本文主要是介绍yolov8自带的P2层如何开启,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
YOLOv8模型
简述YOLOv8不同size模型简述
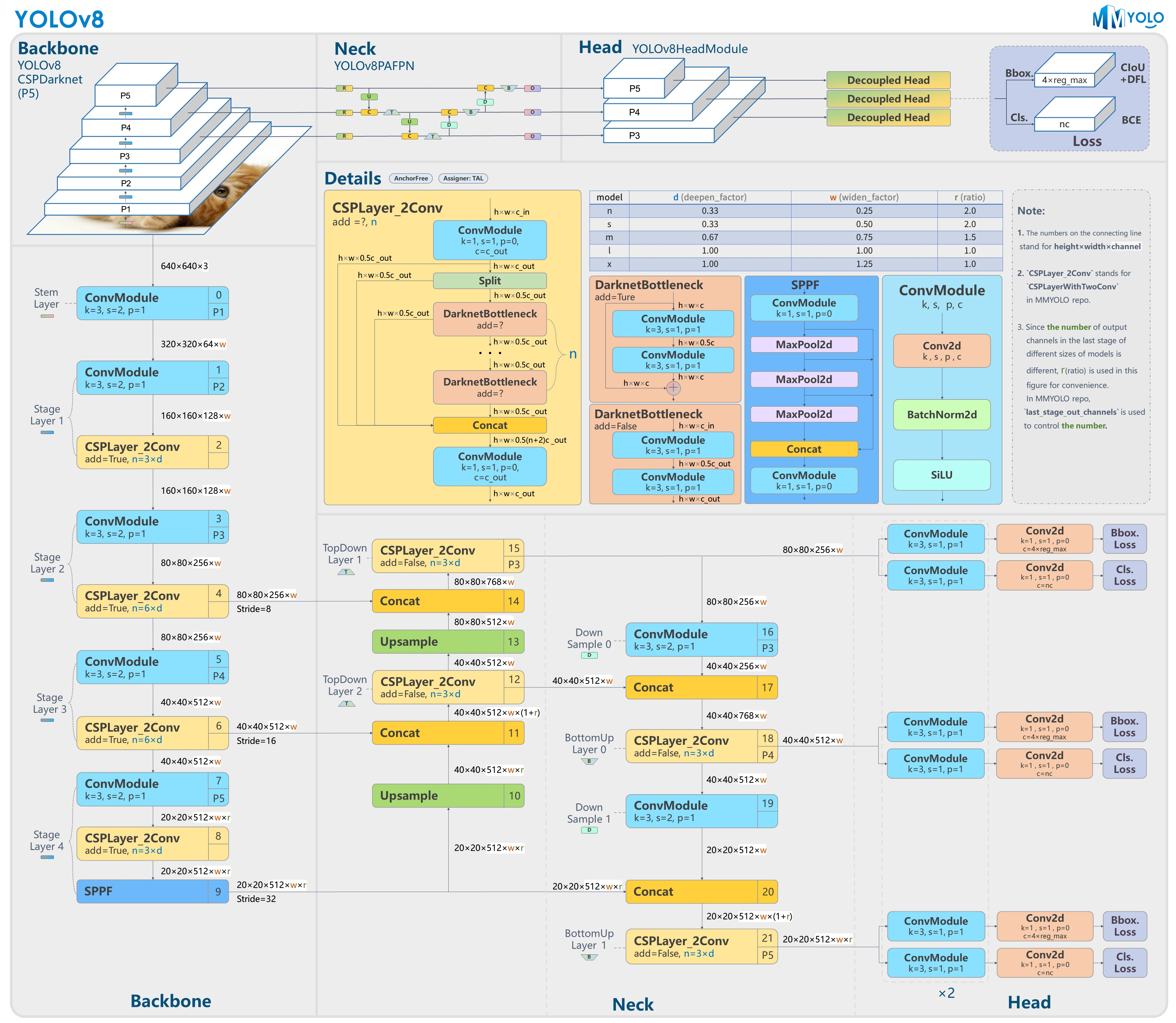
在最开始的YOLOv8提供的不同size的版本,包括n、s、m、l、x(模型规模依次增大,通过depth, width, max_channels控制大小),这些都是通过P3、P4和P5提取图片特征;
正常的YOLOv8对象检测模型输出层是P3、P4、P5三个输出层,为了提升对小目标的检测能力,新版本的yolov8 已经包含了P2层(P2层做的卷积次数少,特征图的尺寸(分辨率)较大,更加利于小目标识别),有四个输出层。Backbone部分的结果没有改变,但是Neck跟Head部分模型结构做了调整。这就是为什么v8模型yaml文件里面(GitHub地址)有p2这个模型;
新增加的这个P6,是为了引入更多的参数量,多卷积了一层,是给xlarge那个参数量准备的,属于专门适用于高分辨图片(图片尺寸很大,有大量可挖掘的信息)的版本。
- model=yolov8n.ymal 使用正常版本- model=yolov8n-p2.ymal 小目标检测版本- model=yolov8n-p6.ymal 高分辨率版本
模型结构分析
现阶段YOLO目标检测模型主要分为输入端、Backbone、Neck和Prediction四个部分,其各部分作用为:
- 输入端:缩放图片尺寸数据、适应模型训练;
- Backbone:模型主网络,通过卷积层数的增加,提取P1-P5不同感受野的
feature map,依次感受野逐渐增加; - Neck:呈现FPN和PAN结构,其中
FPN (feature pyramid networks):特征金字塔网络,采用多尺度来对不同size的目标进行检测;PAN:自底向上的特征金字塔。这样结合操作,FPN层自顶向下传达强语义特征,而特征金字塔则自底向上传达强定位特征,两两联手,从不同的主干层对不同的检测层进行特征聚合。 - Prediction:为model框架中的Head头,用于最终的预测输出,
P3 -> P4 -> P5过程中,感受野是增大的,所以依次预测目标为小 -> 中 -> 大。
输入端
常规做法
在常用的目标检测算法中,不同的图片长宽都不相同,因此常用的方式是将原始图片统一缩放到一个标准尺寸,再送入检测网络中。比如YOLO算法中常用416×416,608×608等尺寸,比如对下面800*600的图像进行变换。

YOLOv8做法
作者认为,在项目实际使用时,很多图片的长宽比不同。
因此缩放填充后,两端的黑边大小都不同,而如果填充的比较多,则存在信息冗余,影响推理速度。因此在代码中datasets.py的letterbox函数中进行了修改,对原始图像自适应的添加最少的黑边。
- 第一步:计算缩放比例

作者采用长边作为缩放因子:得到缩放因子0.52。
- 第二步:计算缩放后尺寸

原始图片都乘以缩放因子0.52得到了长宽尺寸。
- 第三步:计算填充数值

由于模型需要下采样5次,将图片特征缩放至1/2x2x2x2x2 ,即1 / 32,所以输入图像尺寸必须为32的整数倍,因此通过取余的方式得到填充数,除以2得到结果。
backbone:
ConvModule
- 模型的最小组件通过
Conv2d + BatchNorm2d + SiLU组成。 - 其中
Conv2d为2维CNN,用于提取图像空间特征。 BatchNorm2d为在channel维度上的数据归一化操作,卷积层之后总会添加BatchNorm2d进行- 数据的归一化处理,这使得数据在进行激活函数之前不会因为数据过大而导致网络性能的不稳定。- SiLU:激活函数,用于提高模型的非线性表达能力。

DarknetBottleneck
- 包含add=True、add=False两种类型
- add=True部分为resnet结构,可以更利用网络加深,作为CSPLayer_2Conv结构的组件用在backbone中,
- add=False部分没有resent结构,作为CSPLayer_2Conv结构的组件用在neck部分。

- CSPLayer_2Conv:现在经常称作C2f结构,对标的是yolov5的C3结构。在backbone中结合ConvModule构成主网络。让YOLOv8可以在保证轻量化的同时获得更加丰富的梯度流信息。

其他基础操作:
- (1) Split:在通道维度,将数据一分为二。
- (2) Concat:张量拼接,会扩充两个张量的维度,例如26×26×256和26×26×512两个张量拼接,结果是26×26×768。Concat和cfg文件中的route功能一样。
- (3) Add:张量相加,张量直接相加,不会扩充维度,例如104×104×128和104×104×128相加,结果还是104×104×128。add和cfg文件中的shortcut功能一样。
SPPF:空间金字塔池化
- 在卷积神经网络中我们经常看到固定输入的设计,但是有的时候难以控制,何凯明的论文SPPNet中的SPP结构解决了该问题。后续在YOLO系列中也出现了SPP结构及改进的结构,但是作用与最初的SPP结构却是不同的。
- SPPNet
有了空间金字塔池化,输入图像就可以是任意尺寸了。不但允许任意比例关系,而且支持任意缩放尺度。 - SPP(Spatial Pyramid Pooling layer):空间金字塔池化,Yolov4中作者在SPP模块中,使用k={1×1,5×5,9×9,13×13}的最大池化的方式,再将不同尺度的特征图进行Concat操作。
- 注意:这里最大池化采用padding操作,移动的步长为1,比如13×13的输入特征图,使用5×5大小的池化核池化,padding=2,因此池化后的特征图仍然是13×13大小。
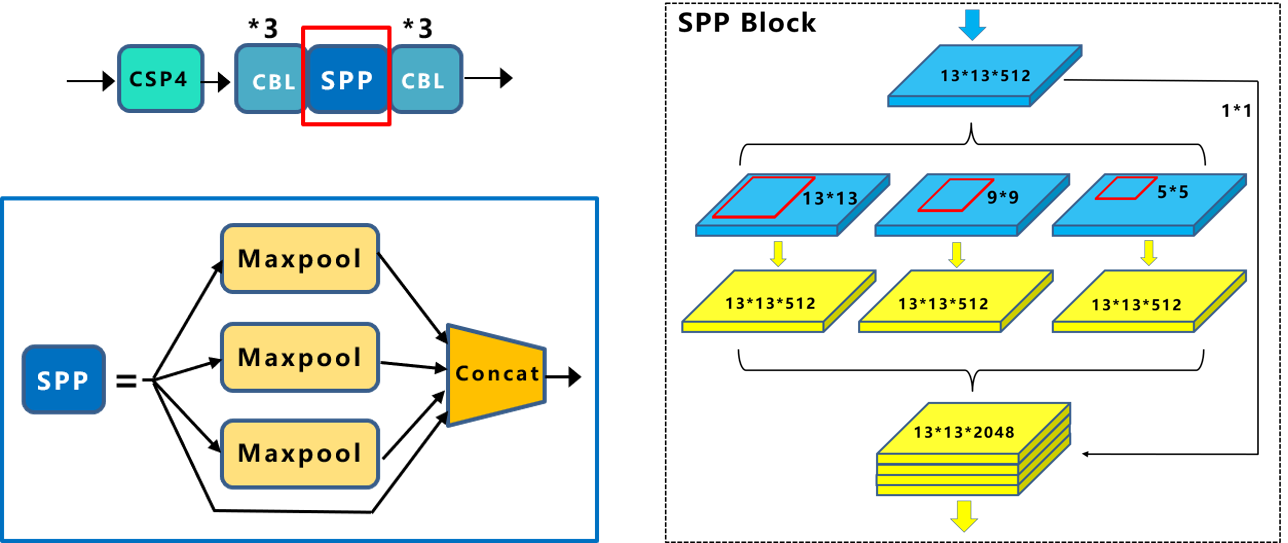
- 这里的SPP虽然也叫SPP,但是作用更多的是实现局部特征和全局特征的featherMap级别的融合。
- SPPF(Spatial Pyramid Pooling Fast):实现更快的SPP
Neck:
由Structure图可以看出,图片首先进入Backbone进行特征提取,再通过Neck网络,纵观Neck全局网络,形成了FPN(Feature pyramid network)网络,再通过了PAN(Path Aggregation Network)网络。

- PAN(Path Aggregation Network for Instance Segmentation):
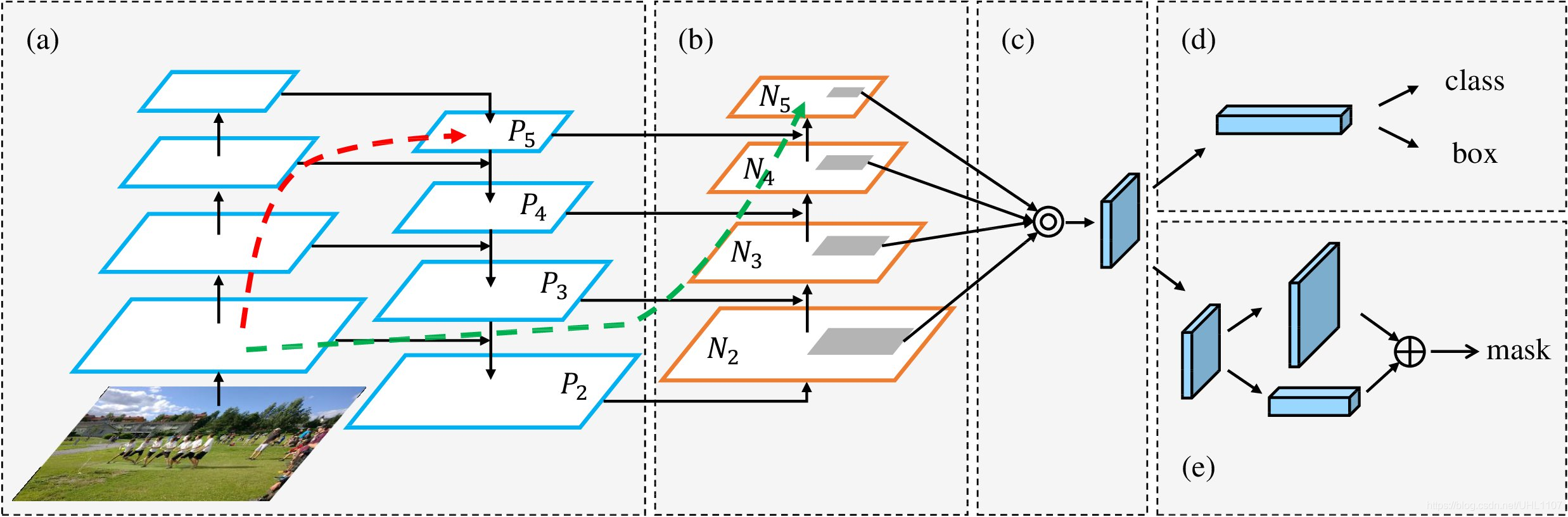
FPN是自顶向下,将高层的强语义特征传递下来。PAN就是在FPN的后面添加一个自底向上的金字塔,对FPN补充,将低层的强定位特征传递上去,FPN是自顶(小尺寸,卷积次数多得到的结果,语义信息丰富)向下(大尺寸,卷积次数少得到的结果),将高层的强语义特征传递下来,对整个金字塔进行增强,不过只增强了语义信息,对定位信息没有传递。PAN就是针对这一点,在FPN的后面添加一个自底(卷积次数少,大尺寸)向上(卷积次数多,小尺寸,语义信息丰富)的金字塔,对FPN补充,将低层的强定位特征传递上去,又被称之为“双塔战术“。
Prediction:
YOLOv8 的推理过程和 YOLOv5 几乎一样,唯一差别在于前面需要对 Distribution Focal Loss 中的积分表示 bbox 形式进行解码,变成常规的 4 维度 bbox(代表bounding box的坐标位置)。
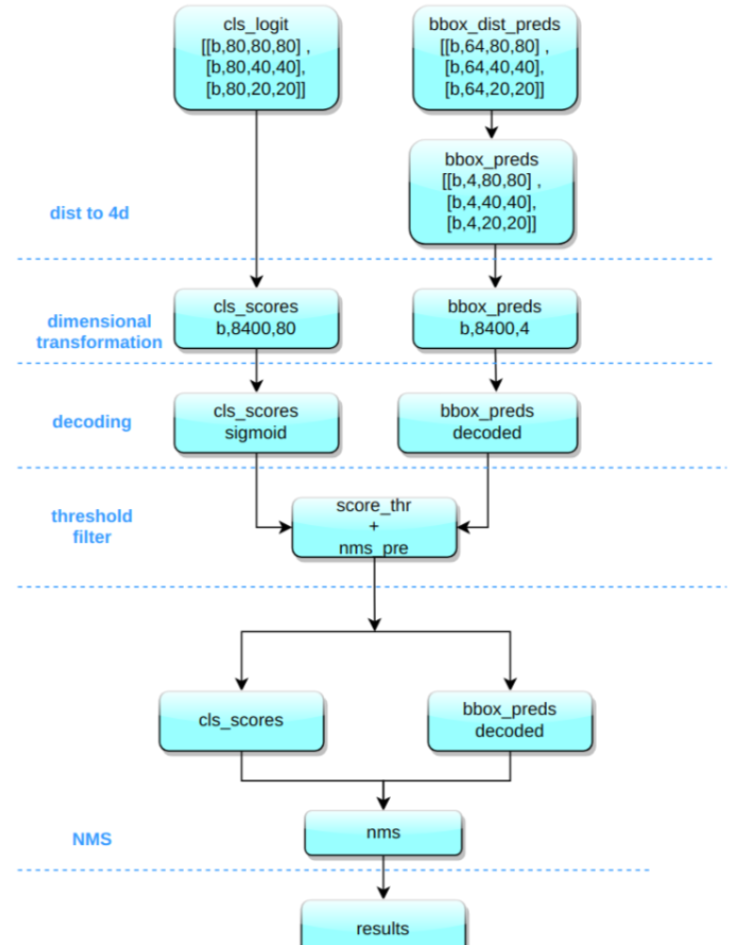
其推理和后处理过程为:
-
(1) bbox 积分形式转换为 4d bbox 格式
对 Head 输出的 bbox 分支进行转换,利用 Softmax 和 Conv 计算将积分形式转换为 4 维 bbox 格式 -
(2) 维度变换
YOLOv8 输出特征图尺度为 80x80、40x40 和 20x20 的三个特征图。Head 部分输出分类和回归共 6 个尺度的特征图。 将 3 个不同尺度的类别预测分支、bbox 预测分支进行拼接,并进行维度变换。为了后续方便处理,会将原先的通道维度置换到最后,类别预测分支 和 bbox 预测分支 shape 分别为 (b, 80x80+40x40+20x20, 80)=(b,8400,80),(b,8400,4)。 -
(3) 解码还原到原图尺度
分类预测分支进行 Sigmoid 计算,而 bbox 预测分支需要进行解码,还原为真实的原图解码后 xyxy 格式。 -
(4) 阈值过滤
遍历 batch 中的每张图,采用 score_thr 进行阈值过滤。在这过程中还需要考虑 multi_label 和 nms_pre,确保过滤后的检测框数目不会多于 nms_pre。 -
(5) 还原到原图尺度和 nms
基于前处理过程,将剩下的检测框还原到网络输出前的原图尺度,然后进行 nms 即可。最终输出的检测框不能多于 max_per_img。
这篇关于yolov8自带的P2层如何开启的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






