本文主要是介绍数据洞察创新挑战赛之智能运维赛参赛攻略--皮卡丘的皮卡,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
关联比赛: 数据洞察创新挑战赛之智能运维赛
背景和参赛动机
1.个人背景和专业领域
四川大学本科,中南大学研究生,专业是医学图像处理。目前就职于深信服,主要做云安全相关的业务开发工作。
2.何时开始关注和参与数据科学竞赛?
2022年就在关注和简单参与天池竞赛,一开始只是为了一些T恤之类的小礼品。年底拿了一次奖,就慢慢打专门花时间来参加天池的比赛了。
3.参加数据洞察创新挑战赛的初衷和动机是什么?
运维赛和目前工作比较相关,算是对成绩比较了解,也很感兴趣,想尝试一下。
项目选择和团队组建
4.在数据洞察创新挑战赛中选择的项目是什么?
两个赛道都参与了
5.是单独参赛还是组队参赛?如果组队,如何组建团队?
组队参赛,但是基本都是一个人在打,组建团队也是帮朋友拿一下奖励和团队线下旅游机会。
6.是如何确定参赛项目和团队成员的?
有固定的队友,一般都是加同事和表弟。
参赛过程和挑战
7.对参赛过程的描述,包括数据集的理解、特征工程、模型选择等步骤
基于赛题给出的微服务trace,metric等数据,找出导致高响应时间trace迟(超过slo阈值)出现的span列表。
- trace: 一个(对外)接口的完整链路。(A,B,C,D,E组成一个trace)
- span: 链路中每一次微服务接口调用的不同阶段,是一个span。(如由A发起调用到B,会产生一个client span。到达B上运行时,会产生一个server span)
- slo阈值:微服务服务质量的属性,通常会带一个百分位和一个延迟,如95分位[200ms],就是微服务95%的请求响应时间需要小于200毫秒。题目给出的slous位于94分~95分位间。
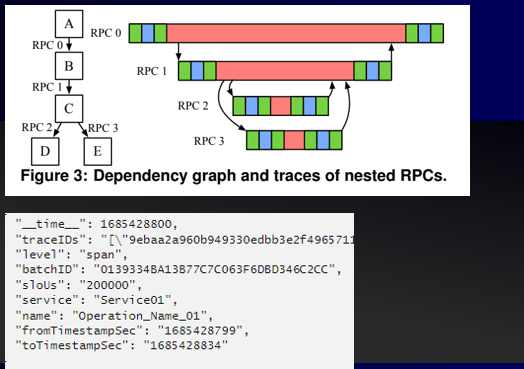
span分为四类:
- client: 客户端,记录一次调用从客户端发起到返回客户端
- server: 服务端,记录一次调用从到达服务端到离开服务端(粉红色)一般来说,server的父span是一个client,同时可能包含多个子client类型span。正常情况下server的时间区间在它父span之内。
- producer: 生产者,类似客户端,通常往消息队列写入消息。
- consumer: 消费者,类似服务端,异步消费,时间可能和producer相隔很远。
独占时间:span是trace的主要组成部分,所以挖掘span的特征是重点。由于span的响应/延迟是受它子span影响的,排除子span影响的独占时间才能反映这个span的耗时。不通类型的span,独占时间含义也不同:
- client:接口网络侧的延迟。一般来说client时间减去子span的时间,就是client的独占时间。
- server:接口在服务端实际运行的时间。由于server可能存在多个子span,所以需要先把子span合并区间,再计算总时间,最终用server span的时间减去子span的总时间,得到独占时间。
独占时间算是一个最显著的特征,每个trace只选择真实时间最大的span,都能拿到一半以上(1900+)的分数。
其他特征:
由于存在错误的span和异步span,为span定义is_error和is_consumer属性
- is_error:如果当前span的上位节点中存在error的span,则自身也属于error,is_error标记为1
- is_consumer:如果当前span的上位节点中存在consumer类型的span,则自身也属于consumer,is_consumer标记为1
延迟相关特征
- 90~95分位的独占延迟。
- 90~95分位延迟均值,标准差
metric特征
- pod当前cpu占用
- pod当前内存占用
- pod分配的cpu限制
- pod分配的内存限制
为了能直接根据输入数据得出结果,需要设计两个算法:
- span排序算法,排在前面的越有可能成为根因,选择根因时必然是依次往下选
- span阈值算法,针对不通path接口,计算出合理的阈值,大于阈值的所有span为根因结果。
排序算法:
排序算法只需要简单对各个span的特征进行加权求和作为
- span的评分,并按大小排列即可,用到的特征包括:
- span独占时间
- span独占时间90-95延迟
- span运行时间90-95延迟
- 90~95分位延迟均值,标准差
- span运行时间中点对应的pod的cpu、内存消耗
- is_error,is_consumer
由于没有想到好的训练方法,只是手动修改权重提交测试。最终结果其实只使用了(真实时间 - 94延迟)作为了排序评分。
阈值算法:
当一个span恢复正常运行(真实运行时间变成95分位的均值延迟),trace的整体响应时间也会减少。重复操作,当减少到SLOus一定倍率(1.5倍)时,就认为达到阈值,之前的span集合就是根因列表。
这里需要设计一个trace时间修正算法,当一个span恢复后,其后续的span的起始时间都可能被修改,顺序位:
- 子孙修正:优先修改子孙的span起始时间,需要根据每个阶段等比减少的时间对应调整时间。
- 兄弟修正:位于后面的兄弟节点,简单整体前移即可。
- 长辈修正:最后修正长辈以及后续节点,简单整体前移即可。
并发运行
由于所有特征都是提前提取的,需要统计的数据都可以对每个PATH接口处理处理。
最终计算根因时,每个trace计算相互独立,无需上下文支持,可以直接并行计算。
总结
运维赛的赛题门槛较高,前期能出高分的队没几个。我对微服务相关的知识有过了解,理解了独占时间后,分数基本都是前几,结合span延迟信息,最终取得了不错的结果。
8.参赛过程中遇到的最大挑战是什么?是如何克服的?
方案的可解释下不强,有时候尝试出一些答案,但是很难解释为什么这些span是异常的。最终并没有克服问题,只是在尝试找规律。
9.选手有没有遇到比较棘手的问题?如何解决的?
过程中成绩一直无法提高,稳定在1850左右,后来发现是因为提前把consumer类型的span以及其后代都筛除了。筛除的原因是我认为这些数据无法影响主接口的调用。
后来在写代码注释的时候才发现这个问题,放开这部分span后才有了最终的成绩。
成果和展望
10.在数据洞察创新挑战赛中取得了怎样的成绩?
答:取得了不错的成绩,运维赛的一等奖,主要还是占了初赛的便宜,都没想到初赛会有30%的分数。
11.对自己的表现和成果是否满意?
答:对表现和结果都很满意。
12.对未来参加数据科学竞赛有什么打算和展望?
答:希望下次比赛可以给出更详细的背景介绍与赛题分析,方便其他队伍参与进来。
总结
13.参加数据洞察创新挑战赛的故事和经验分享
从6月到10月底,这个比赛跨度很长。运维赛复赛长时间没有进展,都有点放弃了,在最后一天查看代码时候发现了一些小问题,把成绩提高上来了,也算是对我认真写注释的回报。最后占了初赛30%的便宜拿了第一,运气和结果都很好。
14.对其他有意参加下一届数据洞察创新挑战赛的人的建议和鼓励
答:搏一搏,说不定就拿奖了。
查看更多内容,欢迎访问天池技术圈官方地址:数据洞察创新挑战赛之智能运维赛参赛攻略--皮卡丘的皮卡_天池技术圈-阿里云天池
这篇关于数据洞察创新挑战赛之智能运维赛参赛攻略--皮卡丘的皮卡的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






