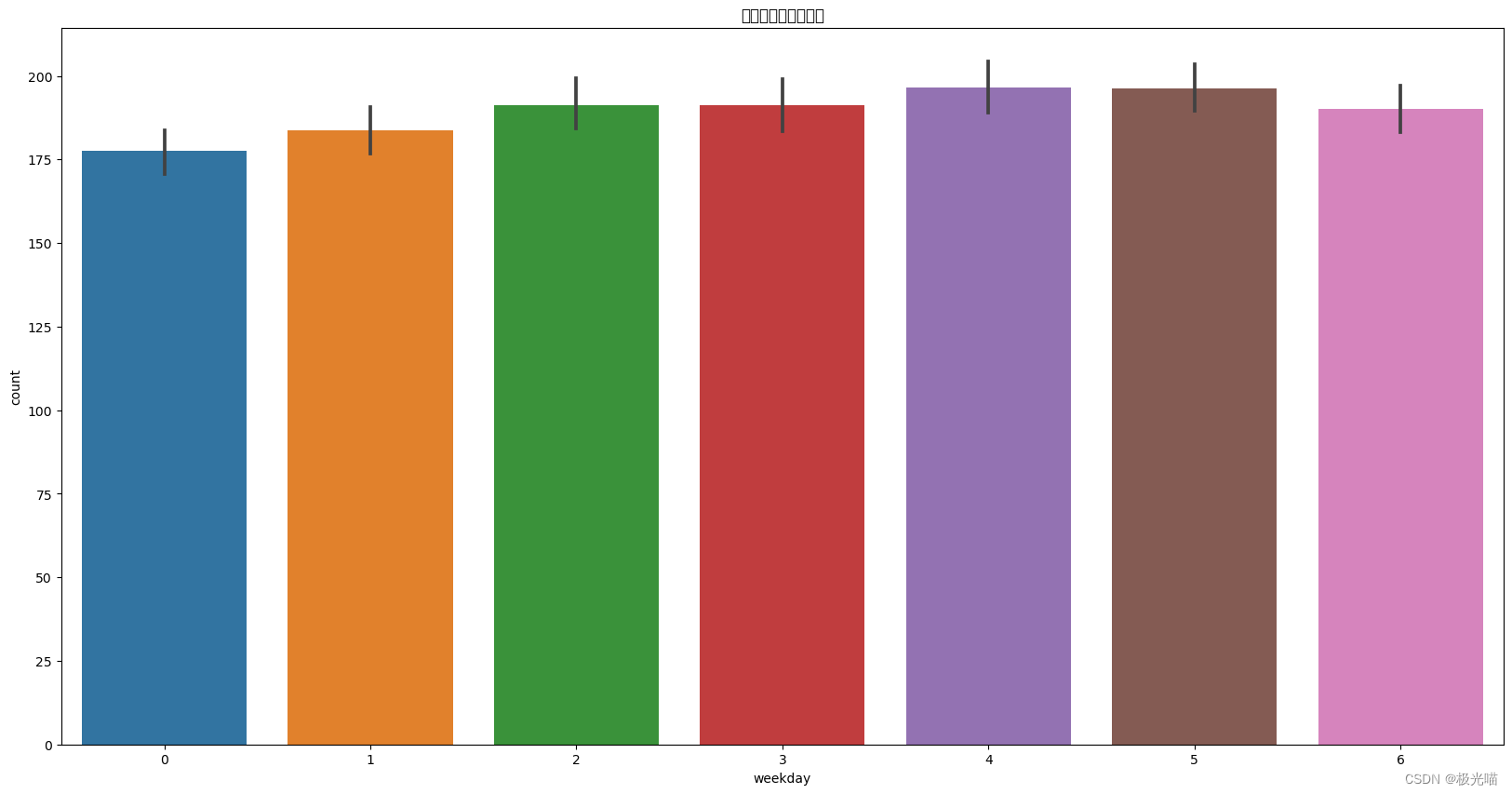
sns.barplot(data=df, x='weekday', y='count', ax=ax)
ax.set(title='不同天的自行车数量')[Text(0.5, 1.0, '不同天的自行车数量')]
fig, (ax1,ax2) = plt.subplots(ncols=2, figsize=(20,6))
sns.regplot(x=df['temp'], y=df['count'], ax=ax1)
ax1.set(title="气温与用户数量的关系")
sns.regplot(x=df['humidity'], y=df['count'], ax=ax2)
ax2.set(title="湿度与用户数量的关系")[Text(0.5, 1.0, '湿度与用户数量的关系')]

from statsmodels.graphics.gofplots import qqplot
fig, (ax1,ax2) = plt.subplots(ncols=2, figsize=(20,6))
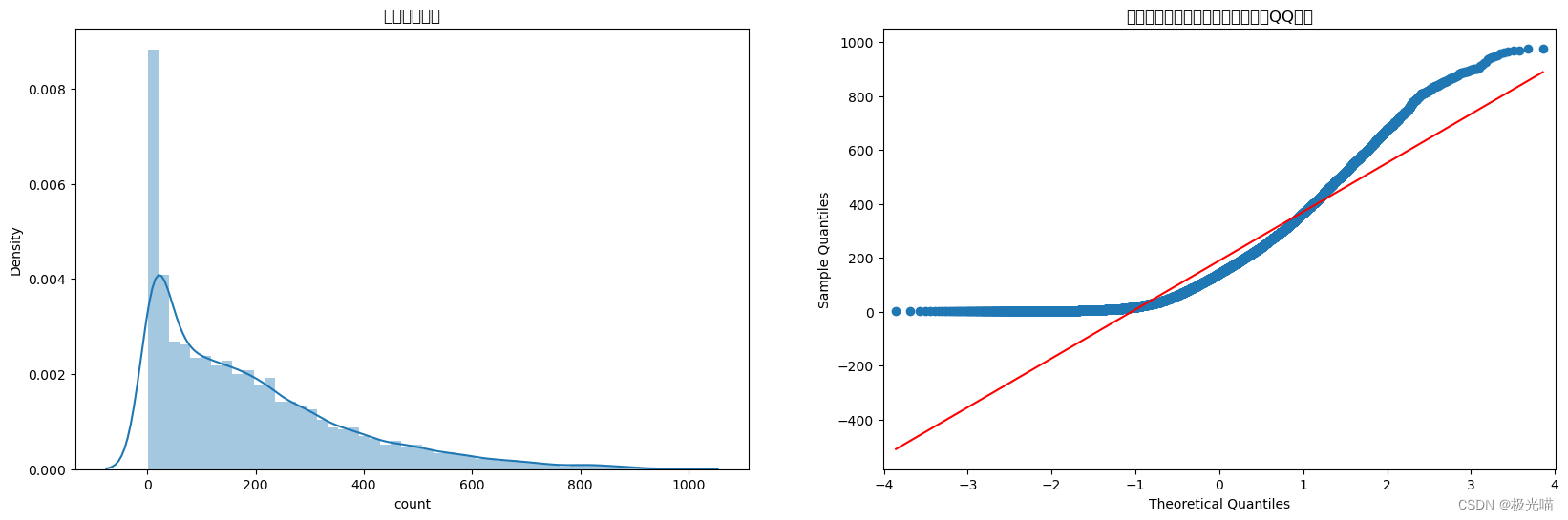
sns.distplot(df['count'], ax=ax1)
ax1.set(title='用户数量分布')
qqplot(df['count'], ax=ax2, line='s')
ax2.set(title='理论分位数与样本分位数的比较(QQ图)')[Text(0.5, 1.0, '理论分位数与样本分位数的比较(QQ图)')]
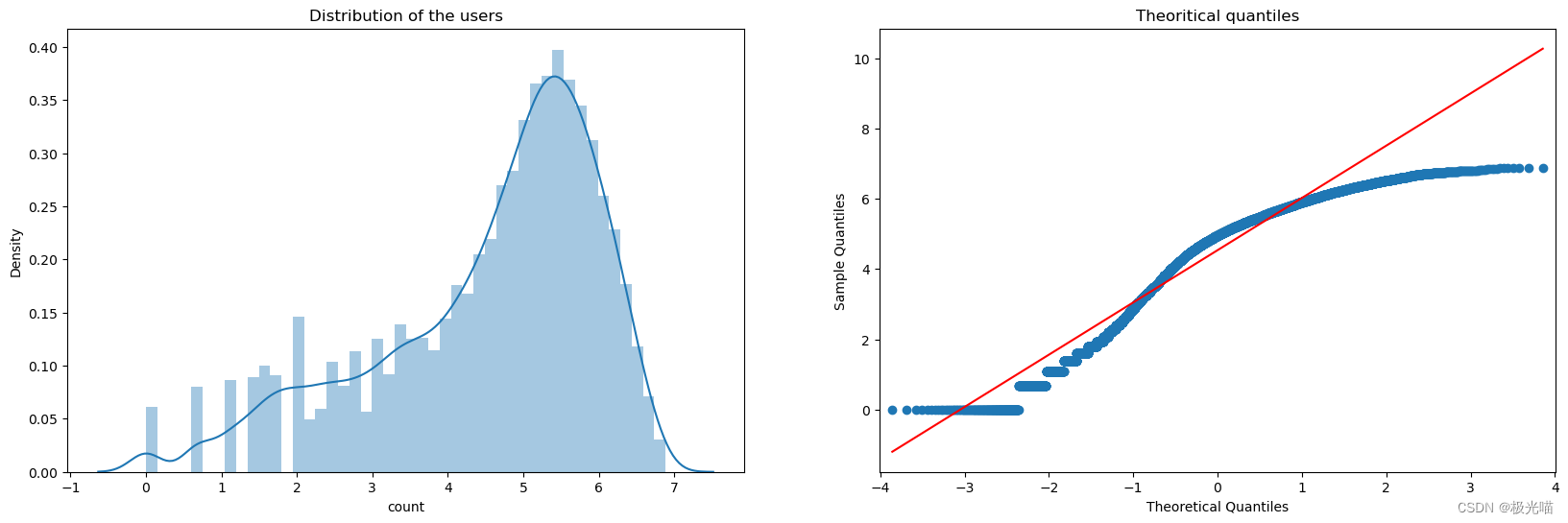
df['count'] = np.log(df['count'])应用对数变换(如np.log(df['count'])),然后重新绘制分布和 QQ(分位数-分位数)图可能很有用,原因如下:
数据的正态性:许多统计技术假设数据服从正态分布。对数变换有助于标准化严重倾斜的变量分布。
稳定方差:对数变换可以稳定数据集的方差。在方差随平均值增加的情况下,应用对数变换可以产生更加同方差的数据集。
线性化关系:转换可以线性化关系,使数据中的模式更易于解释并适合线性建模。
减少异常值的影响:它还可以减少异常值的影响,因为对数转换显着缩小了数据的范围。
fig, (ax1,ax2) = plt.subplots(ncols=2, figsize=(20,6))
sns.distplot(df['count'], ax=ax1)
ax1.set(title='Distribution of the users')
qqplot(df['count'], ax=ax2, line='s')
ax2.set(title='Theoritical quantiles')[Text(0.5, 1.0, 'Theoritical quantiles')]
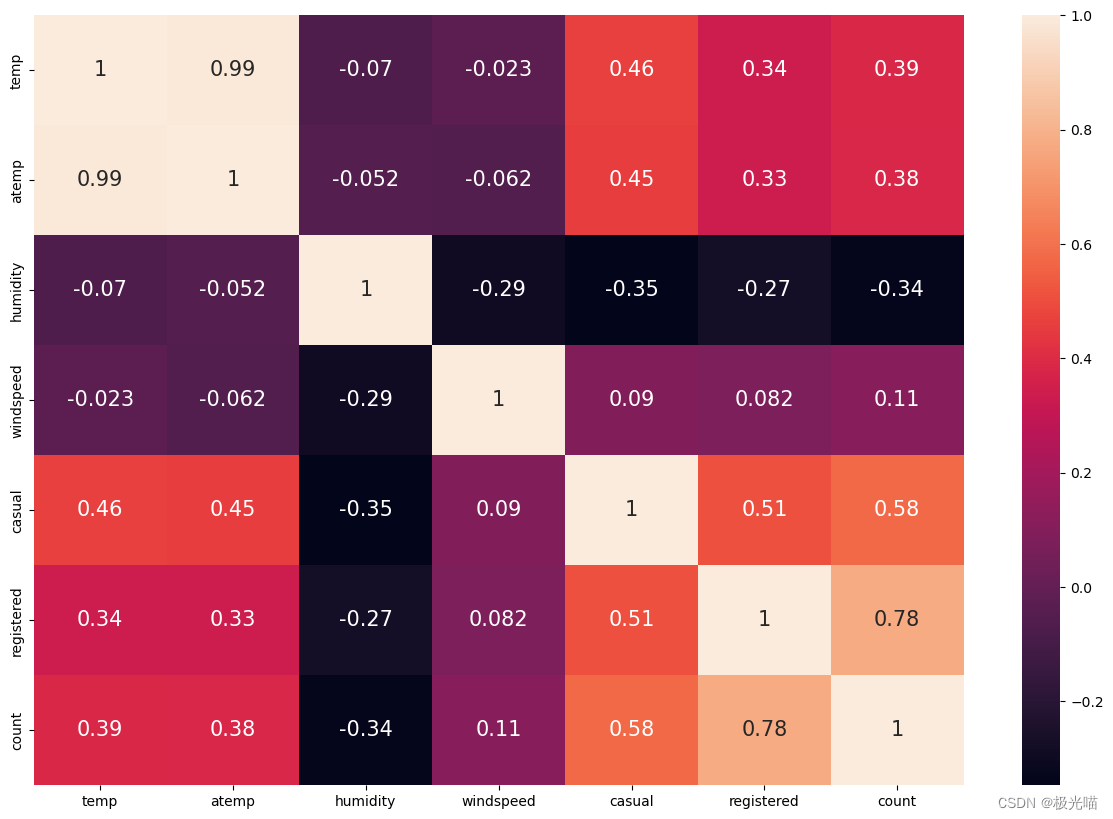
相关矩阵
corr = df.corr()
plt.figure(figsize=(15,10))
sns.heatmap(corr, annot=True, annot_kws={'size':15})<Axes: >
独热编码
pd.get_dummies(df['season'], prefix='season', drop_first=True)| season_2 | season_3 | season_4 | |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 |
| ... | ... | ... | ... |
| 17374 | 0 | 0 | 0 |
| 17375 | 0 | 0 | 0 |
| 17376 | 0 | 0 | 0 |
| 17377 | 0 | 0 | 0 |
| 17378 | 0 | 0 | 0 |
17379 rows × 3 columns
df_oh = dfdef one_hot_encoding(data, column):data = pd.concat([data, pd.get_dummies(data[column], prefix=column, drop_first=True)], axis=1)data = data.drop([column], axis=1)return datacols = ['season','month','hour','holiday','weekday','workingday','weather']for col in cols:df_oh = one_hot_encoding(df_oh, col)
df_oh.head()| temp | atemp | humidity | windspeed | casual | registered | count | season_2 | season_3 | season_4 | month_2 | month_3 | month_4 | month_5 | month_6 | month_7 | month_8 | month_9 | month_10 | month_11 | month_12 | hour_1 | hour_2 | hour_3 | hour_4 | hour_5 | hour_6 | hour_7 | hour_8 | hour_9 | hour_10 | hour_11 | hour_12 | hour_13 | hour_14 | hour_15 | hour_16 | hour_17 | hour_18 | hour_19 | hour_20 | hour_21 | hour_22 | hour_23 | holiday_1 | weekday_1 | weekday_2 | weekday_3 | weekday_4 | weekday_5 | weekday_6 | workingday_1 | weather_2 | weather_3 | weather_4 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.24 | 0.2879 | 0.81 | 0.0 | 3 | 13 | 2.772589 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 1 | 0.22 | 0.2727 | 0.80 | 0.0 | 8 | 32 | 3.688879 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 2 | 0.22 | 0.2727 | 0.80 | 0.0 | 5 | 27 | 3.465736 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 3 | 0.24 | 0.2879 | 0.75 | 0.0 | 3 | 10 | 2.564949 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| 4 | 0.24 | 0.2879 | 0.75 | 0.0 | 0 | 1 | 0.000000 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
X = df_oh.drop(columns=['atemp', 'windspeed', 'casual', 'registered', 'count'], axis=1)
y = df_oh['count']模型训练
from sklearn.linear_model import LinearRegression, Ridge, HuberRegressor, ElasticNetCV
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor, ExtraTreesRegressormodels = [LinearRegression(),Ridge(),HuberRegressor(),ElasticNetCV(),DecisionTreeRegressor(),RandomForestRegressor(),ExtraTreesRegressor(),GradientBoostingRegressor()]
from sklearn import model_selection
def train(model):kfold = model_selection.KFold(n_splits=5, shuffle=True, random_state=42) pred = model_selection.cross_val_score(model, X, y, cv=kfold, scoring='neg_mean_squared_error')cv_score = pred.mean()print('Model:',model)print('CV score:', abs(cv_score))代码中的内容cv_score就像您正在使用的机器学习模型的成绩单。它告诉您模型的表现如何。它的工作原理如下:
交叉验证 (CV):将您的数据视为一个大馅饼。代码将这个馅饼切成 5 片(因为n_splits=5)。然后,它使用 4 个切片来训练模型,并使用 1 个切片来测试模型。这样做 5 次,每次使用不同的切片进行测试。
评分:每次测试后,模型根据其错误(均方误差)获得分数。但在代码中,这些分数是负数。
平均分数 ( cv_score):这cv_score是这些测试分数的平均值。我们将负分改为正分(使用abs(cv_score))以使它们更容易理解。较低的分数意味着模型犯的错误较少,这很好!
因此,cv_score平均分数表明您的模型的预测效果如何。它的值越低越好。
for model in models:train(model)Model: LinearRegression() CV score: 0.44849511159541205 Model: Ridge() CV score: 0.4484090089563206 Model: HuberRegressor() CV score: 0.46596807512124105 Model: ElasticNetCV() CV score: 0.45614918135359145 Model: DecisionTreeRegressor() CV score: 0.44255199359646225 Model: RandomForestRegressor() CV score: 0.23279282002190094 Model: ExtraTreesRegressor() CV score: 0.23485168754583902 Model: GradientBoostingRegressor() CV score: 0.35702811006978274
线性回归:基本回归模型,CV分数为0.4485,表示平均误差。
岭回归:与线性回归类似,但经过正则化,误差稍低,为 0.4484。
Huber 回归器:一个对异常值具有鲁棒性的模型,CV 得分为 0.4660,表明它对此数据集可能不那么有效。
ElasticNetCV:结合L1和L2正则化,CV得分为0.4561。
决策树回归器:非线性模型,CV 得分为 0.4426。
随机森林回归器:决策树的集合,显示出明显更好的 CV 分数 0.2328。
Extra Trees Regressor:与随机森林类似,但 CV 分数稍好,为 0.2349。
Gradient Boosting Regressor:一个专注于纠正其上一个子模型错误的集成模型,CV 得分为 0.3570。
CV 分数越低表明模型性能越好。RandomForest 和 ExtraTrees 回归器显示了这些模型中的最佳结果。
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42)model = RandomForestRegressor()
model.fit(x_train, y_train)
y_pred = model.predict(x_test)# 绘制误差差
error = y_test - y_pred
fig, ax = plt.subplots()
ax.scatter(y_test, error)
ax.axhline(lw=3, color='black')
ax.set_xlabel('Observed')
ax.set_ylabel('Error')
plt.show()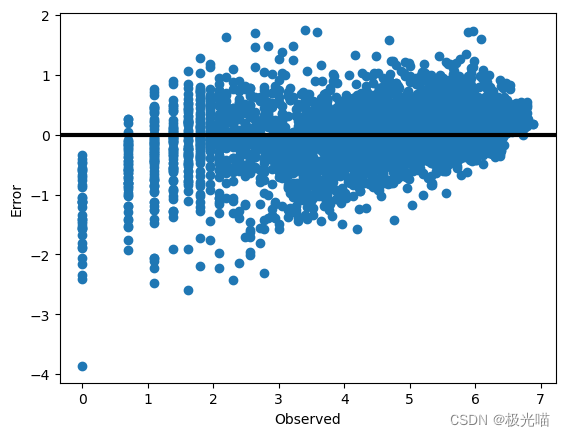
from sklearn.metrics import mean_squared_error
np.sqrt(mean_squared_error(y_test, y_pred))0.48527134611361483
代码与数据集下载
详情请见共享单车数据分析与需求预测项目-VenusAI (aideeplearning.cn)
这篇关于共享单车数据分析与需求预测项目的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









