本文主要是介绍Maxwell安装使用和简单案例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
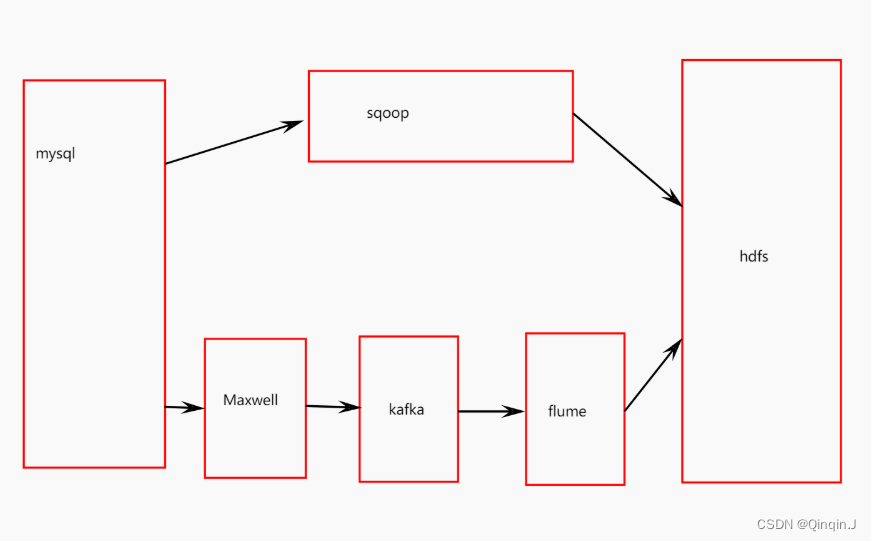
一、解压
cd /opt/software/
tar -zxvf maxwell-1.29.2.tar.gz -C /opt/module/
cd /opt/module/二、MySQL 环境准备
1、修改 mysql 的配置文件
修改 mysql 的配置文件,开启 MySQL Binlog 设置
vi /etc/my.cnf添加以下内容
server_id=1
log-bin=mysql-bin
binlog_format=row
#binlog-do-db=test_maxwell
#(可添加可不添加)
#添加binlog的多个库(用于区分是不是自己的库)
#binlog-do-db=库名解释
server_id=1:指定了MySQL服务器实例的唯一标识符,用于复制和识别不同的服务器。
log-bin=mysql-bin:启用二进制日志(binary log),并指定了二进制日志文件的名称为mysql-bin。二进制日志包含了对数据库所做更改的详细记录,可用于数据复制和恢复等操作。
binlog_format=row:指定了二进制日志的格式为行级别(row-based)格式。在行级别格式中,二进制日志记录了实际被修改的行的内容。这种格式相对于其他格式(如语句级别或混合级别)更为详细和安全,因为它记录了实际数据的变化,而不仅仅是执行的SQL语句。
binlog-do-db=test:这个选项定义了需要记录到二进制日志的数据库名称。在这个例子中,只有名为test的数据库的更改会被记录到二进制日志中。这有助于减少二进制日志文件的大小和提高性能,因为不需要记录所有数据库的更改。
2、重启MySQL
#重启MySQL
systemctl restart mysqld
#关闭
systemctl stop mysqld
#查看
systemctl status mysqld登录查看是否修改完成
mysql -uroot -pPassword123$查看下列属性
show variables like '%binlog%';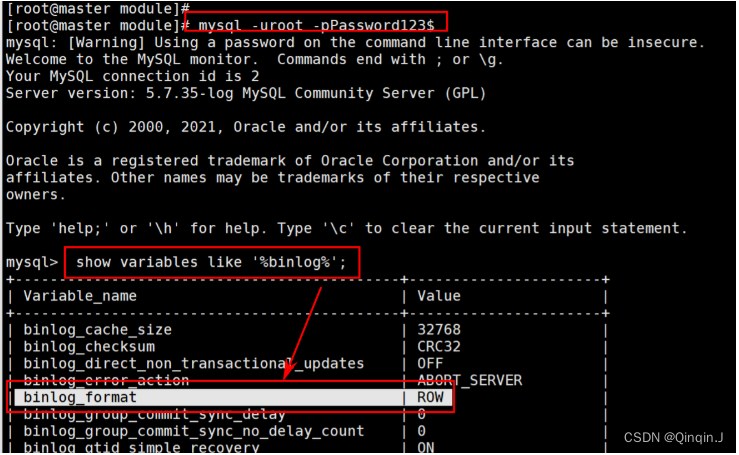
3、查看 MySQL 生成的 binlog 文件
进入/var/lib/mysql 目录,查看 MySQL 生成的 binlog 文件、
cd /var/lib/mysql 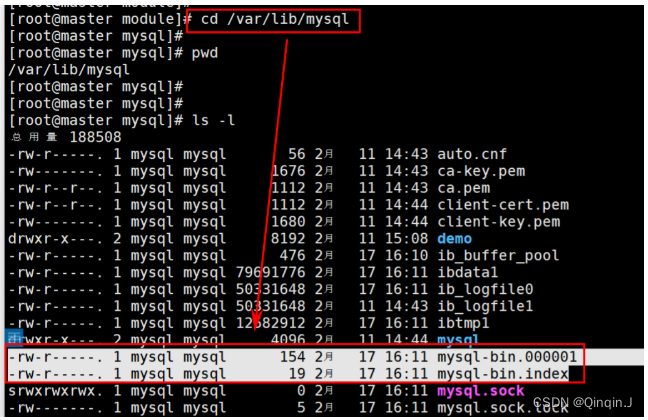
cat mysql-bin.index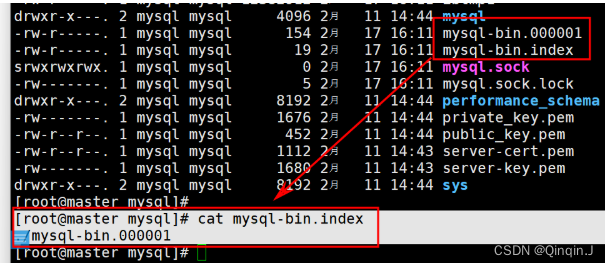
再次重启
systemctl restart mysqld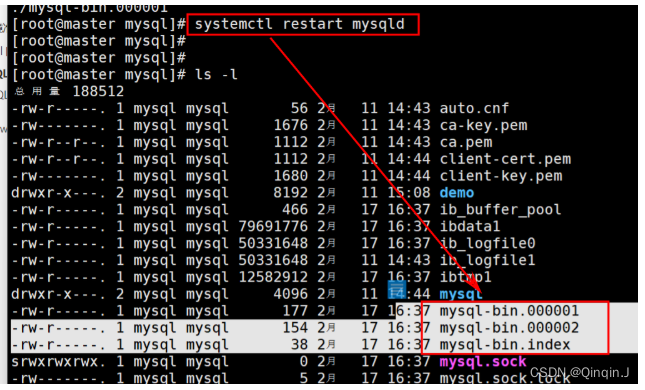
查看
4、测试
cd /var/lib/mysql
cat mysql-bin.000002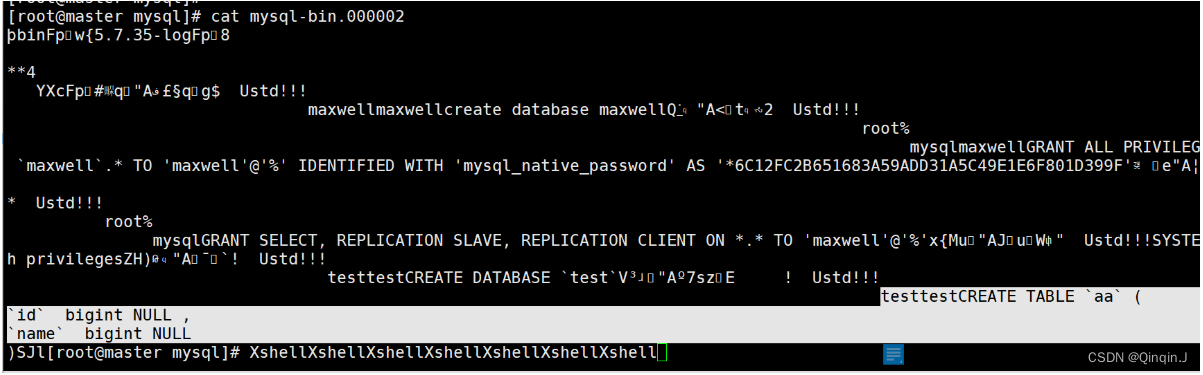
三、初始化 Maxwell 元数据库
1、在 MySQL 中建立一个 maxwell 库
在 MySQL 中建立一个 maxwell 库用于存储 Maxwell 的元数据
mysql -uroot -pPassword123$
create database maxwell;2、设置 mysql 用户密码安全级别(可设置可不设置)
set global validate_password_length=4;
set global validate_password_policy=0;3、分配一个账号可以操作该数据库
grant all on maxwell.* to 'maxwell'@'%' identified by 'Password123$';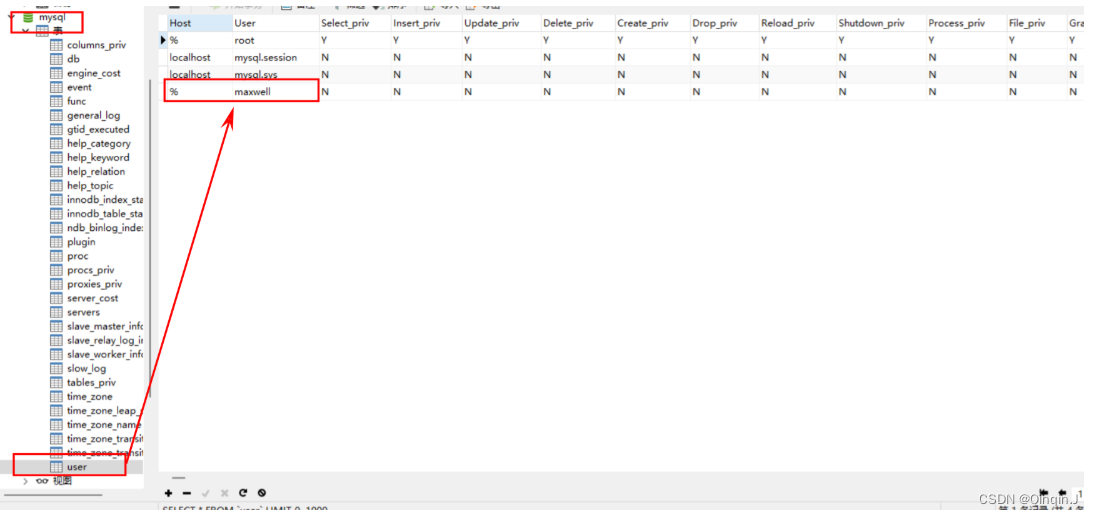
4、分配这个账号可以监控其他数据库的权限
grant select ,replication slave ,replication client on *.* to maxwell@'%'; 
5、刷新 mysql 表权限
flush privileges;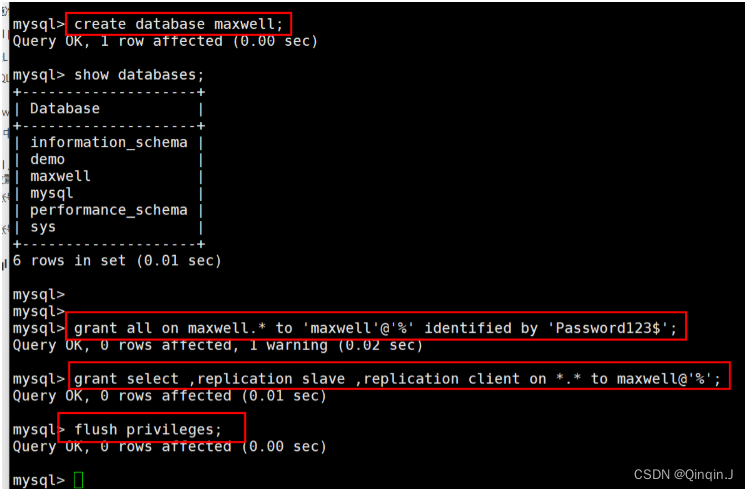
四、进程启动
Maxwell 进程启动方式有如下两种
1、使用命令行参数启动 Maxwell 进程
cd /opt/module/maxwell-1.29.2/
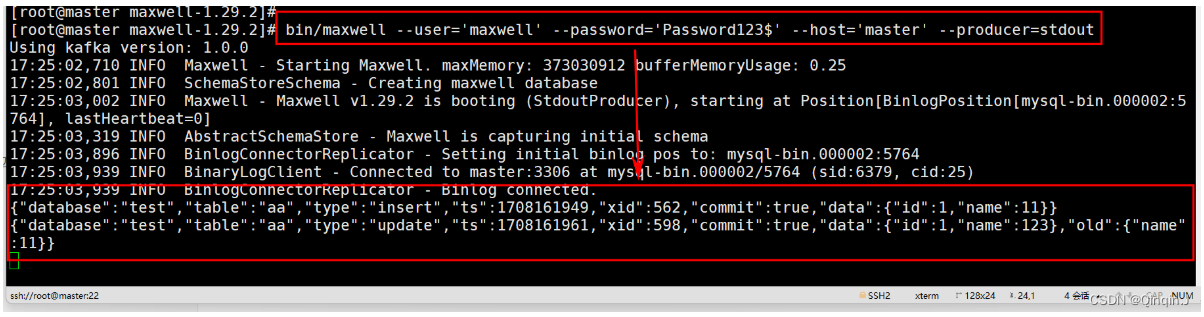
bin/maxwell --user='maxwell' --password='Password123$' --host='master' --producer=stdout解释
--user 连接 mysql 的用户 --password 连接 mysql 的用户的密码 --host mysql 安装的主机名 --producer 生产者模式(stdout:控制台 kafka:kafka 集群)
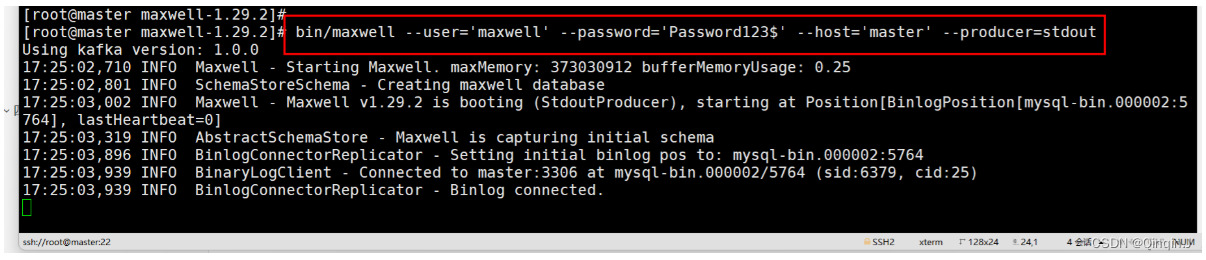
测试
修改数据表在控制台即可看到
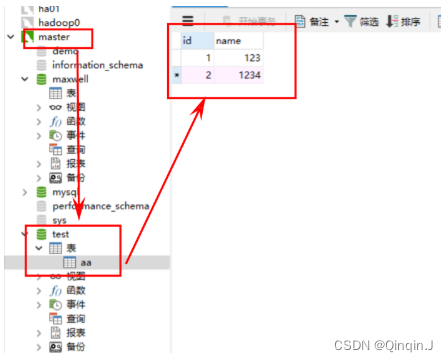
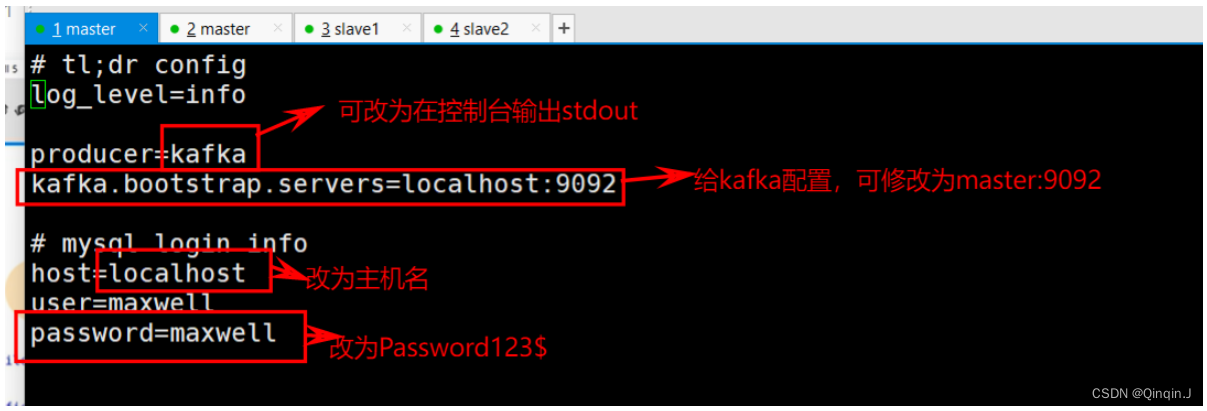
2、修改配置文件,定制化启动 Maxwell 进程
cd /opt/module/maxwell-1.29.2/
cp config.properties.example config.properties
vi config.properties
#启动命令
bin/maxwell --config ./config.properties修改以下内容
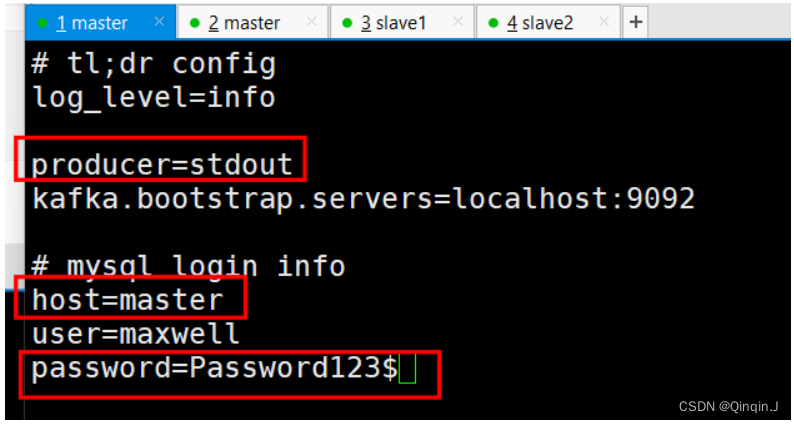
修改后
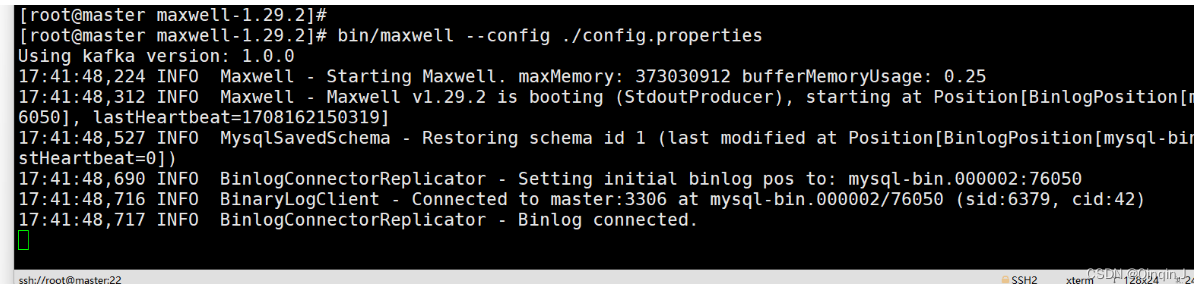
启动
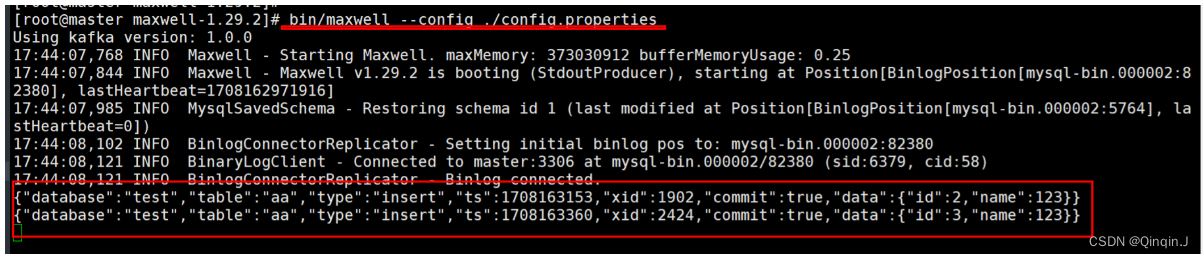
bin/maxwell --config ./config.properties启动成功
测试
添加或修改
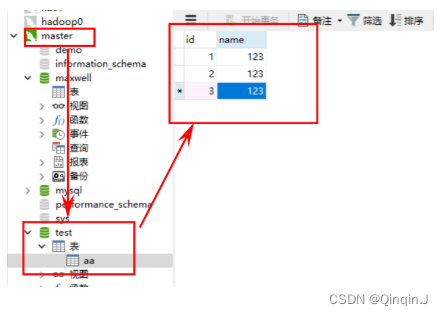
查看
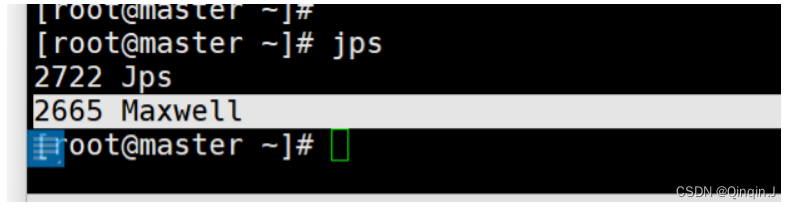
3、查看进程
五、案例
1、监控 Mysql 数据并在控制台打印
先建表
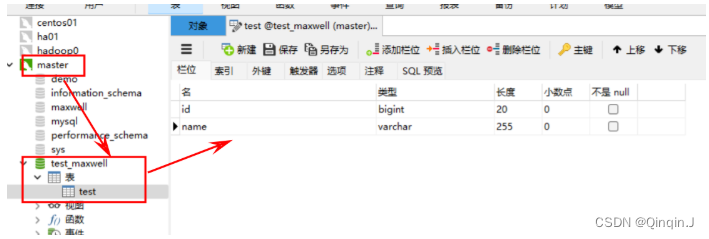
或者
mysql -uroot -pPassword123$
#新建数据库
create database test_maxwell;
#使用数据库
use test_maxwell;
#新建表
create table test (id int,name varchar(50));(1)运行 maxwell 来监控 mysql 数据更新
启动
cd /opt/module/maxwell-1.29.2/
bin/maxwell --user='maxwell' --password='Password123$' --host='master' --producer=stdout(2)向 test 表插入一条数据
向 mysql 的 test_maxwell库的 test 表插入一条数据,查看 maxwell 的控制台输出
insert into test values(1,'aaa');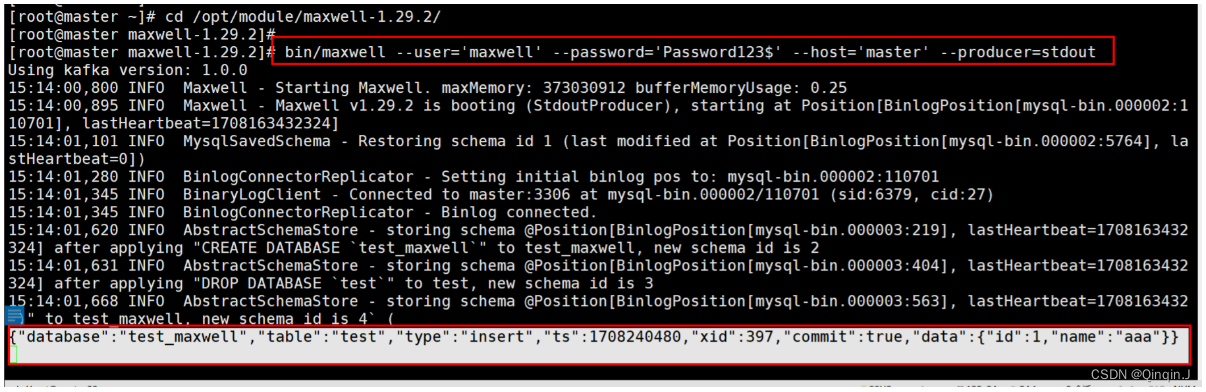
{"database":"test_maxwell", --库名"table":"test", --表名"type":"insert", --数据更新类型"ts":1708240480, --操作时间"xid":397, --操作 id"commit":true, --提交成功"data":{ --数据"id":1,"name":"aaa"}
}
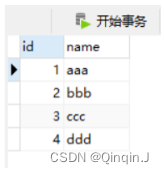
(3)向 test 表同时插入 3 条数据
向 mysql 的 test_maxwell 库的 test 表同时插入 3 条数据,控制台出现了 3 条 json日志,说明 maxwell 是以数据行为单位进行日志的采集的。
insert into test values(2,'bbb'),(3,'ccc'),(4,'ddd');

(4)修改 test 表的一条数据
修改 test_maxwell 库的 test 表的一条数据,查看 maxwell 的控制台输出
update test set name='abc' where id =1; 

{"database":"test_maxwell","table":"test","type":"update","ts":1708241222,"xid":2262,"commit":true,"data":{ --修改后的数据"id":1,"name":"abc"},"old":{ --修改前的数据"name":"aaa"}
}
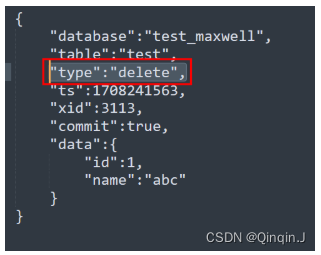
(5)删除 test 表的一条数据
删除 test_maxwell 库的 test 表的一条数据,查看 maxwell 的控制台输出
delete from test where id=1;

2、监控 Mysql 数据输出到 kafka
在mysql进行增删改查的binlog,保存到了kafka里
(1)启动kafka和zooKeeper
启动zooKeeper
# 启动
zkServer.sh start
# 查看状态
zkServer.sh status
# 停止
zkServer.sh stop启动kafka
各节点上启动
/opt/module/kafka_2.11-2.4.1/bin/kafka-server-start.sh -daemon /opt/module/kafka_2.11-2.4.1/config/server.properties关闭kafka
/opt/module/kafka_2.11-2.4.1/bin/kafka-server-stop.sh -daemon /opt/module/kafka_2.11-2.4.1/config/server.properties(2)启动 Maxwell 监控 binlog
cd /opt/module/maxwell-1.29.2/
bin/maxwell --user='maxwell' --password='Password123$' --host='master' --producer=kafka --kafka.bootstrap.servers=master:9092 --kafka_topic=maxwell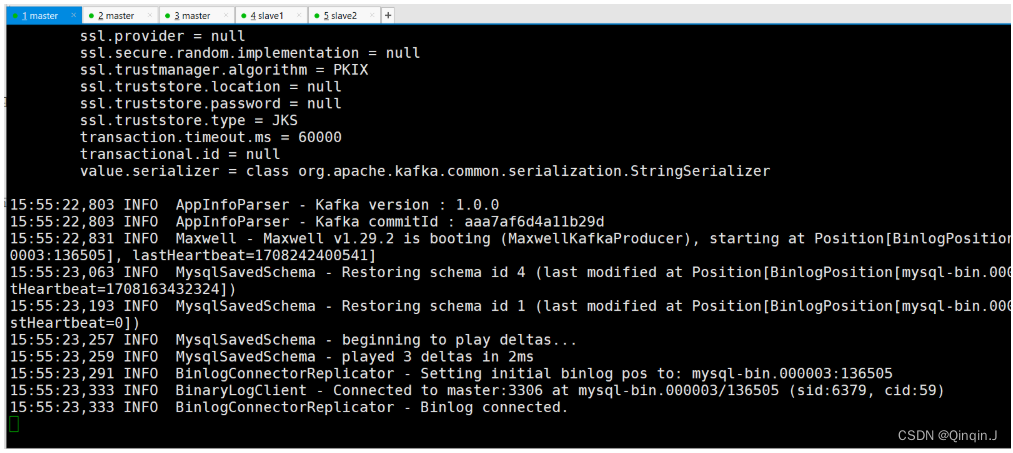
(3)打开 kafka 的控制台的消费者消费 maxwell 主题
cd /opt/module/kafka_2.11-2.4.1/bin
./kafka-console-consumer.sh --bootstrap-server master:9092 --topic maxwell --from-beginning
(4)向 test_maxwell 库的 test 表再次插入一条数据
insert into test values(5,'aaa');
(5)通过 kafka 消费者来查看到了数据,说明数据成功传入 kafka

{"database": "test_maxwell","table": "test","type": "insert","ts": 1708243199,"xid": 6293,"commit": true,"data": {"id": 5,"name": "aaa"}
}
复制一个窗口,查看
cd /opt/module/kafka_2.11-2.4.1/bin
./kafka-topics.sh --bootstrap-server master:9092 --list
这篇关于Maxwell安装使用和简单案例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





