本文主要是介绍流量反作弊算法简介,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
参考:流量反作弊算法实践
1. 背景
阅读记录阿里流量作弊的风控文章。甄别阿里妈妈逾千亿商业流量中作弊 与 低质量的部分,保护广告主和平台的利益是风控团队的核心工作之一。
2. 广告风控流程
广告主投放内容与风控团队、下游业务团队的简易交互流程如下。

广告素材通过内容风控审核后,即可在线上进行展示。期间广告主可能会主动作弊、也可能受到其他广告主攻击。需要对无效流量进行过滤,保护广告主的利益,维护健康的广告投放环境。
3. 无效流量
流量反作弊系统的核心能力就是清洗、过滤无效流量。但是无效流量并不等价于作弊流量,还包括低质量流量。
1. 低质量:重复点击计费策略、频率控制策略、剧烈波动策略等;
2. 作弊:转化效果概率为0的流量。
作弊流量转化期望概率一定为0,比如爬虫产生的点击流量。但后续实际频率为0的流量不一定是作弊。比如新商品累计1万点击后仍没有转化,只能说频率为0,不能直接断定为作弊流量。常见的无效流量包括:
1. 消耗竞争对手;
2. 提升自身排名;
3. 自然宝贝刷单误伤广告主;
4. 非恶意无效流量。

3.1 消耗竞争对手 -- 恶意点击
一些广告主,通过构造虚假流量(恶意点击),攻击其他广告主,消耗对方预算致使其广告下架(如原定计划可以投放7日的广告内容,在第2天突然被完全消耗)。这种情况下,很容易引起受害广告主的投诉,影响恶劣。

3.2 提升自身排名 -- 刷质量分
广告排名由出价和质量评分决定。一些广告主会雇佣黑产刷单,提高广告的转化率,通过低成本获得靠前的广告排名。这些作弊利益驱动属性也很强,比较容易被平台和相关广告主感知到。对平台的影响也较为恶劣。
3.3 自然宝贝刷单 -- 货比三家
一些广告主通过雇佣黑产提高店铺的成交数、好评数、加购收藏数等。刷手为了更好地隐藏自己,往往会装作“货比三家”,查看多个宝贝信息。该过程偶尔会误伤了广告展示宝贝。这种作弊对广告生态的影响比较弱。感知程度会偏低一些。此外,人工刷手往往伪装的更好,在流量甄别上难度比较大。
3.4 非恶意无效流量
另外非恶意、非薅羊毛的无效流量也需要被过滤。比如:
1. 一些浏览器在打开淘宝首页时,会预加载所有的宝贝链接后续跳转网页;
2. 爬虫或浏览器劫持而产生的流量,不应该计入广告主的费用中。
3.5 淘客交易作弊
淘客交易作弊,不满足作弊流量转化概率为0的假设。根据计费方式不同,常见的2种作弊形式为:
1. 流量劫持
CPS计费下的主要作弊手法是流量劫持。常见的流量劫持有2种:
1. 篡改记录用户流量来源,将其他淘宝客的拉新流量据为己有。广告主会明显感知到自然流量变少,拉新流量增加。
2. 修改用户跳转链接,使得用户跳转到自己的宝贝页面,会导致用户在不知情的情况下购买了另一家店铺的商品。此时商家会在销量层面有一定感知。

2. 黑灰产淘客拉新
CPA计费下的主要问题是虚假地址。常见的CPA通常发生在产品拉新中,如用户注册、用户下单...等。在一些淘宝客拉新场景中,需要拉新用户完成注册、下单等一系列流程。此时一些淘宝客通过批量注册,下单廉价商品来赚取拉新差价。

除了虚拟类目以外,实体商品需要填写明确的收获地址。由于大量相同地址容易引起商家警觉,真实非本人地址可能引起快递机构的投诉,影响其后续结算。所以淘宝客往往会构造一些半真半假的虚假地址,用于收货。因此虚假地址的识别是该场景下的重点抓手之一。
3.6 下游任务影响
虚假流量不单影响着其他广告主的权益,同时影响着阿里生态的下游业务。搜索、推荐、广告等业务的收益,强依赖于其基于用户行为数据的在线学习。如:个性化推荐、点击率预估、流量分发、广告定价等。而当这些任务中混入虚假流量时,会对其真实线上的精度造成极大影响。
4. 算法实践
流量反作弊对于精度的要求尤其高,多过滤导致平台收益减少、少过滤引起广告主投诉,破坏投放生态。而且业务场景对实时返款的诉求越来越强烈,同时作弊对抗升级,从集中式、大规模转向分布式、稀疏化攻击,识别难度增大。亟需基于高维异常检查的新系统能力。为此,我们建立了集异常主动感知、人工洞察分析、自动处置过滤、客观评价高效循环一体的风控系统。

4.1 异常主动感知
在历史的风控体系中,往往是Case驱动的。即遇到问题通过滞后的算法或策略迭代来覆盖风险。为了提前发现问题,尽可能减少投诉,净化投放环境,引入了感知。通过感知捕捉与常见分布不同的数据,输出异常列表。将可感知异常流量分为:
1. 受害者可感知;
2. 平台可感知;
3. 实战攻防可感知;
4. 假想攻防可感知;
5. 算法挖掘可感知。
感知是重召回的,但并不是单纯为了更多地召回现有风险。它设计的核心是去感知所有的“异常”。以2020年初为例,由于骑行政策的调整,售卖头盔商家的访问量显著偏高,连带着必然影响到点击率、转化率等一系列指标。这些异常是商铺可感知的,需要被捕捉到,但并不属于作弊流量。所以不会被流量反作弊系统所过滤。
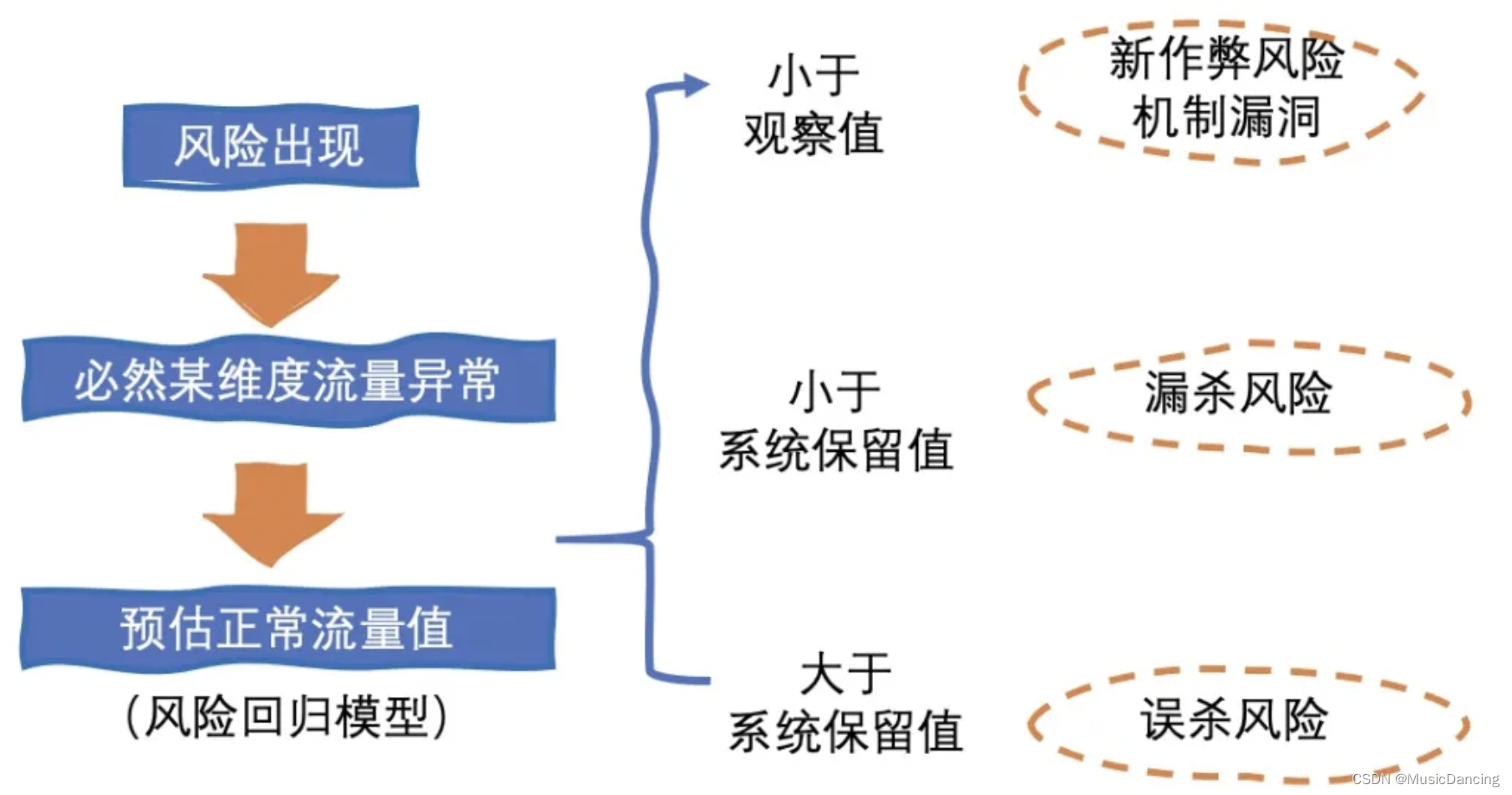
那感知究竟如何来做呢?以“点击流量反作弊”来说,作弊一定会导致点击量增加。如果可以预估出一个商品每天的点击数量,则超出该值的点击一定为作弊。因此流量反作弊感知的核心之一,就是如何在大盘召回率未知的情况下,精准预估正常流量值。
4.2 人工洞察分析
为了确认感知到的异常流量哪些属于作弊,分析人员需要进行洞察分析。“洞察 ”的目的是从“感知”到的异常中将风险抽离出来,进而发现新的风险模式。将洞察分为:
1. 受害者洞察;
2. 攻击者洞察;
3. 套利漏洞洞察;
3. 流量实例洞察。
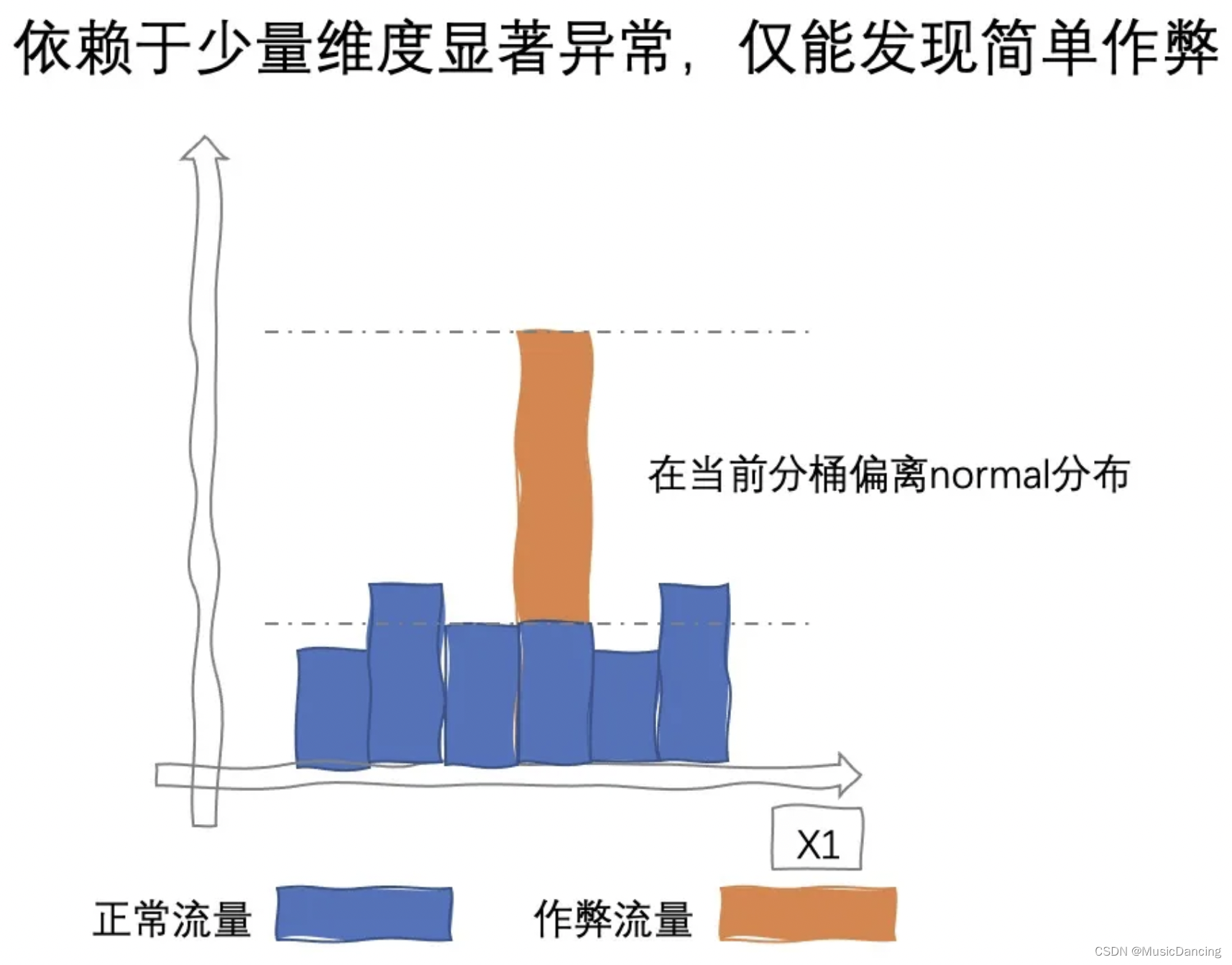
传统洞察需要人工挑选可疑特征(如停留时长、注册时长),并与大盘好样本进行比较。如下图。对领域经验有强依赖,而领域专家毕竟是少数,并且随着作弊越发高级,单一维度或少量维度下逐渐难以发现作弊。为此引入了高维数据下的可视化洞察分析技术。
在洞察环节,首先需要对样本进行高度抽象表示。如何在高维数据中选择合适的子空间投影,是非常具有挑战性的课题。后续文章会展开介绍。确定合适的子空间后,除了和大盘比较,我们还引入了时间维度的分布同比,如下图所示。对于分布稳定的某个广告,3月6日降维图中突然出现明显不同的一簇(红圈内),很可能是新的异常模式。(图中“样本库”指最终被识别为作弊的流量,在3.3节进行介绍)
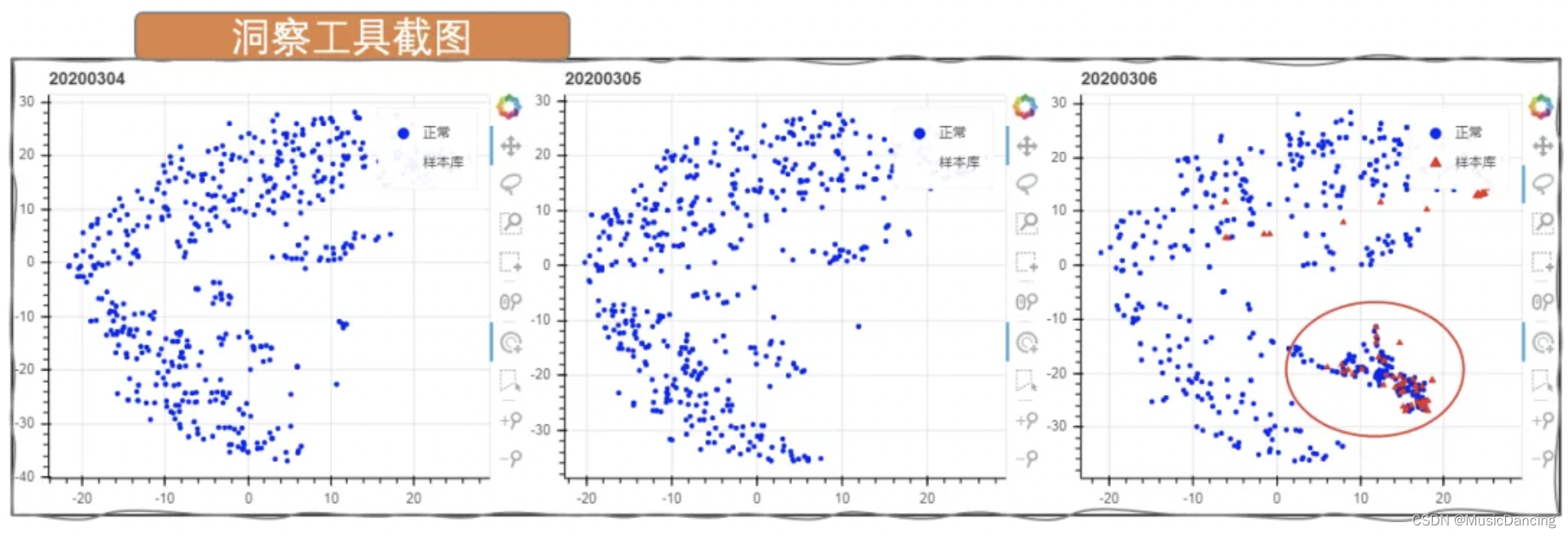
洞察的难点在于,如何减轻未召回的作弊对正常分布的污染。比如上图中蓝色线条内部分可能也存在作弊,这时通过同比就无法发现异常。如何跳出既有认知去召回未知异常模式,以及非常棘手的冷启动问题,这些都是后续文章的重点内容。
4.3 处置
指对风险进行处置,对于不同的风险实体、风险类型,会使用不同的处置方法。
3.3.1 流量反作弊的处置
4.4 客观评价
这篇关于流量反作弊算法简介的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








