本文主要是介绍【求助】西门子S7-200PLC定时中断+数据归档的使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
已经经历了种种磨难来记录我的数据(使用过填表程序、触摸屏的历史记录和数据归档)之后,具体可以看看这篇文章:🚪西门子S7-200PLC的数据归档怎么用?,出现了新的问题。
问题的提出
最新的数据归档方式,无论是利用线圈互锁还是定时器触发数据归档的上升沿,最快最快1s时间内能记录37个数据。无论我怎么调小定时器的时间间隔,最多只能记录37个。这距离我的理想状态(1s记录50个数据)还是有一点差距。
问题解决1
打电话问了西门子售后服务电话,她给我提出了三点非常珍贵的建议:
- 之所以1s最多记录37个数据,这与数据归档写在子程序中有关,和程序的扫描周期有影响。
- 之前把数据归档放在中断子程序里不能用,所以把中断子程序换成子程序,因为在中断程序里没有上升沿的作用
- 应该如何解决,能够记录更多的数据个数,可以试一试定时中断的功能(特殊寄存器SMB34、35,定时器T32、96)
于是我用T32和T96定时器+中断程序的方式,再在中断程序里进行数据归档。

在它的中断程序第一行就写了一个加法器,看有没有进中断。

调试结果1
根本没有进中断程序,监控状态时这里面一片灰色,就连SM0.0都没有闭合。
问题解决2
是不是因为中断程序不能在子程序中使用,而必须在主程序中进行中断初始化,于是有了以下尝试,把中断程序写在主程序里面:
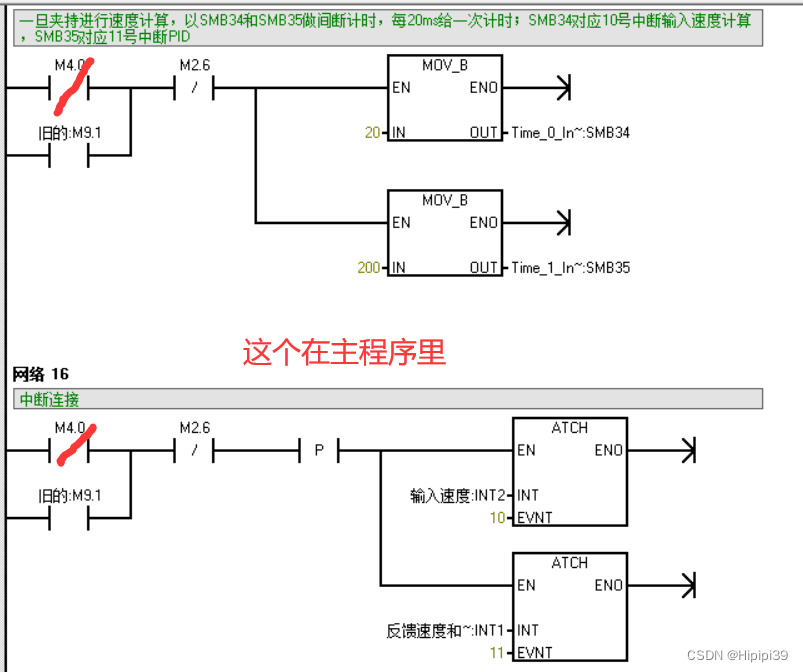
同样的,也是在中断程序第一行写加数器,观察有没有进入中断。
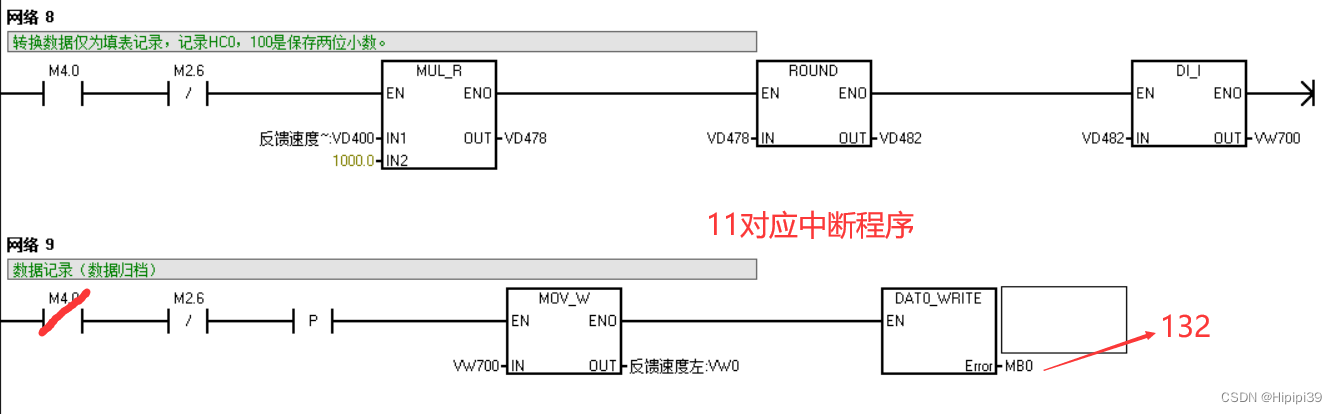
调试结果2
监控模式下确实能看到它的数字在上升了,这应该就是进中断了吧。
但是我是利用定时中断+数据归档的方式记录数据,数据归档子程序的Error显示报错信息132,代表指令访问存储卡失败,这是怎么回事呢?
我的疑问:
Q1:中断程序的初始化是只有在主程序当中才能使用吗?
Q2:为什么会出现数据归档132错误?(是我中断程序里面数据归档前面多加了一个上升沿导致的吗?)
Q3:利用定时中断+数据归档的方式,在中断程序初始化要用上升沿触发,在中断程序里面数据归档前还要用上升沿吗?
我整个PLC程序不止用到一个定时中断,我总共用到了SMB34、定时器T32、T96进行定时中断,
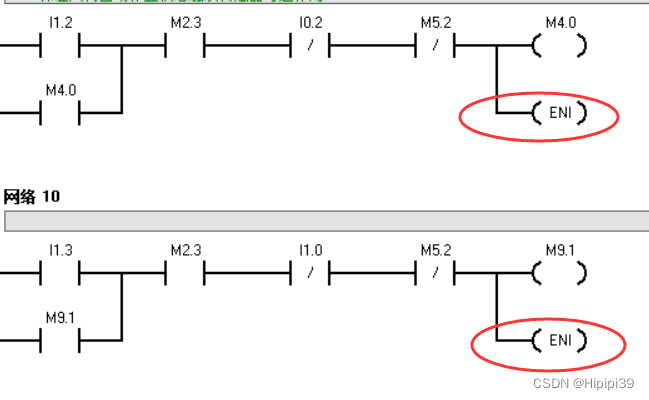
Q4: 开中断的线圈ENI要放在哪里?是只能放在中断程序初始化ATCH同一个网络之下吗?主程序和子程序里面都能放吗?
西门子PLC论坛里的讨论和提问链接我也放一下,🔗这个问题的讨论;🔗这个问题的提问
虽然我知道这个社区可能关注西门子PLC的人不多,但如果碰到一位大佬刚好看到我这个问题了呢。
非常感谢大家!!!
这篇关于【求助】西门子S7-200PLC定时中断+数据归档的使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





