本文主要是介绍python实现将数据标准化到指定区间[a,b]+正向标准化+负向标准化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、公式介绍
(一)正向标准化公式
(二)负向标准化公式如下
(三)[a,b]取[0,1]的特例
二、构建数据集
三、自定义标准化函数
四、正向标准化
五、负向标准化
六、合并数据
一、公式介绍
将一列数据X标准化到指定区间[a,b]
(一)正向标准化公式
nor_X=(b-a)*(X-X_min)/(X_max-Xmin)+a
(二)负向标准化公式如下
nor_X=(b-a)*(Xmax-X)/(X_max-Xmin)+a
(三)[a,b]取[0,1]的特例
若[a,b]的取值为[0,1],
那么正向标准化公式就变为了如下:
nor_X=(X-X_min)/(X_max-Xmin)
负向标准化公式就变味了如下:
nor_X=(Xmax-X)/(X_max-Xmin)
也就是我们常用的在[0,1]区间的最大最小标准化
二、构建数据集
import pandas as pd
import numpy as np
#对医院进行综合分析
data=pd.DataFrame({'医院':['医院1', '医院2', '医院3', '医院4', '医院5', '医院6', '医院7', '医院8', '医院9', '医院10'],'门诊人数':[368107, 215654, 344914, 284220, 216042, 339841, 225785, 337457, 282917, 303455],'病床使用率%':[99.646, 101.961, 90.353, 80.39, 91.114, 98.766, 95.227, 88.157, 99.709, 101.392],'病死率%':[1.512, 1.574, 1.556, 1.739, 1.37, 1.205, 1.947, 1.848, 1.141, 1.308],'确诊符合率%':[99.108, 98.009, 99.226, 99.55, 99.411, 99.315, 99.397, 99.044, 98.889, 98.715],'平均住院日':[11.709, 11.24, 10.362, 12, 10.437, 10.929, 10.521, 11.363, 11.629, 11.328],'抢救成功率%':[86.657, 81.575, 79.79, 80.872, 76.024, 88.672, 87.369, 75.77, 78.589, 83.072]
})#令"医院"这一属性为索引列
data.set_index("医院",inplace=True)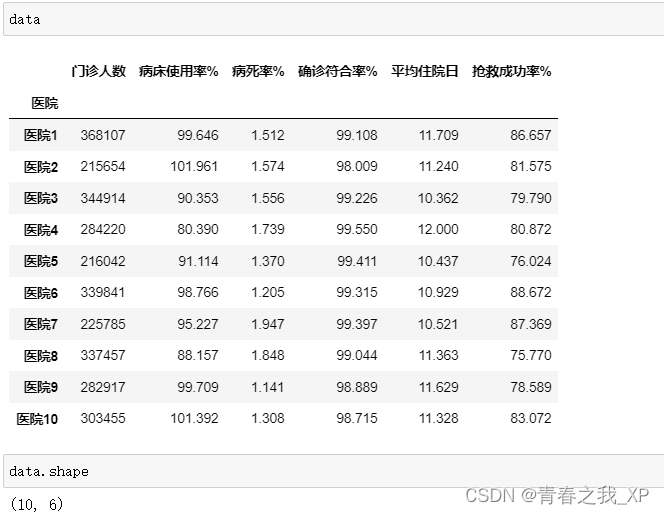
三、自定义标准化函数
def min_max_scaling(data, method='positive', feature_range=(0, 1)):'''Min-Max归一化处理参数:data (pd.DataFrame): 需要进行处理的数据框method (str): 归一化的方法,'positive' 为正向,'negative' 为逆向,默认为'positive'feature_range (tuple): 归一化后的最小最大值范围,默认为 (0, 1)返回:pd.DataFrame: 归一化后的数据框'''y_min, y_max = feature_range#y_min、y_max分别是归一化后数据的最小值 和最大值范围normalized_data = pd.DataFrame()#创建了一个名为normalized_data的空pandas DataFrame对象,可以向这个数据框中添加数据for col in data.columns:col_max = data[col].max()col_min = data[col].min()#获取DataFrame data 中每一列的最大值和最小值if method == 'negative':scaled_col = (y_max - y_min) * (col_max - data[col]) / (col_max - col_min) + y_min #这样是使数据映射到(y_min,y_max)区间#如果y_min=0,y_max=1,那么scaled_col = ((col_max - data[col]) / (col_max - col_min) 也就是到(0,1)区间的标准化映射了#下边的负向标准化同理#负向标准化elif method == 'positive':scaled_col = (y_max - y_min) * (data[col] - col_min) / (col_max - col_min) + y_min#正向标准化normalized_data[col] = scaled_col#将标准化后的数据增加到上边创建的空数据框中return normalized_data
#返回标准化后的数据框四、正向标准化
由数据可知,['门诊人数', '病床使用率%', '确诊符合率%', '抢救成功率%']这四列数据应该是正向指标,即数值越大越好。
# 正向指标标准化
positive_cols = ['门诊人数', '病床使用率%', '确诊符合率%', '抢救成功率%']
positive_normalized = min_max_scaling(data[positive_cols], method='positive', feature_range=(0.002, 1))
# positive_normalized = min_max_scaling(data[positive_cols], method='positive', feature_range=(0, 1))将数据进行标准化的区间为[0.002,1]
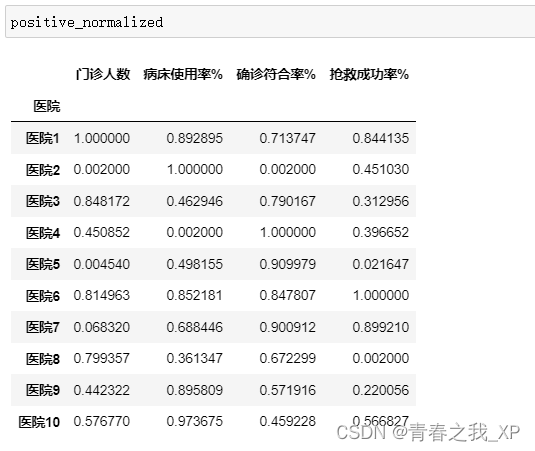
五、负向标准化
由数据可知,['病死率%', '平均住院日']这四列数据应该是负向指标,即数值越小越好。
# 负向指标标准化
negative_cols = ['病死率%', '平均住院日']
negative_normalized = min_max_scaling(data[negative_cols], method='negative', feature_range=(0.002, 1))
# negative_normalized = min_max_scaling(data[negative_cols], method='negative', feature_range=(0, 1))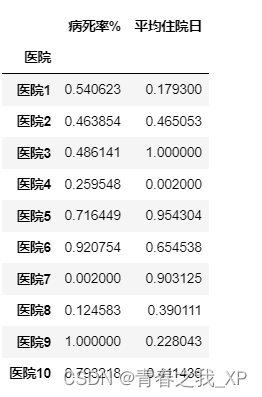
六、合并数据
# 数据合并且保持顺序
combined_normalized_data = positive_normalized.join(negative_normalized)
# combined_normalized_data = combined_normalized_data[data.columns]
# combined_normalized_data.index = data.index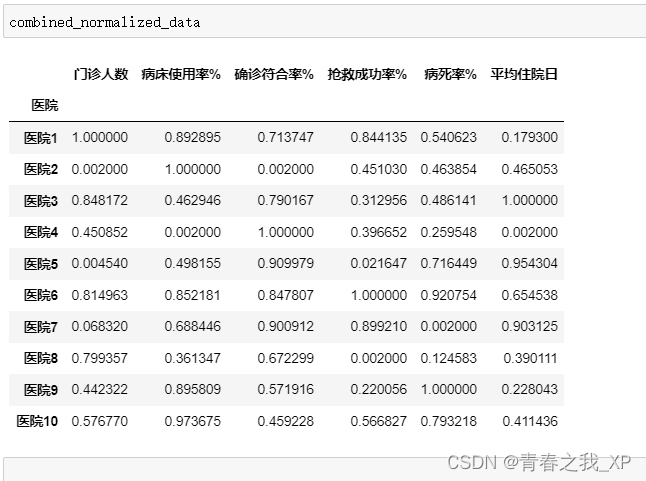
这篇关于python实现将数据标准化到指定区间[a,b]+正向标准化+负向标准化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


