本文主要是介绍jstorm的cgroup资源隔离机制,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文研究一下jstorm使用cgroup做资源隔离的情况,github有文档:
https://github.com/alibaba/jstorm/wiki/%E8%B5%84%E6%BA%90%E7%A1%AC%E9%9A%94%E7%A6%BB
这个文档告诉你怎么开启cgroup,但对于不太了解cgroup和jstorm细节的同学可能更有兴趣看一下到底是怎么隔离的。
废话少说,你不是告诉我cgroup做资源隔离吗?你回答我两个问题:
1、什么是cgroup
2、jstorm怎么用cgroup做资源隔离,隔离哪些资源
首先回答第1个问题:
概念介绍我不想多说了,cgroup你可以认为是操作系统出面解决进程或者进程family资源限制使用的工具。
很多资源调度管理系统比如yarn,mesos等都会使用cgroup,那么cgroup怎么用?直接行动少BB
1)你得弄起来一个叫cgconfig的服务
el6版本的OS上一般都有,怎么安装啥的不在本文关心内容里,sudo service cgconfig start
2)拉起来cgconfig之后,你在根/下会看到一个目录叫cgroup
先别管啥意思,执行俩命令:
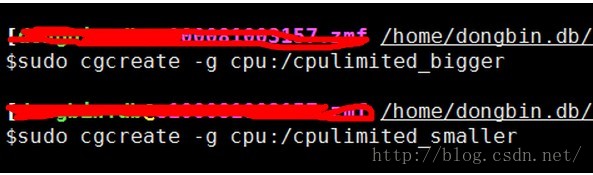
执行完,你会发现,多出来2个目录:

看下目录结构:
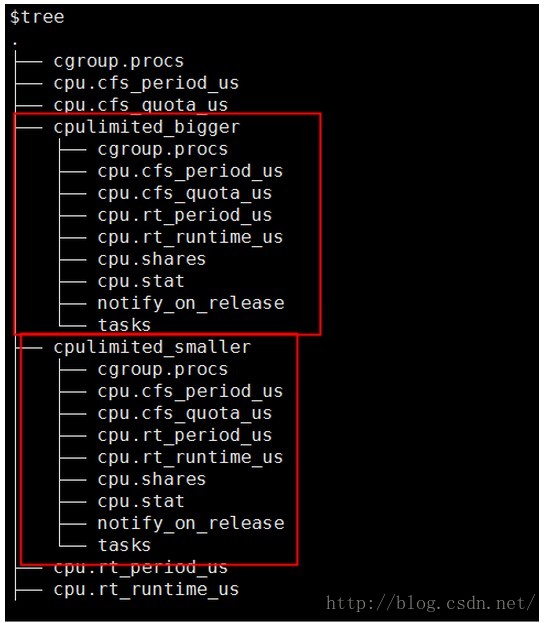
先不要管这些东西,接着往下看。
3)找一个吃cpu的程序:
http://pkgs.fedoraproject.org/repo/pkgs/mathomatic/mathomatic-16.0.5.tar.bz2/dd04913a98a5073b56f3bc78a01820f3/ 下载编译,解压,进入mathomatic-16.0.5/primes
make && sudo make install
这样就会把这个程序安装到/usr/local/bin下面。跑一下,走起
/usr/local/bin/matho-primes 0 9999999999 > /dev/null &
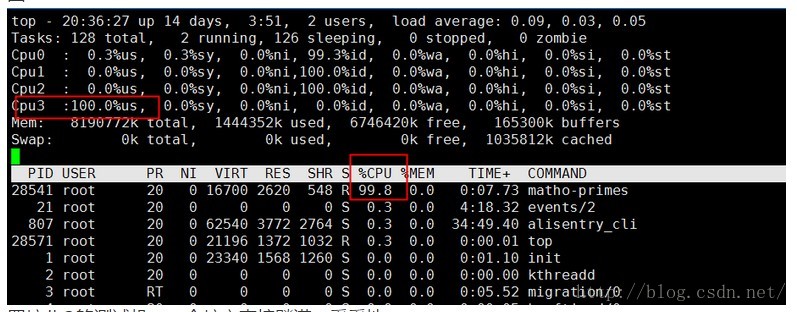
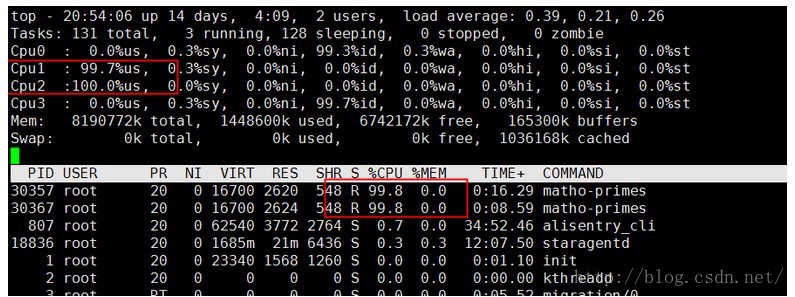
执行上面的命令,这个命令是找出0到9999999999之间的质数,且得算一会才能结束,直接上图:
四核八G的测试机,一个核心直接飚满,妥妥地。
4)让cgroup 发挥作用
上面我用cgcreate -g cpu:/xxxxx创建了2个目录,意思就是弄了2个分组,或者你可以理解成2个容器,其实都是逻辑上的概念,虚拟的东西,那么cgroup所谓隔离,其实就是对这种group的资源隔离,即分别对cpulimited_bigger和cpulimited_smaller这两个你任意起名的group进行限制。
怎么限制?
先介绍cpu限制的一种:我让两个分组按照一定比例使用整机的cpu资源:
sudo cgset -r cpu.shares=1024 cpulimited_bigger
sudo cgset -r cpu.shares=512 cpulimited_smaller
1024和512啥意思,上图:
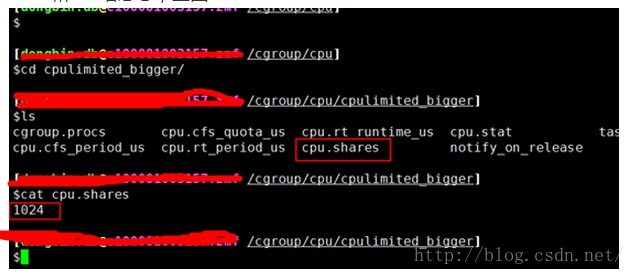
smaller分组

上面那两个命令就是把1024和512分别写到这俩文件里,比例就是2:1,意思是你俩group(容器)里的按照1:2使用我机器上的cpu资源,没有上限。
要让你的程序被cgroup管理,也就是要把你的进程加入到cgroup管理的分组中,方法很简单,就是你程序启动命令前加一些前缀:
sudo cgexec -g cpu:cpulimited_bigger /usr/local/bin/matho-primes 0 9999999999 > /dev/null &
sudo cgexec -g cpu:cpulimited_smaller /usr/local/bin/matho-primes 0 9999999999 > /dev/null &
上面的命令就是起2个一样的程序,分别加到bigger和smaller分组里,加到这里其实就是把这个进程的pid加到对应分组下面的tasks文件里
/cgroup/cpu/cpulimited_bigger/tasks。
这时候再看cpu使用率:
怎么都是用了一个核心,都是100%,你不是说2:1嘛?
注意:这是四核八G,你还没跑满机器呢,这个作业最大也就用1个核心,当机器资源宽裕的时候,是不收限制的,你用多少都行,但是当你2个组把机器cpu打满了呢?
很简单,我们把更多的进程加到其中一个group,另一个就1个,如果按照2:1的配置,那么4核心,应该是1.3 : 2.6的关系,即配比小的smaller理论上会打满130%,但是作业特点就到100,那么smaller分组的那一个进程应该还是100%,而另一个起超过3个进程都应该会平分2.6个核心
直接上图:
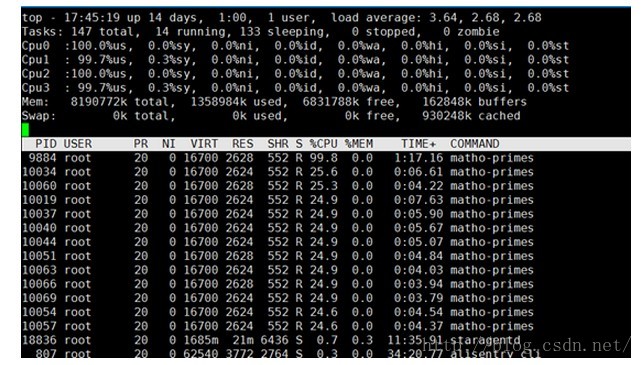
基本符合预期!!!你自己如果想做的话,注意下进程pid,因为这个程序并不是一直运行的,找质数一定时间内进程会退出的。别把两个组的进程搞混了。
好,到这里基本上你了解了cgroup md到底怎么用的,无非就是
1、set 一下每个分组的cpu.share 比例
2、使用cgexec -g cpu:groupxxxx来启动你的进程
那么我们其实还可以观察到:
好像cgroup给每个进程起了一个couple的进程,本身不消耗啥资源,但是会随着真实作业进程退出而退出。

上面提到了使用cpu.share来给容器按比例分cpu,并且你用的测试作业是个100%就到顶的作业,如果我在每个分组起一个吃cpu特别狠的呢,把整个机器的cpu水位打得特别高怎么办?即有没有绝对值的限制?
必须有啊:
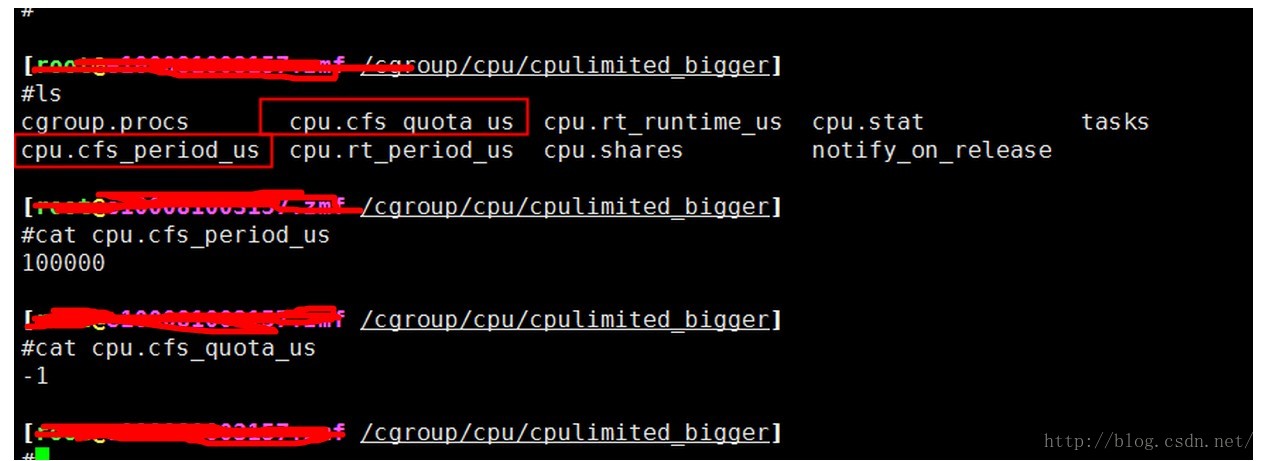
cpu.cfs_period_us 你可以理解成采样周期
cpu.cfs_quota_us 你可以理解成采样周期内消耗的时间
啥意思,其实cpu使用率,不就是在一段时间内,整个cpu给你服务了多久吗?所以前面那个就是我统计的采样时间,后面的quota就是cpu给你服务的时间,这个就是绝对值的限制。
那么这个quota可以是-1,就是代表没有限制,可以比采样值大,因为大多数服务器都是多核心的,在有多核的情况下,比如24核,默认采样周期是100ms,那么quota 理论上可以是0-2400ms之间。
了解了cgroup怎么用,有了直观的感受之后,我们再来分析一下jstorm怎么做的,即回答前面第二个问题。
我们先来简单梳理一下jstorm作业的调度过程
作业提交上来之后,系统会根据作业的配置的worker数以及worker的堆内存大小,cpu核使用数(默认是1,default.yaml也没有另外配置)等信息,找到“合适”的槽位,并将这种信息放到assignment里发布到zk上,supervisor周期扫描zk,过滤出属于自己的任务,然后启动worker。

然后jstorm配置了一个cgroup的总开关
默认是关闭的,storm.yaml里你根据需要自己配置,OS版本el6以上的支持,el5可能需要自己选装cgconfig。

当supervisor启动worker的时候,其实是拼接出来一个java -server xxxx这样的命令,然后调用一个线程(异步)或者直接执行nohup java -server xxx &这种命令行完成worker启动的,那么如果你开启了cgroup,就会在这个命令前加上cgexec -g cpu:groupxxxx来启动worker
即在cpu子系统下创建一个叫jstorm的分组
然后这个分组下面还可以创建子分组,即worker分组
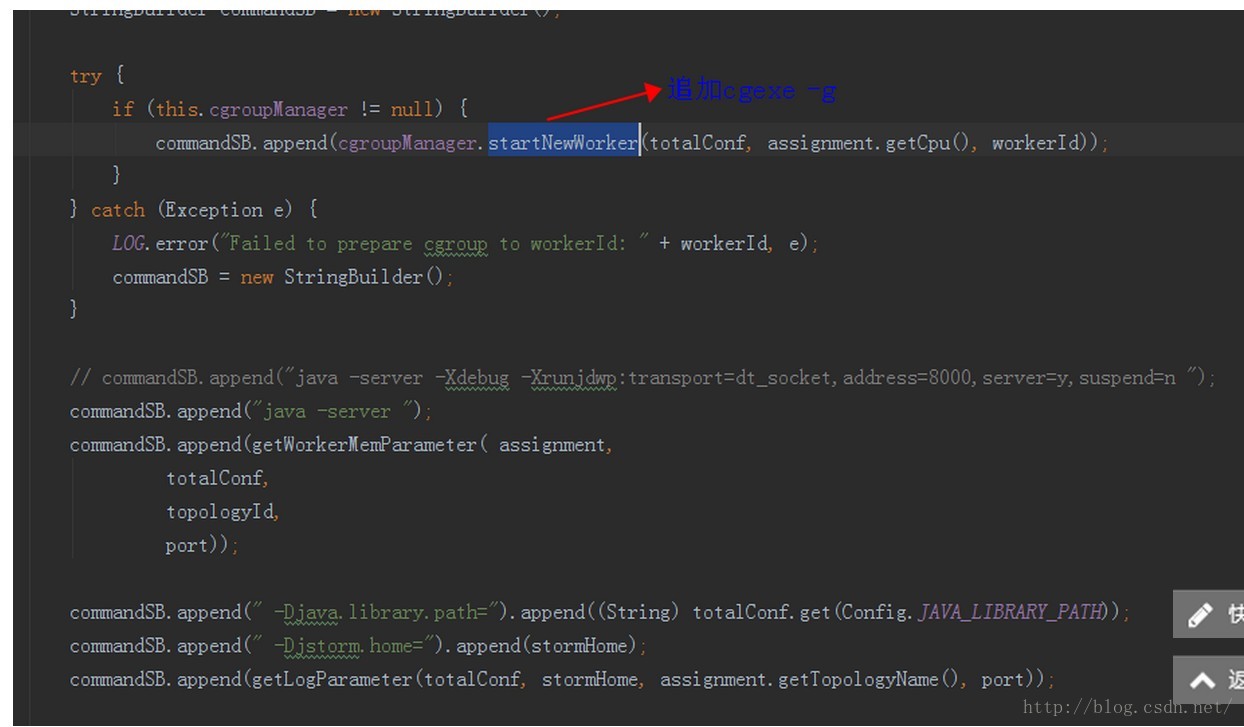
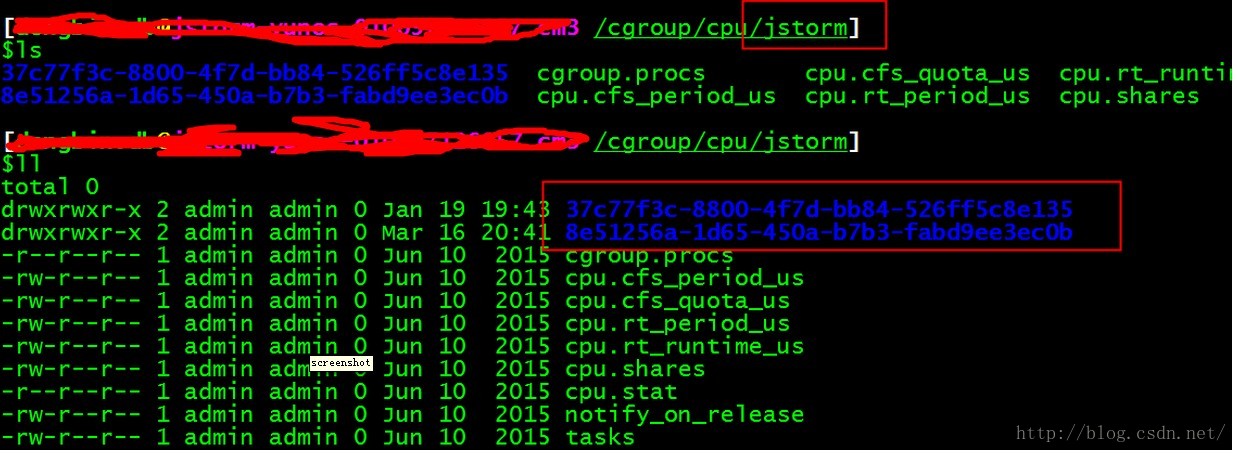

很容易理解jstorm分组代表一个大容器,每个worker又是一个个小容器,相当于cgroup的这种分组是可以嵌套的,当然,quota以及权重都要满足父子总和的关系,即子容器的quota和不超过父容器的quota .
可以看到jstorm这个父容器的quota是不设限制的:
而每个worker的绝对值限制都是100ms采样周期内,上限不超过300ms,即一个worker最多用满3个核心的cpu


这个在哪里设置的?
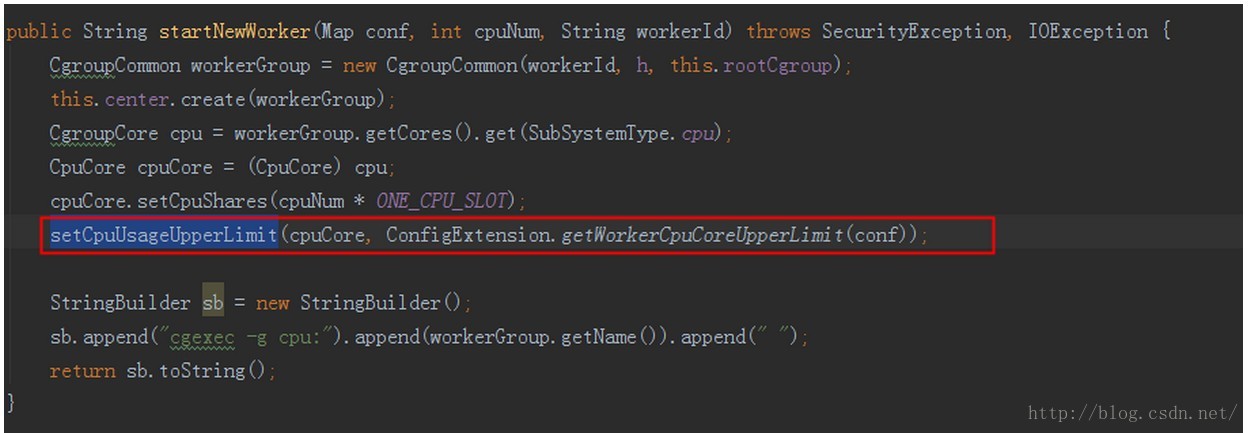
虽然代码里缺省是1,但是default.yaml里设置的是3.用户一般不去更改这个配置。
(说到这里,jstorm是不是应该对某些配置做下限制,不允许用户更改?)

到这里我们基本上可以摸清jstorm是如何利用cgroup做资源限制的,这个资源就是cpu,并没有对内存和其它资源做限制。前面作业assignment里给的cpu值是1,是什么意思?
其实就是权重,基数都是1024,如果你的这个worker cpu是2,那么满载情况下,人家权重都是1,你却可以最高使用别的worker2倍的cpu。
配置参数是哪个?
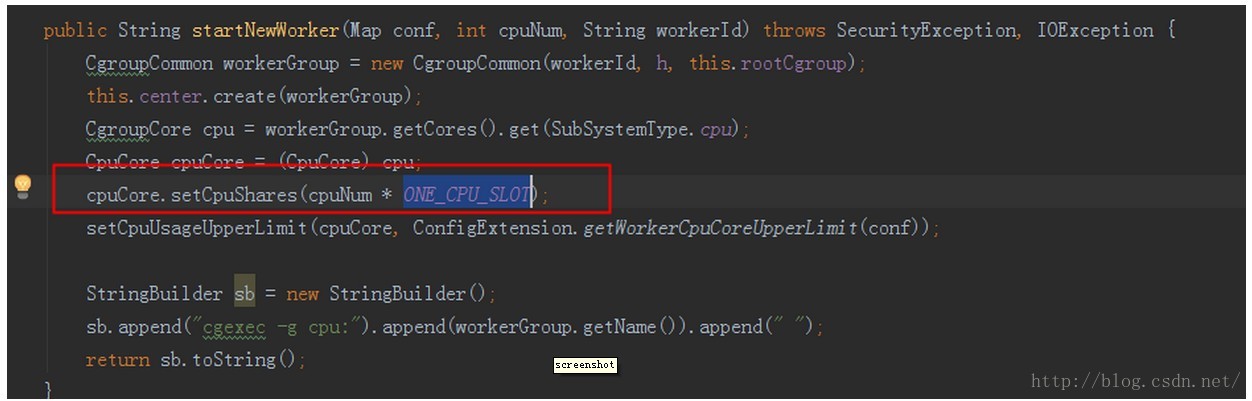

小结一下:
1、jstorm 用cgroup的完全公平调度算法对一台机器(能装cgroup的)上的worker做了cpu的限制,并且使用的是cpu子系统,而不是cpuset(这个可以绑定worker到某一个核心上,做更复杂的限制)
2、提醒注意的是一个worker里面可能有多个task(线程级别),但是这个worker一定只服务一个作业,即这些task可定都属于一个topology,这么做一个是程序设计简单,另一个多个作业的task跑同一个进程里,互相干扰,也不好解决资源隔离得问题
3、基于上面2点,其实jstorm做到了worker级别的cpu隔离,但是并不是绝对隔离,因为能否隔离至少有以下几个条件共同约束。
a、supervisor最多运行多少个worker
b、单worker绝对值限制
c、相对比例
比如32核机器上调度一个吃500%cpu的作业,cpu权重是1,假设内存足够大,计算后的拉起槽位就是32,同时单个worker权重又比较大比如10:1,同时quota设置成10(最大),那么可想而知,肯定分配不到32个槽位,机器cpu就打满了,机器基本hang死状态,其余worker状况可想而知。
前段时间,在祥总的带领下,开发了一个周期检查机器资源水位线,动态调整可用槽位数的功能可以在一定程度上避免这种问题。
如果上了docker集群,资源隔离会变成什么方式?
首先docker集群部署jstorm是这样的:
物理集群1虚4或者1虚8做出来很多的容器,每个容器带有独立的ip,然后每个容器起一个supervisor,即相同的物理机资源,弄出来更多的supervisor,或者说把少量的高配机型,换成了很多的低配机型,集群总的槽位不变。
docker容器本身利用lxc,cgroup.等资源隔离手段做出来的轻量虚拟化的东西,你看到的虽然也是独立的os环境,但是它里面能不能装cgroup?
如果不能装cgroup,那么相当于把jstorm目前的worker之前的cpu资源隔离砍掉了,只做了supervisor级别的隔离,而当前的物理机部署supervisor本来就是物理隔离!
如果我们单物理机创建更多的容器,假设一个容器起一个supervisor,1个worker,倒是可以提供很强的资源隔离能力,但是根据性能测试报告,这样性能会很差,同时浪费大量的ip资源。
如果修改jstorm的调度机制呢?即一个supervisor(docker容器)里只跑同一个作业的worker呢?显然会出现很多的槽位碎片,并且容灾能力也会减弱。
这篇关于jstorm的cgroup资源隔离机制的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




