本文主要是介绍基于javacc设计Cb编译器《自制编译器》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 1.引言
- 2.cbc编译器的环境配置
- 3.代码分析
- 3.1 词法分析
- 3.1.1正则表达式的扫描器
- 3.1.2 TOKEN命令
- 4.JavaCC制作解析器
- 4.1 JavaCC的语法描述
- 4.2 JavaCC的EBNF表示法
- 5.语法分析
- 6.抽象语法树
- 6.1 抽象语法树的构成
- 7.语义分析
- 7.1变量引用的消解
- 7.2类型名称的消解
- 7.3 类型定义检查
- 7.4 表达式有效性检查
- 7.5 静态类型检查
- 8.中间代码生成
- 9.汇编代码
- 10.链接和加载
- 11.总结
1.引言
编译器是从事软件行业有关人员所必不可少的,但是大多数人只会使用编译器,并不了解编译器的原理,如何使编程语言转换为计算机可以识别的语言,下文中将进行概述,描述Cb语言的编译器的编译过程。
本文所讲述的编译器,编译分为4个阶段:语法分析、语义分析、生成中间代码和代码生成。语法分析,使用语法分析器将代码转换成机器可以理解的形式,即语法树。语义分析,对语法树进一步解析处理,转化为抽象语法树,删除多余的内容,添加必要信息,如区分变量作用域、变量的声明和引用、变量和表达式的类型检查等等。生成中间代码,将抽象语法树转换成中间代码。最后一步是代码生成,即中间代码转化为汇编语言。除此之外,还包含优化阶段。
2.cbc编译器的环境配置
使用Cb编译器需要如下3款软件
- Linux
- JRE(Java Runtime Envirnment)1.5以上的版本
- Java编译器(非必需)
读者所下载的环境,均为x86版本的,即32位Linux操作系统 和JRE版本。
3.代码分析
3.1 词法分析
词法分析是指将代码分割成一个一个单词,也称为扫描。Cb编译器使用JavaCC生成解析器和扫描器。
3.1.1正则表达式的扫描器
JavaCC使用正则表达式的语法来描述需要解析的单词的规则。如下举出一些例子:
字符组:特定字符中的任一字符,["a"-"z","A"-"Z","0"-"9","_"]表示字母或数字或者下划线任意一个字符。
重复1次或多次:("x")+,和《编译原理》中所讲的相同,该模式与"x","xxx","xxxxx"等匹配,即一个或者多个x的模式串。
重复0次或多次:("x")*,与上述有所区别,该模式与"","xxx","xxxxx"等匹配,即零个或者多个x的模式串。
选择:描述"ABC"或者"XYZ",使用"|"隔开表示,"ABC"|"XYZ"。
3.1.2 TOKEN命令
扫描器是将语言分割成单词,并且给出语义,就是Token序列。JavaCC中扫描token所使用的的是Token命令,并且记录下Token名和正则表达式表示其语义。扫描类型分为四种:没有结构的单词、不生成token的单词、具有结构的单词。使用SKIP命令和SPECIAL_TOKEN命令完成扫描不生成TOKEN的单词,使用DEFAULT状态迁移和MORe命令解决具有结构的单词,对特殊情况和字符串的区分。下图是扫描标识符、保留字和扫描数值的TOKEN命令,与前面所提及的正则表达式一致。

扫描标识符TOKEN
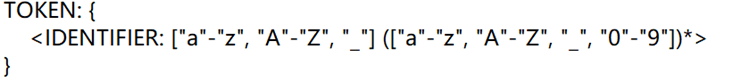
扫描保留字TOKEN

扫描数值TOKEN
4.JavaCC制作解析器
解析器的作用是利用扫描器生成的token序列生成语法树。
4.1 JavaCC的语法描述
赋值表达式:assign():
{}
{
“=” expr()
}
上述例子中描述了JavaCC中表达式的表示方法,其中对应前面词法分析出的token标识符,"=“对应”=“token标识符,expr()表示表达式。
表达式:expr():
{}
{
expr()”+" expr()
或 expr()"-" expr()
或 expr()"*" expr()
…
}
在JavaCC的语法分析中需要区分终端符和非终端符,因为终端符和非终端符和语法树有密切关联,在语法树中,终端符始终位于叶子结点,非终端符则位于非叶子结点。
种类 含义 例
终端符 token <IDENTIFER>、<LONG>、"="、"+"
非终端符 用终端符号排列组成的语法单位 Stmt()\expr()\assignment()
4.2 JavaCC的EBNF表示法
种类 例子
——————————————————————————————————————————————————
终端符 <IFENTIGIER>或","
非终端符 name()
连接 <UNSIGNED><LONG>
重复0次或多次 (","expr())*
重复1次或多次 (stmt())+
选择 <CHAR>|<SHORT>|<LONG>|<INT>
可以省略 [<ELSE> stmt()]
5.语法分析
一般的编程语言的语法包含5种,定义(definition)、声明(declaration)、语句(statement)、表达式(expresssion)、项(term)。
定义是指函数或者变量的定义。函数或者方法中包含语句。比语句更小的是表达式。二元运算符中则经常使用“项”。
本文所实现的编译器中包含变量定义的语法、函数定义的语法、结构体定义和联合体定义的语法、结构体成员和联合体成员的语法,所参照的书中给出了更加详细的解析 ,此处不再赘述。下图给出一些例子:

各类定义的语法

变量定义的规则
6.抽象语法树
仅有语法规则只能对源代码的语法进行检查,需要进一步分析代码并生成语法树,本文实现的编译器使用了JavaCC的action功能,使用action可以生成抽象语法树。《自制编译器》一书中对JavaCC的action功能进行了详细说明,如下总结:
“
● 使用action能够获取终端符号、非终端符号的语义值,还能够给非终端符号赋予语义值
● 终端符号的语义值为Token类的实例,从Token类的属性中可以取得token的字面量及其在原文件中的位置等信息
● 非终端符号的语义值取决于action。通过在规则的开头添加语义值的类型,并从action返回值,就可以设置语义值
● 当解析到规则中写有action之处时,action才会被执行。若在符号串的最后写有action,那么在该符号串全部被发现后action才会被执行
● 组合使用选项和action,能够编写只有在发现特定的选项是才能被执行的action
● 组合使用重复和action,能够编写在每次重复是都会被执行的action”
6.1 抽象语法树的构成
抽象语法树一般由结点(Node)的数据结构组成,在语法树中,语句、表达式、变量等都有其对应的结点。
继承Node的子类非常多,其中比较重要的有AST(表示抽象语法树的根的结点)、StmtNode(表示语句的结点的基类)、ExprNode(表示表达式的结点的基类)、TypeDefinition(定义类型的结点的基类)。
在本文的编译过程中使用action和Node类生成语法树,还可以使用JJTree的工具来生成语法树。
Node类的源代码如下图:

Node类
7.语义分析
仅仅对抽象语法树进行语义分析是不够的,还需要处理变量引用的消解和类型检查。有如下五种:变量引用的消解、类型名称的消解、类型定义检查、表达式的有效性检查、静态类型检查。
7.1变量引用的消解
“变量引用的消解”,就是要明确是哪一个变量,比如一个变量i,可能是全局变量、局部变量或者静态变量,消解就是消除这个变量的不确定性,即明确具体是指哪一个变量。
变量引用如何消解,本文中的编译器采用了Scope树和栈(stack)对变量引用进行消解。每一个程序所生成Scope树中都有一个根结点TolevelScope,根结点下面会生成和定义的函数数量相同的LocalScope孩子,每一个LocalScope下面有任意数量的LocalScope所组成。
生成Scope树后,从引用某变量的作用域开始向上查找,最先找到的变量定义就可以确定此变量的引用。这种Scope这样管理变量和函数名称列表的类又叫做符号表。
Scope及其子类
类名 作用
Scope 表示作用域的抽象类
TolevelScope 表示程序顶层的作用域。保存有函数和全局变量
LocalScope 表示一个临时变量的作用域。保存有形参和临时变量
7.2类型名称的消解
“类型名称的消解”,本文提到的编译器中使用了两个类表示类型,Type表示类的定义,TypeRef表示类型的名称,
此处的消解就是将类型的名称转换为类型的定义,即TypeRef对象转换为Type对象。
类型定义的消解相对于变量引用的消解来说,要简单一些,因为类型的定义不包含作用域嵌套,
因此只需要遍历抽象语法树,然后把TypeRef类型转换成Type类型即可。
7.3 类型定义检查
“类型定义检查”,检查是否存在语义方面的类型定义问题。类型定义中包含三种:包含void的数组/结构体/联合体,成员重复的结构/联合体,循环定义的结构/联合体。
包含void和成员重复的类型可以通过全面检查解决。循环定义这一种,把类型的定义抽象成图,每一种类型为一个结点,这个结点和其他类型的引用成为一条边,可以得到一个图结构,如果此图中有闭环,那么则存在循环定义的错误。
7.4 表达式有效性检查
“表达式的有效性检查”,检查一个表达式是否可以执行,例如常量运算符使用错误等。
有问题表达式的示例 检测方法
4=5+6 检查左边是否为可赋值的表达式
"string"(“%d\n”,i) 检查操作数的类型是否是指向函数的指针
1[0] 检查操作数的类型是否是数组或指针
2.member 检查操作数的类型是否是拥有成员member的结构体或联合体
3->memb 检查操作数的类型是否是指向拥有成员memb的结构体或联合体
*4 检查操作数的类型是否是数组或指针
&5 检查操作数的类型是否是可赋值的表达式
++6 检查操作数的类型是否是可赋值的表达式
7.5 静态类型检查
“静态类型检查”,检查表达式类型,是否存在类型错误,例如将float类型的变量直接赋值给指针类型,这种情况应该直接报错。
8.中间代码生成
中间代码有很多的形式,例如三地址代码、逆波兰式等等。
由于中间代码有很多种形式,所以要有目的地使用中间代码,例如如果希望充分运用原始语言的信息并进行优化应该使用近似于抽象语法树的树型中间代码。
如果想在接近机器语言的层面对内存的使用等进行优化,那就应该使用想三地址代码这样更接近及其语言的中间点。
如果不需要优化知识希望尽快输出及其语言,那么不使用中间代码也可以。
9.汇编代码
本文所使用的汇编器是GNU as。GNU as由GNU提供,《自制编译器》中详细讲解了如何编写相应的汇编代码,本文所提及的汇编代码也对栈帧、虚拟栈分配临时变量进行操作,并且生成序言和函数尾声。在Cb编译器中生成汇编代码遵循3个规则。
1.Cb中所有变量或者临时变量都保存到内存中
2.对内存的操作先定位mov指令
3.限定每个寄存器类的应用范围
10.链接和加载
链接是指把多个目标文件关联为一个整体。而通过关联多个目标文件,就可以生成同时使用多个目标文件定义的变量、函数的程序,本文中的编译器使用GNU as中的as命令直接对汇编文件进行编译。
Linux系统下通过mmap系统调用把程序加载到内容中。mmap是把文件内容映射到内存空间中的系统调用。
11.总结
制作一个编译器的流程,首先第1步,对源码进行词法分析,把文本进行分割处理。
第2步,进行语法分析,就是分析token序列,得到抽象语法树。
第3步是语义分析和生成中间代码,语义分析就是把变量引用和实体链接,对应起来,并且进行类型检查,然后把抽象语法树转换成所需的、易于生成代码的中间代码,生成中间代码后,语法树会减少很多无 用节点。
第4步是生成代码,把中间代码书的节点转化成对应的汇编语言的指令,调用as命令,把汇编语言进行汇编,会输出ELF的可重定位文件main.o。
第5步,在连接之前,要编译汇编lib.cb,生成共享库,并且将库代码全部设置为地址无关代码。
第6步,通过cbc命令启动ld,生成可执行文件。
最后,设置LD_LIBRARY_PATH环境变量指定运行是库的搜索路径,可以启动main程序。制作一个编译器的流程到此为止。
【参考文献】
[1] [日]青木峰郎/译 严圣逸 绝云/译 《自制编译器》 2016.6
[2] 姚砺,束永安.用JavaCC构造编译器的方法[J].计算机工程,2003(09):39-41.
[3] 黄松,黄玉,惠战伟.基于JavaCC的抽象语法树的构建与实现[J].计算机工程与设计,2016,37(04):938-943.
[4]王莉莉. 基于抽象语法树的软件语义分析方法研究[D].哈尔滨工程大学,2014.
[5]封战胜. 基于GCC抽象语法树文本的C源程序语义分析方法研究[D].哈尔滨工业大学,2009.
[6]王佳林,张美玲,高涵.浅析编译原理中编译工作的基本流程及其实现[J].中国新通信,2019,21(24):150.
这篇关于基于javacc设计Cb编译器《自制编译器》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




