本文主要是介绍torch.gather用法详解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
torch.gather是PyTorch中的一个函数,用于从源张量中按照指定的索引张量来收集数据。
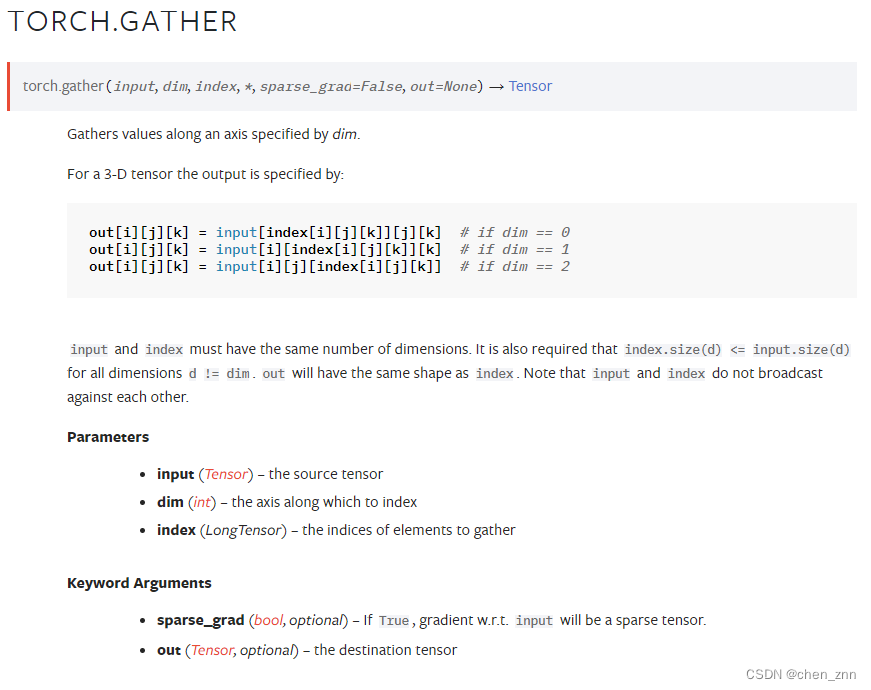
基本语法如下,
torch.gather(input, dim, index, *, sparse_grad=False, out=None) → Tensor- input:输入源张量
- dim:要收集数据的维度
- index:索引
- sparse_grad:如果为True,则gather()在反向传播时会返回稀疏梯度
- out:输出张量,形状与index相同
用法讲解
假设有以下输入张量x,
x = torch.tensor([[[ 1, 2],[ 3, 4]],[[ 5, 6],[ 7, 8]],[[ 9, 10],[11, 12]]
])假设有以下索引index,
index = torch.tensor([[[0, 1],[1, 0]],[[1, 0],[0, 1]],[[0, 1],[1, 0]]
])index的索引及里面的元素的对应关系如下,
index[0, 0, 0] = 0
index[0, 0, 1] = 1
index[0, 1, 0] = 1
index[0, 1, 1] = 0
index[1, 0, 0] = 1
index[1, 0, 1] = 0
index[1, 1, 0] = 0
index[1, 1, 1] = 1
index[2, 0, 0] = 0
index[2, 0, 1] = 1
index[2, 1, 0] = 1
index[2, 1, 1] = 0接下来,有3种情况出现,分别是dim=0、dim=1、dim=2
dim=0
拿index里的元素值去替换对应索引中第1个维度的数值,得到新索引,
(索引, 索引对应的元素) -> 新索引
[0, 0, 0], 0 -> [0, 0, 0]
[0, 0, 1], 1 -> [1, 0, 1]
[0, 1, 0], 1 -> [1, 1, 0]
[0, 1, 1], 0 -> [0, 1, 1]
[1, 0, 0], 1 -> [1, 0, 0]
[1, 0, 1], 0 -> [0, 0, 1]
[1, 1, 0], 0 -> [0, 1, 0]
[1, 1, 1], 1 -> [1, 1, 1]
[2, 0, 0], 0 -> [0, 0, 0]
[2, 0, 1], 1 -> [1, 0, 1]
[2, 1, 0], 1 -> [1, 1, 0]
[2, 1, 1], 0 -> [0, 1, 1]有了新索引后,便可根据新索引从输入张量中获取输出张量,
result = torch.gather(x, 0, index)
“”“
预测值:
result = [[[x[0, 0, 0], x[1, 0, 1]],[x[1, 1, 0], x[0, 1, 1]],[[x[1, 0, 0], x[0, 0, 1],[x[0, 1, 0], x[1, 1, 1]],[[x[0, 0, 0], x[1, 0, 1], [x[1, 1, 0], x[0, 1, 1]]]]=[[[1, 6],[7, 4]],[[5, 2],[3, 8]],[[1, 6],[7, 4]]]
”“”打印输出张量,
print(result)
"""
实际值:
tensor([[[1, 6],[7, 4]],[[5, 2],[3, 8]],[[1, 6],[7, 4]]])
"""dim=1
拿index里的元素值去替换对应索引中第2个维度的数值,得到新索引,
(索引, 索引对应的元素) -> 新索引
[0, 0, 0], 0 -> [0, 0, 0]
[0, 0, 1], 1 -> [0, 1, 1]
[0, 1, 0], 1 -> [0, 1, 0]
[0, 1, 1], 0 -> [0, 0, 1]
[1, 0, 0], 1 -> [1, 1, 0]
[1, 0, 1], 0 -> [1, 0, 1]
[1, 1, 0], 0 -> [1, 0, 0]
[1, 1, 1], 1 -> [1, 1, 1]
[2, 0, 0], 0 -> [2, 0, 0]
[2, 0, 1], 1 -> [2, 1, 1]
[2, 1, 0], 1 -> [2, 1, 0]
[2, 1, 1], 0 -> [2, 0, 1]有了新索引后,便可根据新索引从输入张量中获取输出张量,
result = torch.gather(x, 0, index)
“”“
预测值:
result = [[[x[0, 0, 0], x[0, 1, 1]],[x[0, 1, 0], x[0, 0, 1]],[[x[1, 1, 0], x[1, 0, 1],[x[1, 0, 0], x[1, 1, 1]],[[x[2, 0, 0], x[2, 1, 1], [x[2, 1, 0], x[2, 0, 1]]]]=[[[1, 4],[3, 2]],[[7, 6],[5, 8]],[[9, 12],[11, 10]]]
”“”打印输出张量,
print(result)
"""
实际值:
tensor([[[ 1, 4],[ 3, 2]],[[ 7, 6],[ 5, 8]],[[ 9, 12],[11, 10]]])
"""dim=3
拿index里的元素值去替换对应索引中第3个维度的数值,得到新索引,
(索引, 索引对应的元素) -> 新索引
[0, 0, 0], 0 -> [0, 0, 0]
[0, 0, 1], 1 -> [0, 0, 1]
[0, 1, 0], 1 -> [0, 1, 1]
[0, 1, 1], 0 -> [0, 1, 0]
[1, 0, 0], 1 -> [1, 0, 1]
[1, 0, 1], 0 -> [1, 0, 0]
[1, 1, 0], 0 -> [1, 1, 0]
[1, 1, 1], 1 -> [1, 1, 1]
[2, 0, 0], 0 -> [2, 0, 0]
[2, 0, 1], 1 -> [2, 0, 1]
[2, 1, 0], 1 -> [2, 1, 1]
[2, 1, 1], 0 -> [2, 1, 0]有了新索引后,便可根据新索引从输入张量中获取输出张量,
result = torch.gather(x, 0, index)
“”“
预测值:
result = [[[x[0, 0, 0], x[0, 0, 1]],[x[0, 1, 1], x[0, 1, 0]],[[x[1, 0, 1], x[1, 0, 0],[x[1, 1, 0], x[1, 1, 1]],[[x[2, 0, 0], x[2, 0, 1], [x[2, 1, 1], x[2, 1, 0]]]]=[[[1, 2],[4, 3]],[[6, 5],[7, 8]],[[9, 10],[12, 11]]]
”“”打印输出张量,
print(result)
"""
实际值:
tensor([[[ 1, 2],[ 4, 3]],[[ 6, 5],[ 7, 8]],[[ 9, 10],[12, 11]]])
"""这篇关于torch.gather用法详解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





