本文主要是介绍kafka大数据采集技术实验(未完待续),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Kafka下载安装
- 下载地址:https://link.zhihu.com/?target=https%3A//kafka.apache.org/downloads
- 解压
- 启动zookeeper
bin/zookeeper-server-start.sh -daemon config/zookeeper.properties
需要注意的是 : " c o n f i g / z o o k e e p e r . p r o p e r t i e s " 目录和 " / c o n f i g / z o o k e e p e r . p r o p e r t i e s " 目录是不同的 . 前者指当前目录中 c o n f i g 目录下的 z o o k e e p e r . p r o p e r t i e s 文件, 后者代表根目录中 c o n f i g 目录下的 z o o k e e p e r . p r o p e r t i e s 文件。 \color{red}需要注意的是:\\ "config/zookeeper.properties"目录和 "/config/zookeeper.properties"目录是不同的.\\ 前者指当前目录中config目录下的zookeeper.properties文件,\\ 后者代表根目录中config目录下的zookeeper.properties文件。 需要注意的是:"config/zookeeper.properties"目录和"/config/zookeeper.properties"目录是不同的.前者指当前目录中config目录下的zookeeper.properties文件,后者代表根目录中config目录下的zookeeper.properties文件。
若启动不成功,需要将zookeeper.properties中的admin.EnableServer=false修改为admin.EnableServer=true
- 启动kafka
bin/kafka-server-start.sh config/sever.properties
- 创建topic
kafka-topics.sh --create --zookeeper cluster1:9092,cluster2: 9092,cluster3: 9092--replication-factor 3 --partitions 1 --topic ljg
若发生错误:”zookeeper is not a recognized option”则将参数换成“—BOOTSTRAP-SERVER”,即:
./bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic codesheep
- 创建生产者
kafka-console-producer.sh --broker-list cluster1:9092 --topic ljg
或者:
./bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic ljg
- 创建消费者
./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic ljg
此时生产者即可进入等待输入,并将消息发送给消费者。
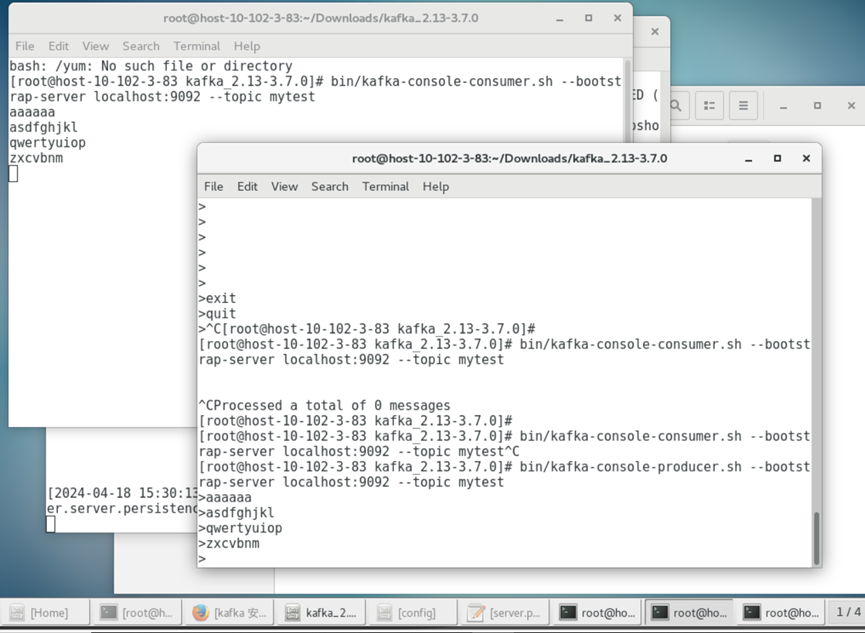
2181端口用于管理Kafka集群的元数据信息,包括Kafka的配置信息、分区信息、消费者信息等。而9092端口是Kafka Broker的默认端口,用于接收和处理生产者和消费者的消息,以及进行数据的存储和传输。
参考链接:https://www.cnblogs.com/anquing/p/14523046.html
这篇关于kafka大数据采集技术实验(未完待续)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




