本文主要是介绍Assign Memory Resources to Containers and Pods,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
minikube addons enable metrics-server
minikube addons enable metrics-server是一个命令,用于在 Minikube 环境中启用 metrics-server 插件。Minikube 是一个工具,可以在本地轻松创建和管理单节点 Kubernetes 集群,适合开发和测试。Minikube 支持多种插件(addons),这些插件可以提供额外的功能。
metrics-server 是 Kubernetes 的一个组件,它收集和存储集群中各个节点和 Pod 的资源使用情况数据。这些数据可以用于 Kubernetes 的自动扩缩容功能。
所以,
minikube addons enable metrics-server命令会启用 metrics-server 插件,让你的 Minikube 集群可以收集和使用资源使用情况数据。
To specify a memory request for a Container, include the resources:requests field in the Container's resource manifest. To specify a memory limit, include resources:limits.
在 Kubernetes 中,你可以为每个容器设置内存请求(memory request)和内存限制(memory limit)。
内存请求:这是容器需要的最小内存量。Kubernetes 调度器会使用这个值来决定将 Pod 放置在哪个节点上。节点必须有足够的可用内存来满足 Pod 中所有容器的内存请求。
内存限制:这是容器可以使用的最大内存量。如果容器试图超过这个限制使用内存,它将被系统 OOMKiller 终止。
你可以在容器的资源清单中使用
resources:requests和resources:limits字段来设置内存请求和内存限制。例如:在这个例子中,
memory-demo-ctr容器的内存请求是 100MiB,内存限制是 200MiB。
在 Linux 系统中,当系统内存不足时,OOM Killer(Out Of Memory Killer)会被触发,它的任务是选择并杀死一些进程以释放内存。
在 Kubernetes 中,如果一个容器试图使用超过其内存限制的内存,它也会被 OOM Killer 终止。这是为了防止一个容器使用过多的内存,从而影响到同一节点上的其他容器或者整个系统。
当容器被 OOM Killer 终止后,它的状态将变为
OOMKilled,并且它的重启策略将决定是否会被重新启动。如果你在 Pod 的定义中设置了restartPolicy: Always,那么这个容器将会被 Kubernetes 重新启动。
apiVersion: v1
kind: Pod
metadata:
name: memory-demo
spec:
containers:
- name: memory-demo-ctr
image: nginx
resources:
limits:
memory: "200Mi"
requests:
memory: "100Mi"
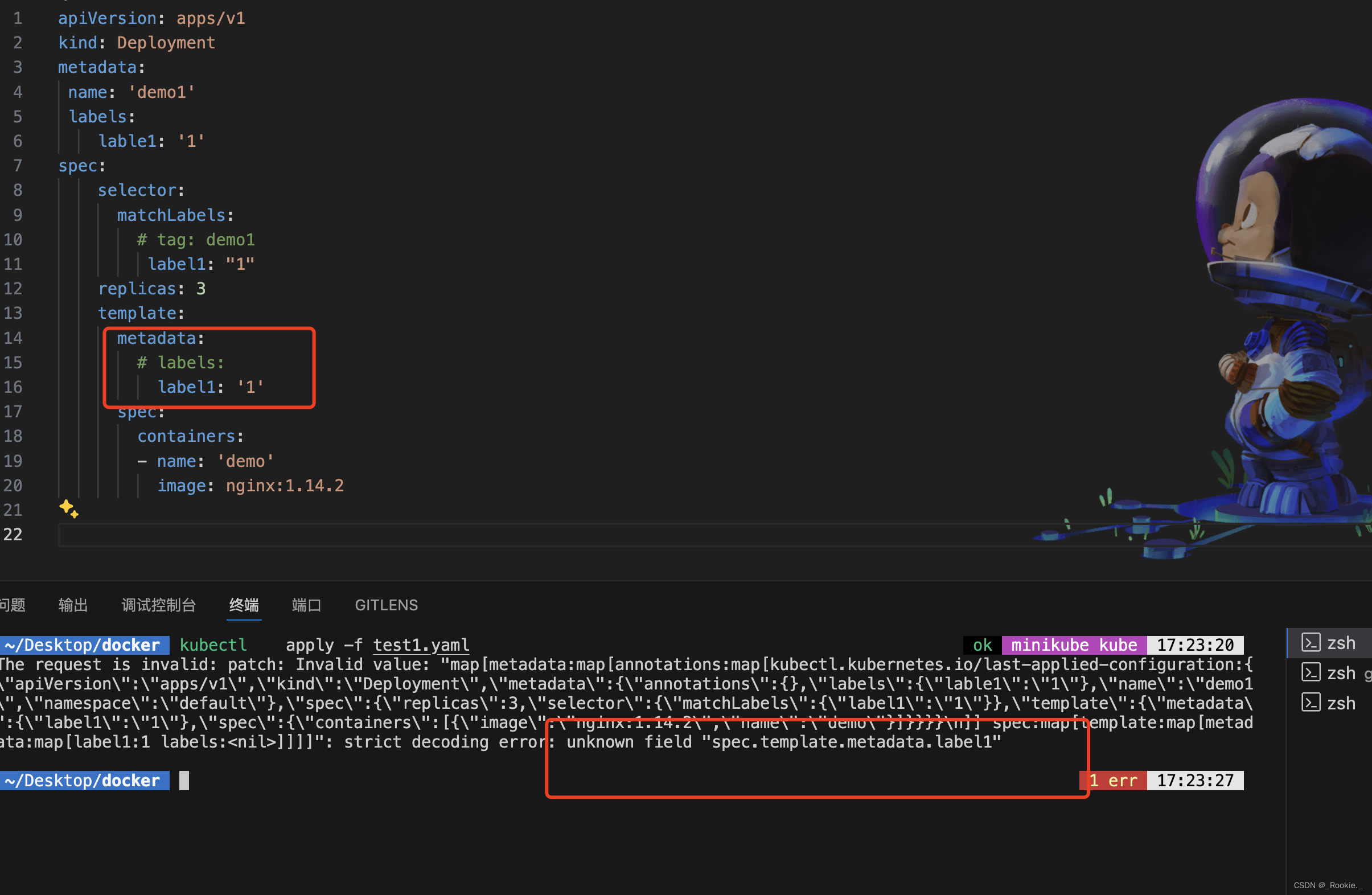
metadata的lables的可选性
对于 pod metadata.lables的lables是可选地,可以直接键值对写一些允许属性:在 Pod 的
metadata字段下,只能有一些预定义的字段,如name、namespace、labels、annotations等
apiVersion: v1
kind: Pod
metadata:name: memory-demo如果你想给 Pod 添加一个 自定义的 age 标签,你应该将它放在 metadata.labels 字段下,apiVersion: v1
kind: Pod
metadata:name: memory-demolabels:age: '19'但是对于 deployment 是必选的
在 Kubernetes 的 Deployment 配置中,
spec.template.metadata.labels和spec.selector是必须的。
spec.template.metadata.labels定义了 Deployment 创建的 Pod 的标签。spec.selector定义了 Deployment 如何找到它应该管理的 Pod。这个选择器必须匹配 Deployment 创建的 Pod 的标签。所以,你不能省略
spec.template.metadata.labels或spec.selector。如果你尝试这样做,Kubernetes 将拒绝你的 Deployment 配置,并显示一个错误消息。
在 Kubernetes 中,Pod 和 Deployment 的
metadata.labels字段都可以直接写键值对,用于给资源添加标签。这些标签可以用于组织和选择资源。然而,Deployment 还有一个
spec.selector字段,这个字段用于选择哪些 Pod 属于这个 Deployment。spec.selector必须匹配spec.template.metadata.labels,也就是说,Deployment 创建的每个 Pod 的标签必须满足选择器的条件。
获取 pod 的yaml的描述文件
kubectl get pod memory-demo --output=yaml --namespace=mem-example
获取 Kubernetes 集群中节点和 Pod 的资源使用情况(如 CPU 和内存)
kubectl top pod memory-demo --namespace=mem-example
kubectl top命令的名称来源于 Unix 和 Linux 系统中的top命令。在 Unix 和 Linux 系统中,top命令用于实时显示系统中的进程和它们的资源使用情况,如 CPU 和内存。同样,
kubectl top命令用于显示 Kubernetes 集群中的节点和 Pod 的资源使用情况。这个命令的名称是为了与 Unix 和 Linux 中的top命令保持一致,因为它们的功能是类似的。
这篇关于Assign Memory Resources to Containers and Pods的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!