本文主要是介绍【Linux】详解进程通信中信号量的本质同步和互斥的概念临界资源和临界区的概念,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、同步和互斥的概念
1.1、同步
访问资源在安全的前提下,具有一定的顺序性,就叫做同步。在多道程序系统中,由于资源有限,进程或线程之间可能产生冲突。同步机制就是为了解决这些冲突,保证进程或线程之间能够按照既定的顺序访问共享资源。同步机制有助于避免竞态条件和死锁(deadlock)等问题,确保系统的稳定性和可靠性。
1.2、互斥
在访问一部分共享资源的时候,任何时刻只有我一个人访问,就叫做互斥。当某一进程或线程正在访问某临界区(即共享资源)时,就不允许其他进程或线程进入,这样可以避免数据冲突和不一致。互斥机制有助于保证同一时间只有一个线程或进程能够访问被保护的临界区,从而确保数据的一致性和完整性。
二、临界资源和临界区的概念
2.1、临界资源
被保护起来的,任何时刻只允许一个执行访问的公共资源就叫做临界资源。这类资源在某一时刻只能有一个进程或线程占用,如果多个进程或线程试图同时访问临界资源,可能会引发数据冲突或不一致。物理设备如打印机、输入机等都属于临界资源。
2.2、临界区
访问临界资源的代码,我们叫做临界区。临界区的访问需要遵循一定的调度原则,如空闲让进、忙则等待等,以确保资源的正确和高效利用。所谓的保护公共资源(临界资源)的本质就是程序员保护临界区。
三、认识信号量
3.1、信号量的本质
信号量本质是一个计数器,是一个描述临界资源数量的计数器。进程要访问临界资源的时候,必须先申请信号量,申请信号量成功了才能继续往下走,否则就要进行阻塞或挂起等待。信号量的值表示了可用资源的数量或等待访问该资源的进程/线程数。当进程或线程需要访问共享资源时,会先检查信号量的值。如果信号量的值大于0,表示还有可用的资源,进程或线程可以继续执行并访问资源,同时信号量的值会减1。如果信号量的值为0,表示所有资源都已被占用,进程或线程需要等待,直到有其他进程或线程释放资源并将信号量的值增加。访问完临界资源进程要释放信号量,即信号量加1。当信号量的初始值为1时,就实现了互斥的功能。
3.2、普通的整形变量无法实现信号量的效果
原因有两个:
- 信号量本身就是共享资源,本身就是要被多个进程或线程共同可以看到的,但是一个普通整形变量无法同时被多个进程看到,就算是父子进程,当要改变进程数据时都要发生写时拷贝,因此无法让多个进程看到同一个变量。
- 对整形变量做++和--操作,这个操作不是原子的。
这里又设计一个概念叫原子性。
3.3、原子性的概念
在操作系统中,原子性是指一个操作或一系列操作是不可中断的,要么全部执行成功,要么全部不执行,中间不能被其他进程或线程干扰。换句话说,原子操作是不可分割的,具有“同生共死”的特性,即要么完全执行,要么完全不执行,没有中间状态。上面的对一个整形做++或--操作实际上是先将内存中的一个整形变量的值先拷贝到CPU的寄存器中,在寄存器中对该变量做++操作然后再将该变量拷贝会内存当中,我们也可以看到,这中间其实经历了三个过程,换句话说,++或--操作不具备原子性。原子性在并发编程中尤为重要,特别是在共享资源的读写操作中。当多个线程或进程同时访问和修改共享资源时,如果操作不是原子的,就可能导致数据不一致的问题。原子性确保了即使在多线程环境下,一个操作一旦开始就不会被其他线程干扰,从而保证了数据的一致性。
3.4、信号量操作的接口
3.4.1、获取信号量
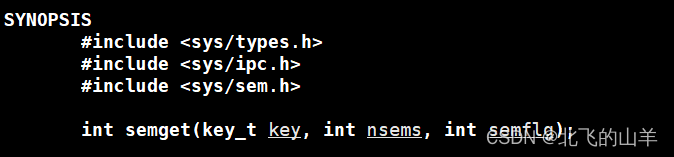
key就类似于共享内存中使用ftok函数产生的key,nsems表示要产生几个信号量,semflg表示如何创建,与共享内存的第三个参数同理,可参考本人上一篇博客,返回值为该信号量集标识符,这是通过semget函数创建或获取信号量集时返回的IPC标识符。
3.4.2、控制/删除信号量
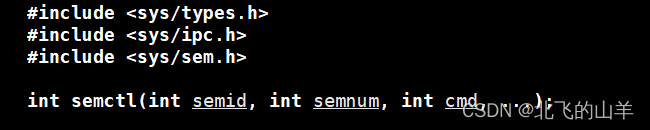
semid表示该信号量集标识符。semnum表示信号量的编号,用于指定信号量集中的某个特定的信号量,第一个信号量的编号是0。cmd表示需要执行的命令,IPC_RMID为删除命令。
3.4.3、对信号量进行PV操作
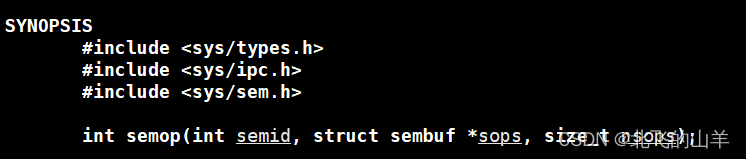
sops指向存储信号操作结构的数组指针。在这个数组中的每个sembuf结构体对应一个特定信号的操作。 这是sops数组中sembuf结构的数量。
这篇关于【Linux】详解进程通信中信号量的本质同步和互斥的概念临界资源和临界区的概念的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




