本文主要是介绍DRF ModelSerializer序列化类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ModelSerializer序列化类
【0】准备
- 模型表创建
from django.db import modelsclass Book(models.Model):name = models.CharField(max_length=64, verbose_name='书名')price = models.DecimalField(max_digits=6, decimal_places=2, verbose_name='价格')publish = models.ForeignKey(to='Publish', on_delete=models.CASCADE, verbose_name='出版社外键')authors = models.ManyToManyField(to='Author', verbose_name='作者外键')class Publish(models.Model):name = models.CharField(max_length=64, verbose_name='出版社名字')addr = models.CharField(max_length=64, verbose_name='出版社地址')class Author(models.Model):name = models.CharField(max_length=64, verbose_name='作者名字')detail = models.ForeignKey(to='AuthorDetail', on_delete=models.CASCADE, verbose_name='详情外键字段')class AuthorDetail(models.Model):phone = models.BigIntegerField(verbose_name='电话号码')age = models.IntegerField(verbose_name='年龄')
【1】ModelSerializer简介
-
使用
ModelSerializer,你可以自动推断字段类型,并快速创建一个序列化器,该序列化器能够处理 Django 模型实例的序列化和反序列化。 -
特点
- 自动字段推断:
ModelSerializer会自动根据 Django 模型中的字段来生成对应的序列化器字段。 - 创建和更新模型实例:除了序列化模型数据,
ModelSerializer还可以处理创建和更新模型实例的逻辑。 - 可定制性:虽然
ModelSerializer提供了许多便利,但它也允许你覆盖默认行为,比如自定义字段,添加额外的验证等。
- 自动字段推断:
【2】Meta的参数
(1)参数介绍
-
model- 它接受一个Django模型类作为值,用于告诉序列化器该序列化器是基于哪个模型生成的。
-
fieldsfields参数是一个列表或元组,用于指定序列化器应该包含模型中的哪些字段(包括自定义的字段)。- 默认为:
fields = '__all__'即包含所有字段
- 默认为:
-
extra_kwargsextra_kwargs是一个字典,允许你为序列化器中的字段指定额外的参数。这些参数会覆盖从模型字段自动生成的序列化器字段的参数。extra_kwargs的键是字段名,值是另一个字典,包含你想为该字段指定的参数。这可以用于控制字段的序列化行为,例如指定read_only、required、validators、source等。
(2)示例
- 图示
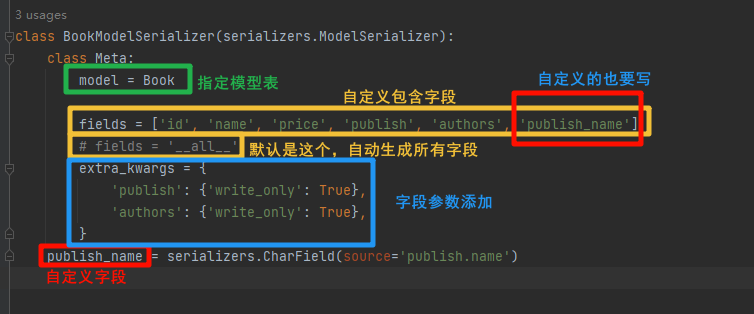
- 代码
class BookModelSerializer(serializers.ModelSerializer):class Meta:model = Bookfields = ['id', 'name', 'price', 'publish', 'authors', 'publish_name']# fields = '__all__'extra_kwargs = {'publish': {'write_only': True},'authors': {'write_only': True},}publish_name = serializers.CharField(source='publish.name', read_only=True)
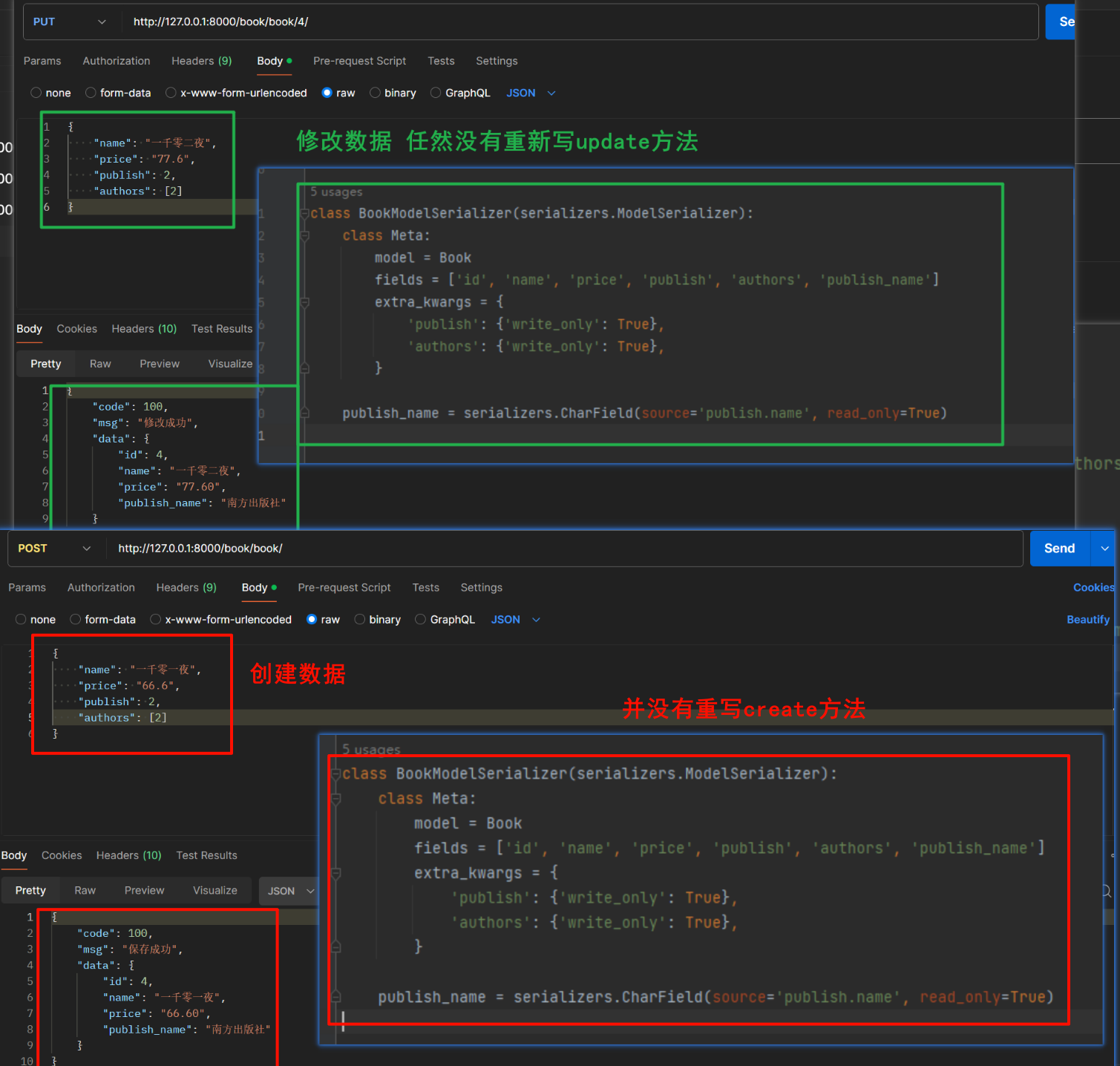
【3】简单反序列化
- 在前面学习
serializers.Serializer的时候- 一直在强调,如果是创建新数据保存,那么就要重新create方法,如果是更新数据,那么一定要重写update方法
- 但是在
serializers.ModelSerializer我们是不用重写这两个方法的,ModelSerializer已经帮我们写好了,只要按照正常的格式输入,那么就可以了
【4】重写反序列化保存和修改
-
还是以作者的创建为例
-
在模型表的修改中,作者信息保存在了两个表中
- 一个表保存了作者的名字和详情的外键字段
- 另一个表保存了作者的详细信息
-
在前端传入的过程中是不可能分开传输的,即先传输名字,在传输其他信息,显示是不合理,所以这里通过一个路由接口,传递所有的信息并创建保存
-
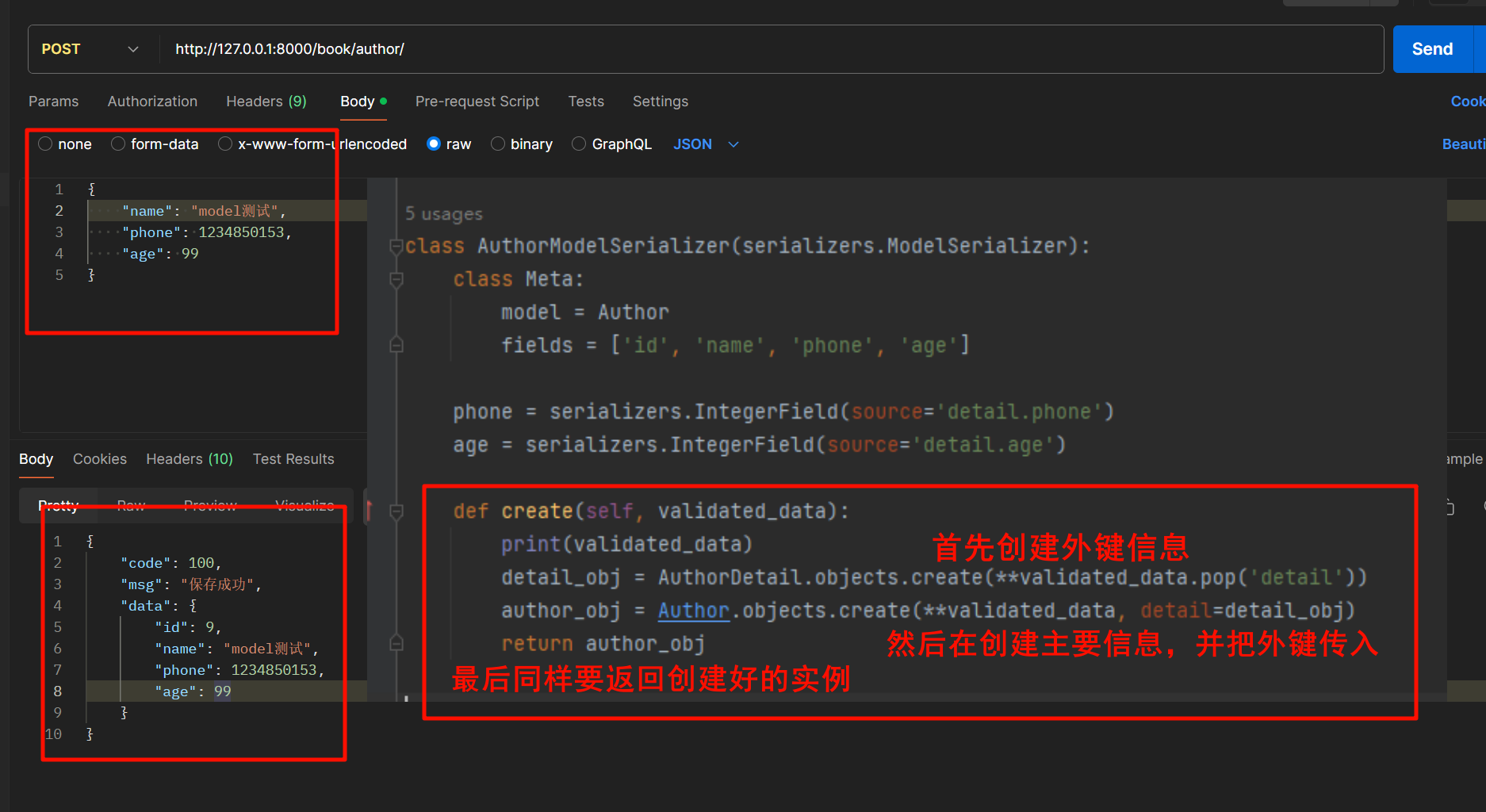
然而
ModelSerializer的反序列化保存,需要让我们传递的是外键字段的ID,这里我们要传递的是外键的具体信息,所以这个需要我们自己重写这两个方法 -
重写
create方法
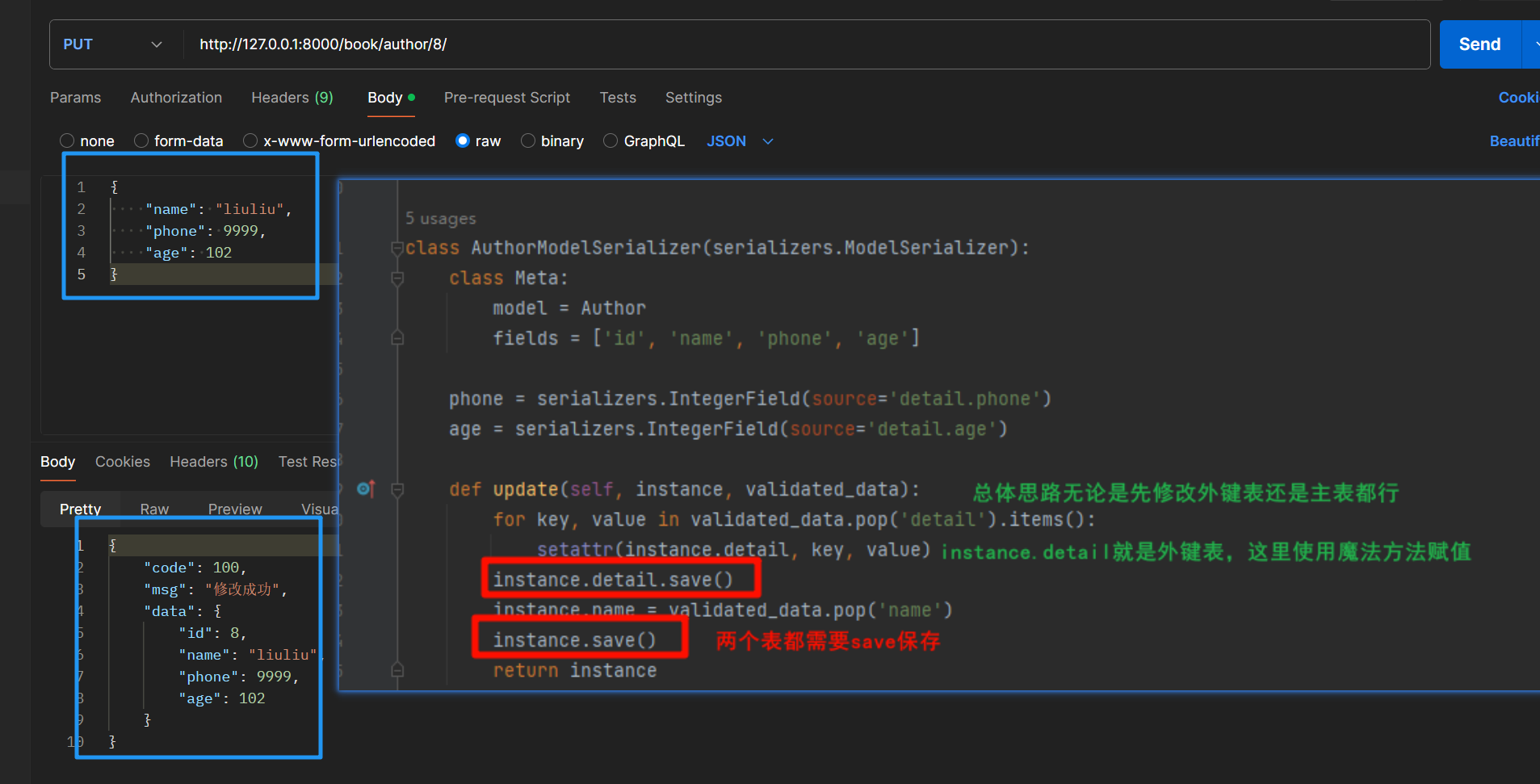
- 重写update方法
- 代码
class AuthorModelSerializer(serializers.ModelSerializer):class Meta:model = Authorfields = ['id', 'name', 'phone', 'age']phone = serializers.IntegerField(source='detail.phone')age = serializers.IntegerField(source='detail.age')def update(self, instance, validated_data):for key, value in validated_data.pop('detail').items():setattr(instance.detail, key, value)instance.detail.save()instance.name = validated_data.pop('name')instance.save()return instancedef create(self, validated_data):print(validated_data)detail_obj = AuthorDetail.objects.create(**validated_data.pop('detail'))author_obj = Author.objects.create(**validated_data, detail=detail_obj)return author_obj
这篇关于DRF ModelSerializer序列化类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




