本文主要是介绍聊聊go语言中的GMP模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
写在文章开头
我们都知道go语言通过轻量级线程协程解决并发问题,按照go语言的思想这些协程运行完成后即焚,那么go语言如何保证并发线程有序获取协程呢?

带着这个问题我们从go语言底层的源码来阐述这个问题:

Hi,我是 sharkChili ,是个不断在硬核技术上作死的 java coder ,是 CSDN的博客专家 ,也是开源项目 Java Guide 的维护者之一,熟悉 Java 也会一点 Go ,偶尔也会在 C源码 边缘徘徊。写过很多有意思的技术博客,也还在研究并输出技术的路上,希望我的文章对你有帮助,非常欢迎你关注我的公众号: 写代码的SharkChili 。
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。

协程GMP模型详解
GMP模型工作原理
本质上go语言采用了GMP模型:
- g:即goroutine,也就是我们说的协程。
- m:可以直接理解为执行协程的线程。
- p:和线程绑定,真正进行逻辑处理的处理器。
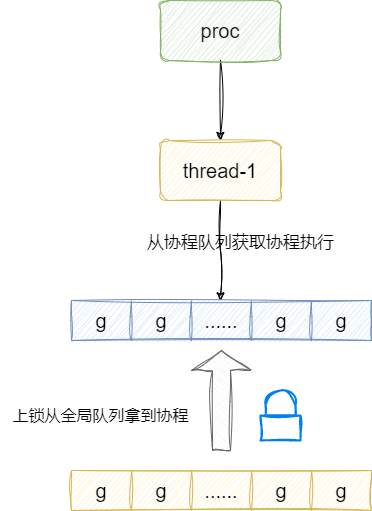
基于gmp模型,每个处理器绑定一个线程,而线程都会分配一个协程队列,为了避免多线程运行协程总是要到全局队列上锁导致的并发冲突导致程序性能下降。go语言提出每个处理器获取协程队列时先上锁然后直接从全局队列中获取一批的协程到本地队列再运行:
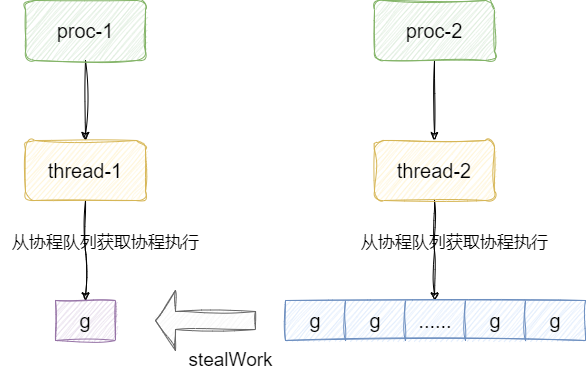
基于这个基础go语言对每一个线程的利用都做到的极致的压榨,一旦线程对应协程队列为空时,且全局的协程队列也为空的时候,当前处理器p就会采取stealWork窃取其他处理器的本次队列中窃取任务,尽可能不让这个线程停止功能,以提升线程利用率:
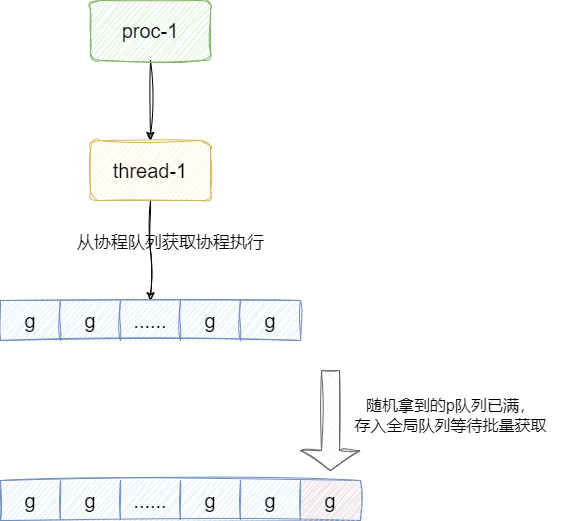
此后每当新建一个协程,它就会随机找到一个处理器p的队列,若发现其队列已满无法容纳自己,这个协程就会被存放到协程队列中,等待p下次批量获取:
源码印证
了解gmp的工作流程后,我们就可以通过源码的方式印证这个问题,首先来看看处理器模型的源码,通过runitme2.go可知处理器p的结构:
- 通过m指针指向绑定的线程。
- 通过
runqhead和runqtail标明当前处理器协程队列的地址范围,再通过runq指定队列长度。 - 通过
runnext标明下一个要执行的协程的地址。
type p struct {//唯一标识id int32// m的指针m muintptr // back-link to associated m (nil if idle)// 协程队列队首和队尾偏移量runqhead uint32runqtail uint32//本地队列数组runq [256]guintptr//下一个要执行的协程地址runnext guintptr//......
}
每个处理器p都会从主协程g0开始调用schedule方法不断执行队列中的协程,如下源码所示,拿到处理器对应的线程后通过findRunnable中找到可运行的协程并执行:
func schedule() {//获取当前处理器的线程mp := getg().m//......top:pp := mp.p.ptr()//......//获取可运行的协程gp, inheritTime, tryWakeP := findRunnable() // blocks until work is available//......//执行协程execute(gp, inheritTime)
}
步入proc.go的findRunnable方法就可以看到我们上文所说的协程调度过程了,首先从本地队列获取,若没有则上锁从全局队列中批量获取协程,明确确认上述两个队列都没有任务再从其他处理器的本地队列中窃取协程运行:
func findRunnable() (gp *g, inheritTime, tryWakeP bool) {mp := getg().mtop:pp := mp.p.ptr()//......// 先从本地队列获取if gp, inheritTime := runqget(pp); gp != nil {return gp, inheritTime, false}// 本地队列没有则到全局队列获取if sched.runqsize != 0 {lock(&sched.lock)gp := globrunqget(pp, 0)unlock(&sched.lock)if gp != nil {return gp, false, false}}//上述情况都不符合则尝试通过stealWork窃取其他处理器本地队列的协程if mp.spinning || 2*sched.nmspinning.Load() < gomaxprocs-sched.npidle.Load() {if !mp.spinning {mp.becomeSpinning()}gp, inheritTime, tnow, w, newWork := stealWork(now)if gp != nil {// Successfully stole.return gp, inheritTime, false}//......}goto top
}
这里我们不妨看看从全局队列获取协程的源码proc.go,本质上就是通过重量级锁获取一批协程调用runqput存入队列中:
func globrunqget(pp *p, max int32) *g {//上锁assertLockHeld(&sched.lock)//若全局队列为空直接返回if sched.runqsize == 0 {return nil}//获取全局队列的大小和处理器数计算出n,经过各种逻辑处理后这个n就是最后要获取的协程数n := sched.runqsize/gomaxprocs + 1if n > sched.runqsize {n = sched.runqsize}if max > 0 && n > max {n = max}if n > int32(len(pp.runq))/2 {n = int32(len(pp.runq)) / 2}//扣减全局队列大小sched.runqsize -= n//获取协程,并通过runqput存入当前处理器的本地队列中gp := sched.runq.pop()n--for ; n > 0; n-- {gp1 := sched.runq.pop()runqput(pp, gp1, false)}return gp
}
而窃取协程的代码也在proc.go中,它会再三确认当前处理器没有可运行协程后到其他非空闲协程中窃取:
func stealWork(now int64) (gp *g, inheritTime bool, rnow, pollUntil int64, newWork bool) {pp := getg().m.p.ptr()ranTimer := falseconst stealTries = 4for i := 0; i < stealTries; i++ {stealTimersOrRunNextG := i == stealTries-1//获取可以可窃取的处理器p2for enum := stealOrder.start(fastrand()); !enum.done(); enum.next() {if sched.gcwaiting.Load() {// GC work may be available.return nil, false, now, pollUntil, true}p2 := allp[enum.position()]//如果遍历到自己则跳过if pp == p2 {continue}//......//明确确认p2非空闲后窃取其协程存入本地队列中运行if !idlepMask.read(enum.position()) {if gp := runqsteal(pp, p2, stealTimersOrRunNextG); gp != nil {return gp, false, now, pollUntil, ranTimer}}}}return nil, false, now, pollUntil, ranTimer
}
小结
本文通过图解结合源码印证的方式介绍了go语言中gmp如何实现高效并发,希望对你有帮助。
我是 sharkchili ,CSDN Java 领域博客专家,开源项目—JavaGuide contributor,我想写一些有意思的东西,希望对你有帮助,如果你想实时收到我写的硬核的文章也欢迎你关注我的公众号: 写代码的SharkChili 。
因为近期收到很多读者的私信,所以也专门创建了一个交流群,感兴趣的读者可以通过上方的公众号获取笔者的联系方式完成好友添加,点击备注 “加群” 即可和笔者和笔者的朋友们进行深入交流。

这篇关于聊聊go语言中的GMP模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



