本文主要是介绍mysql 5.7分组报错问题 Expression #1 of ORDER BY clause is not in GROUP BY clause,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
解决方案:
select version(),
@@sql_mode;SET sql_mode=(SELECT REPLACE(@@sql_mode,'ONLY_FULL_GROUP_BY',''));
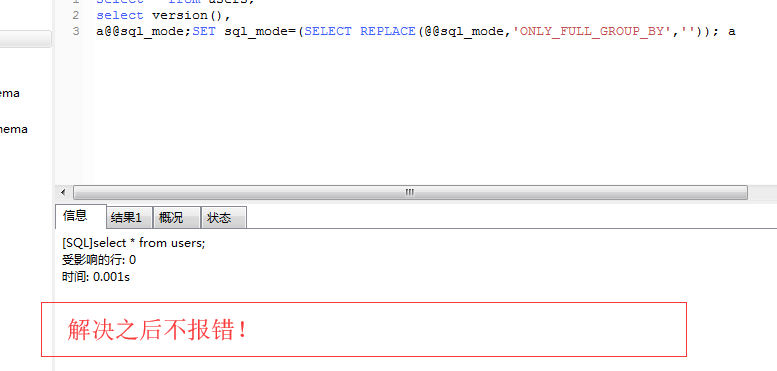
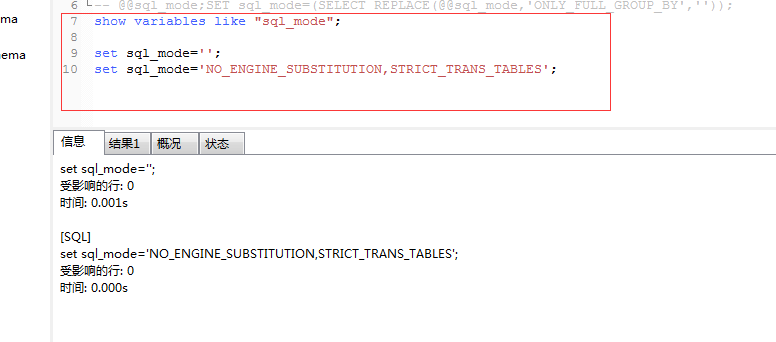
完美的解决方案是:
1 show variables like "sql_mode"; 2 3 set sql_mode=''; 4 set sql_mode='NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES';
ONLY_FULL_GROUP_BY 是 MySQL 中的一个 SQL 模式(SQL mode),它对 GROUP BY 语句的使用施加了更为严格的限制,以确保查询结果的确定性和一致性。启用此模式后,当在查询中使用 GROUP BY 子句时,只有被明确包含在 GROUP BY 子句中的列或使用聚合函数(如 COUNT(), SUM(), AVG(), MAX(), MIN() 等)处理的列才能出现在 SELECT 列表、HAVING 条件和 ORDER BY 子句中。这样可以避免由于未完全指定分组条件导致的不确定性和潜在错误。以下是关于 ONLY_FULL_GROUP_BY 的详细说明:
作用与目的:
防止数据不一致:在没有启用 ONLY_FULL_GROUP_BY 的情况下,某些数据库系统(如 MySQL 的某些版本,默认未开启该模式)可能允许在 GROUP BY 查询中选择未被明确分组的非聚合列。这种行为可能导致同一分组内返回任意行的值,从而产生不可预期的结果。
提升查询语义清晰度:启用此模式后,开发者必须显式指定所有出现在 SELECT、HAVING 或 ORDER BY 中的非聚合列,这有助于提高查询语句的可读性与维护性,确保其他开发人员或未来自己能清楚理解查询意图。
影响的查询结构:
SELECT 列表:只有被 GROUP BY 明确列出的列或使用聚合函数计算的表达式可以出现在 SELECT 列表中。
HAVING 条件:在 HAVING 子句中引用的列或表达式也必须遵循上述规则,即必须是分组列或聚合函数。
ORDER BY 子句:排序依据的列同样需要是分组列或聚合函数的结果。
启用与禁用:
启用:可以通过以下方式之一启用 ONLY_FULL_GROUP_BY 模式:
在 MySQL 配置文件(如 my.cnf 或 my.ini)的 [mysqld] 部分添加 sql_mode=ONLY_FULL_GROUP_BY,然后重启 MySQL 服务。
在运行时通过 SQL 命令动态设置(对当前会话生效):
总结来说,ONLY_FULL_GROUP_BY 是一个用于增强 SQL 查询语句严谨性和可预测性的 SQL 模式。启用它可以帮助避免因 GROUP BY 使用不当导致的数据不一致性和查询结果的不确定性。在编写涉及分组操作的 SQL 查询时,建议遵循 ONLY_FULL_GROUP_BY 规则,以确保查询的准确性和可维护性。
当然根据实际情况,如果要保留这种模式,那么就去修改相关的SQL 也是解决方案之一
这篇关于mysql 5.7分组报错问题 Expression #1 of ORDER BY clause is not in GROUP BY clause的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







