本文主要是介绍大数据第五天(操作hive的方式),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 操作hive的方式
- hive 存储位置
- hive 操作语法
- 创建数据表的方式
操作hive的方式
hive 存储位置
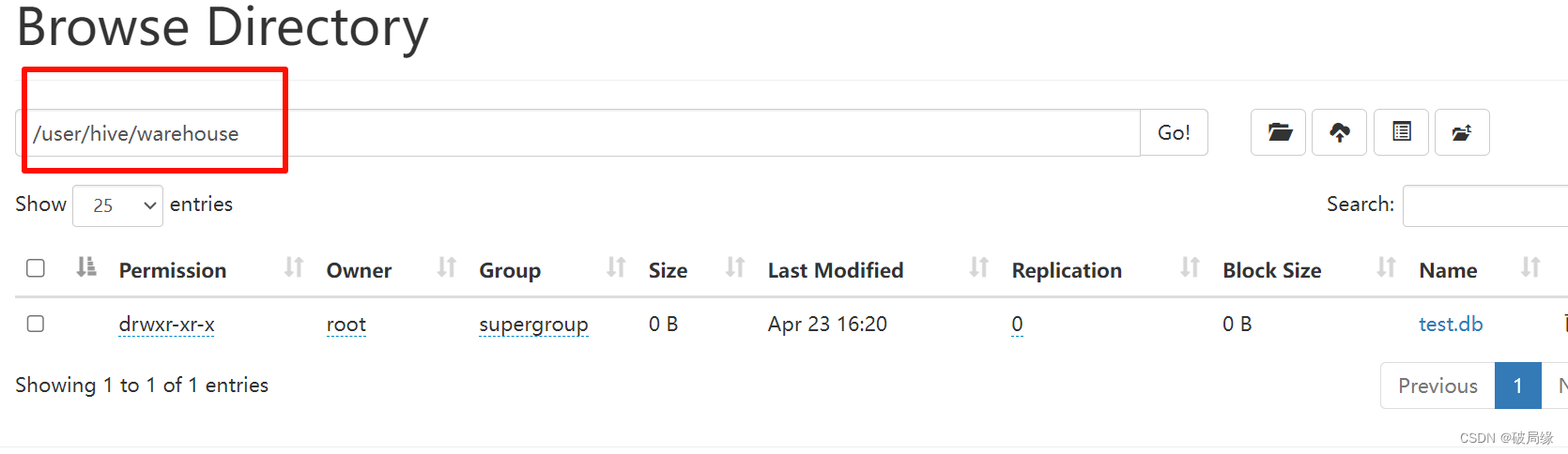
hive 操作语法
创建数据表的方式
– 创建数据库
create database if not exists test
我们创建数据库表的时候,hive是将我们的数据自动添加到数据表中,但是需要我们注意,自动添加的方式我们需要按照特定格式添加到数据库中,\001添加到数据表中的方式
我们写一个案例的方式
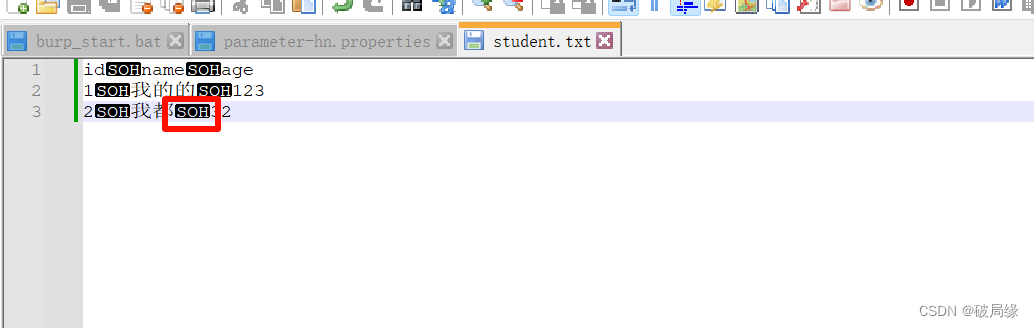
我们这里可以看到SOH默认的制表是\001的方式,
我们这个soh是打不出来的,我们只能通过替换的方式
创建数据表
create table student(id int comment "id",name string comment "名字",age int comment "年龄"
) comment "学生表";
我们将数据库上传到hive中 ,查询数据库
上传hive中
hadoop fs -put student.txt /user/hive/warehouse/test.db/student
查数据
select * from student;
本地加载数据
load data local inpath '/root/hivedata/student.txt' into table student;
[2024-04-23 17:40:35] org.apache.hadoop.hive.ql.parse.SemanticException:Line 1:23 Invalid path ‘’/root/hivedata/student.txt’': No files matching path file:/root/hivedata/student.txt

成功解决了
刚才问题有点尴尬是这样的一个问题
我们连接是hive的hadoop03的服务器但是我们操作hadoop01服务器哎
这篇关于大数据第五天(操作hive的方式)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







