本文主要是介绍Netapp数据恢复—误删除Netapp存储中lun的数据恢复案例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
NetApp存储数据恢复环境:
NetApp FAS某型号存储,该NetApp存储中有96块扇区大小是520字节的SAS硬盘。存储中的lun都映射给小型机使用,存放Oracle数据库文件,采用ASM裸设备存储方式。
NetApp存储故障:
工作人员误操作删除了该NetApp存储上所有lun。
和工作人员沟通后得知:由于业务需要,需要重新规划该NetApp存储的存储空间,工作人员直接把存储卷全部删除并重新分配。在完成卷的删除但还没有重新分配的时候,上层业务宕机。运维工程师紧急排查故障情况,发现跑业务的服务器上的磁盘都“消失”了,无法访问数据。
NetApp存储数据恢复过程:
1、北亚企安数据恢复工程师到达现场后将该NetApp存储中每块磁盘编号后取出,由硬件工程师初步检测没有发现有硬盘存在明显硬件故障,都可以正常读取。于是以只读方式将每块磁盘做扇区级全盘镜像,镜像完成后按照编号将所有磁盘还原到该NetApp存储中。后续的数据分析和数据恢复操作都基于镜像文件进行,避免对原始磁盘数据造成二次破坏。
2、分析Netapp存储的存储过程。
a、分析盘序和LVM的组成方式。
b、扫描硬盘内的所有节点,一般只扫描MBFI(用户节点)。
c、在节点扫描结果中找到文件大小符合需求的节点,提取此节点并判断索引根;
d、根据索引根内的第一级数据指针提取本文件的所有直接数据指针(需要参考节点中0x03位置的MAP深度,为0x00时直接从节点内提取数据,0x01时需要提取一次MAP,0x02时需要提取两次MAP......)。指针提取完毕后开始提取文件数据。
3、在硬盘靠前扇区的位置找到超级块相关信息,从超级块相关信息中获取磁盘组名字、磁盘组逻辑起始块号、总块数、磁盘组中raid的编号。
netapp超级块: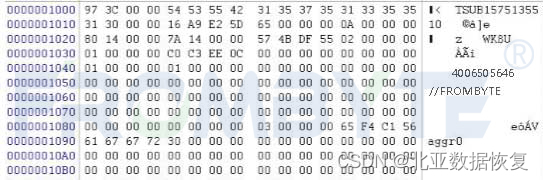
4、每个数据块占8个扇区,数据块后附加64字节数据块的描述信息。根据这些信息可以判断出作为校验盘的磁盘(提取数据需剔除校验盘)。
校验块描述信息样例:
5、根据每块磁盘8号扇区的磁盘信息以及磁盘末尾的RAID盘序表确定盘序。首先确定各个磁盘所属aggr组,然后再判断组内盘序。数据指针跳转时不考虑校验盘,所以只需要取得数据盘的盘序即可。
netapp盘序表: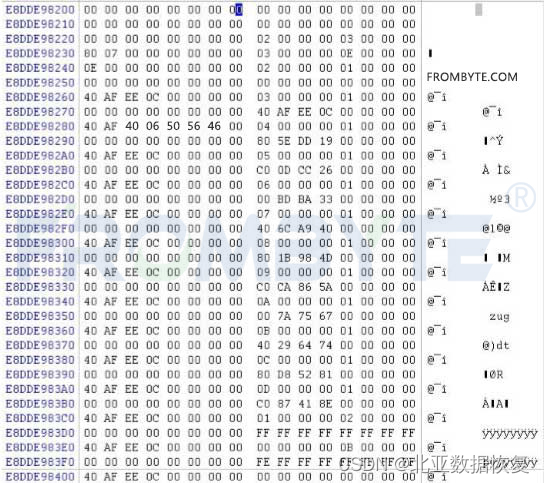
6、Netapp的节点分布在数量众多的数据块内,数据块内节点被统一组织为节点组。每个节点组的前半部分字节记录一些系统数据,后半部分字节记录各个文件节点。根据用户级别可将文件节点分为两类:“MBFP”系统文件节点和“MBFI”用户文件节点,在数据恢复时一般只需要MBFI节点组即可。
netapp节点样例图:
7、获取目录项,并根据其节点编号找到对应节点。
目录项信息:
8、完成对NetApp存储的存储结构的分析后,使用北亚企安自主开发的NetApp解析程序提取数据, 解析asm文件系统并提取出数据库文件。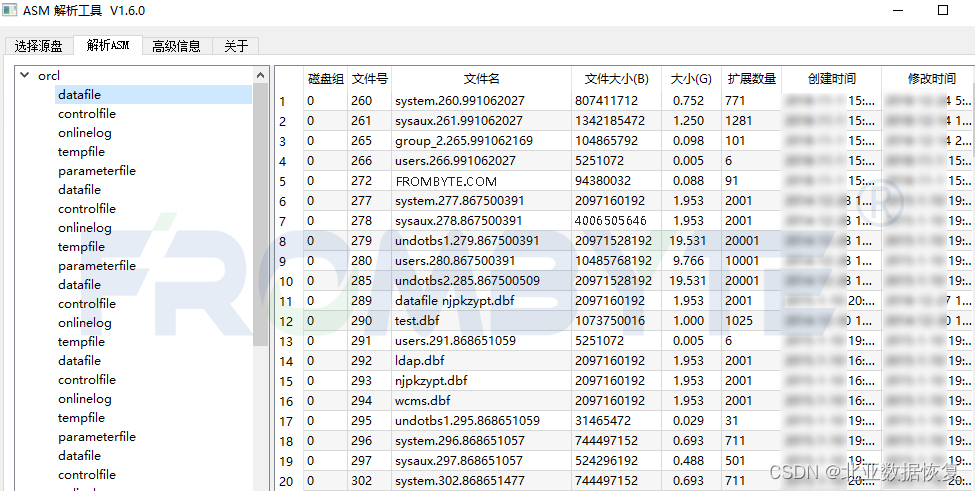
9、搭建小机环境,安装oracle数据库,检测数据库文件和备份文件。
a、通过提取出的数据库文件启动数据库,数据库可以正常启动。
b、检测数据库备份文件,筛选出最新的数据库备份文件,使用筛选出的备份文件还原数据库。经过用户验证后,确认恢复出来的数据库文件无误,本次数据恢复工作完成。
这篇关于Netapp数据恢复—误删除Netapp存储中lun的数据恢复案例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







