本文主要是介绍Python数据结构【四】排序(二)难度:困难,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 一、书接上回
- 二、快速排序(Quick Sort)
- 2.1 快速排序思想
- 2.2 快速排序代码实现
- 2.3 快速排序复杂度分析
- 三、堆排序(Heap Sort)
- 3.1 堆排序思想
- 3.2 堆排序代码实现
- 3.3 堆排序复杂度分析
- 结语
前言

可私聊进一千多人Python全栈交流群(手把手教学,问题解答)
可私聊获取源代码和动画PPT进群可领取Python全栈教程视频 + 多得数不过来的计算机书籍:基础、Web、爬虫、数据分析、可视化、机器学习、深度学习、人工智能、算法、面试题等。
- 🚀🚀加入我一起学习进步,一个人可以走的很快,一群人才能走的更远!
-
一、书接上回
上次学习了冒泡排序,插入排序,选择排序,今天需要学习的是快速排序,堆排序。
相比于前面三个,这两个可以说是有一点点难度的了。
二、快速排序(Quick Sort)
快速排序,突出的就是一个快字,比前面三个时间复杂度少一点,因为快排使用了类似于二分+递归的方法。
2.1 快速排序思想
-
取出一个元素(通常是第一个)
-
然后将该元素放入一个位置使得左边的元素都小于该元素,右边的元素都大于该元素
-
然后对该元素左右两边进行切割
-
然后递归
-
结束
整了个动画来讲解第二步

2.2 快速排序代码实现
由于第二步功能较多,所以我们可以使用一个函数封装起来。
找中位数函数(也就是动图的实现)
def find_mid(left, right, li):"""left: 左指针right: 右指针li: 列表之所以不是0和n-1是为了递归的时候也能使用"""swep = False # 代表左边有无空temp = li[left]while left < right: # 循环终止条件if swep == False: # 如果左边有空位if li[right] < temp: # 判断是否可以交换li[right],li[left] = li[left],li[right] # 交换swep = True # 左边无空位else:right -= 1 # 不交换,左边有空位,右指针移动else: # 左边无空位if li[left] > temp: # 判断li[left],li[right] = li[right],li[left] # 交换swep = False # 左边有空位else:left += 1 # 无法腾出空位,左指针移动li[left] = temp # 找到位置,将元素插入return left # 此时左右重合,退出函数快排递归函数:
def quick_sort(left, right, li):if left < right: # 递归终止条件mid = find_mid(left, right, li)quick_sort(left, mid-1, li) # 排序左边的quick_sort(mid+1, right, li) # 排序右边的测试用例:
[5, 4, 2, 8, 3, 9]运行结果:
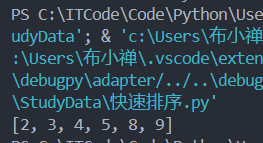
测试用例:
[1, 1, 4, 5, 1, 4]运行结果:
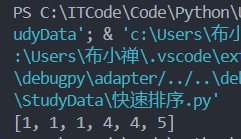
2.3 快速排序复杂度分析
时间复杂度:
nlogn空间复杂度:
nlogn(实际上这个是递归的空间复杂度,因为原地排序是不需要空间复杂度的)当然这些都是算平均的复杂度,时间上算法的时间空间复杂度都是由最优和最劣的情况的,这里就不一一赘述了
三、堆排序(Heap Sort)
堆排序,就是使用堆来进行排序的一种排序方法。
- 堆——堆是一种特殊的
完全二叉树- 大根堆——一种
完全二叉树,满足任意节点都比孩子节点大 - 小根堆——一种
完全二叉树,满足其任意节点都比孩子节点小
- 大根堆——一种

当然树这个数据结构是没有箭头的,我只是想起来已经做出来了就懒得重做了。
3.1 堆排序思想
通过堆的向下调整来排序。(左右子树都满足大/小根堆,但是堆本身不满足)
- 建立一个堆(需要从小到大排就建立小根堆,需要从大到小就建立大根堆)
- 得到堆顶元素(此时堆是大根/小根堆,是有序的)
- 将堆顶元素去掉,替换为堆最后的元素,进行堆的向下调整(此时堆顶元素为最大/最小元素)
- 重复步骤2,3,直到堆为空(使用递归,判断根节点是否为空)
由于堆的向下调整比较难,所以只做一个向下调整的演示动画。

如果将上述堆通过列表展示,则列表为:
[2, 5, 4, 3, 8, 7]从根节点向下,然后每个子树都完全展示出来
3.2 堆排序代码实现
向下调整函数:
def change_down(li, low, high):"""li: 无序数组low: 根节点元素high: 最后一个元素位置"""temp = li[low] # 存起来栈顶元素i = low # i指向根节点j = 2 *i + 1 # j指向左孩子节点while j <= high: # 只要j不为空if j + 1 <= high and li[j+1] > li[j]: # 如果右孩子节点大j = j + 1 # j指向右孩子节点 if li[j] > temp: # 如果左孩子节点大li[i] = li[j] # 将大的放在栈顶i = j # 下一层j = 2* i + 1 # 重新设定左孩子结点else: # 如果栈顶元素是最大的li[i] = temp # 将栈顶元素存入栈顶或者某个子树的根节点break # 结束循环else:li[i] = temp # 将原栈顶元素放在叶子结点堆排序代码:
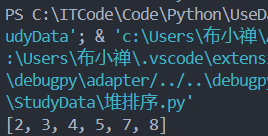
def heap_sort(li):n = len(li)for i in range((n-2)//2, -1, -1): # 从叶子结点的子树向每个子树的根节点遍历change_down(li, i, n-1) # 建堆for i in range(n-1, -1, -1): # 挨个取出栈顶元素li[0], li[i] = li[i], li[0] # 将栈顶元素和最后一个元素进行交换change_down(li, 0, i-1) # 向下调整测试用例:
[2, 4, 8, 7, 3, 5]运行截图:
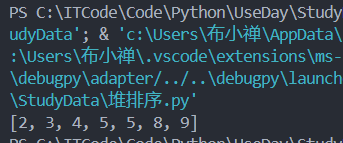
测试用例:
[5, 4, 2, 8, 3, 9, 5]运行截图:
3.3 堆排序复杂度分析
时间复杂度:
O(nlogn)空间复杂度:
O(1)如果使用一个辅助列表,那就是O(n)结语
俗话说得好,光说不练——假把式。一定要多练,多思考。
想不通就先不想,先去练,多练几次就明白了。
正如古话说得好,书读百遍其义自见!
-
这篇关于Python数据结构【四】排序(二)难度:困难的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






