本文主要是介绍CUDA编程---线程束洗牌指令,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
从Kepler系列的GPU(计算能力为3.0或更高)开始,洗牌指令(shuffle instruction)作为一种机制被加入其中,只要两个线程在相同的线程束中,那么就允许这两个线程直接读取另一个线程的寄存器。
洗牌指令使得线程束中的线程彼此之间可以直接交换数据,而不是通过共享内存或全局内存来进行的。洗牌指令比共享内存有更低的延迟,并且该指令在执行数据交换时不消耗额外的内存。因此,洗牌指令为应用程序快速交换线程束中线程间的数据提供了一个有吸引力的方法。
束内线程
首先介绍一下束内线程(lane)的概念。简单来说,一个束内线程指的是线程束内的单一线程。线程束中的每个束内线程是[0,31]范围内束内线程索引(lane index)的唯一标识。线程束中的每个线程都有一个唯一的束内线程索引,并且同一线程块中的多个线程可以有相同的束内线程索引(就像同一网格中的多个线程可以有相同的threadIdx.x值一样)。然而,束内线程索引没有内置变量,因为线程索引有内置变量。在一维线程块中,对于一个给定线程的束内线程索引和线程束索引可以按以下公式进行计算:

例如,线程块中的线程1和线程33都有束内线程ID 1,但它们有不同的线程束ID。对于二维线程块,可以将二维线程坐标转换为一维线程索引,并应用前面的公式来确定束内线程和线程束的索引。
线程束洗牌指令的不同形式
有两组洗牌指令:一组用于整型变量,另一组用于浮点型变量。每组有4种形式的洗牌指令。在线程束内交换整型变量,其基本函数标记如下:
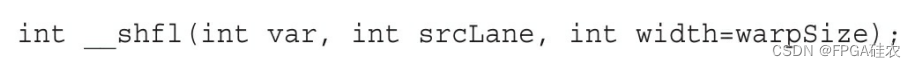
内部指令__shfl返回值是var,var通过由srcLane确定的同一线程束中的线程传递给__shfl。srcLane的含义变化取决于宽度值。这个函数能使线程束中的每个线程都可以直接从一个特定的线程中获取某个值。线程束内所有活跃的线程都同时产生此操作,这将导致每个线程中有4字节数据的移动。
变量width可被设置为2~32之间2任何的指数(包括2和32),这是可选择的。当设置为默认的warpSize(即32)时,洗牌指令跨整个线程束来执行,并且srcLane指定源线程的束内线程索引。然而,设置width允许将线程束细分为段,使每段包含有width个线程,并且在每个段上执行独立的洗牌操作。对于不是32的其他width值,线程的束内线程ID和其在洗牌操作中的ID不一定相同。在这种情况下,一维线程块中的线程洗牌ID可以按以下公式进行计算:

例如,如果shfl被线程束中的每个线程通过以下参数调用:
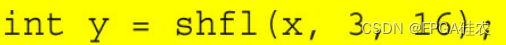
那么线程0~15将从线程3接收x的值,线程16~31将从线程19接收x的值(在线程束的前16个线程中其偏移量为3)。为了简单起见,srcLane将被称为在本节的其余部分提到过的束内线程索引。
当传递给shfl的束内线程索引与线程束中所有线程的值相同时,指令从特定的束内线程到线程束中所有线程都执行线程束广播操作,如下图所示:
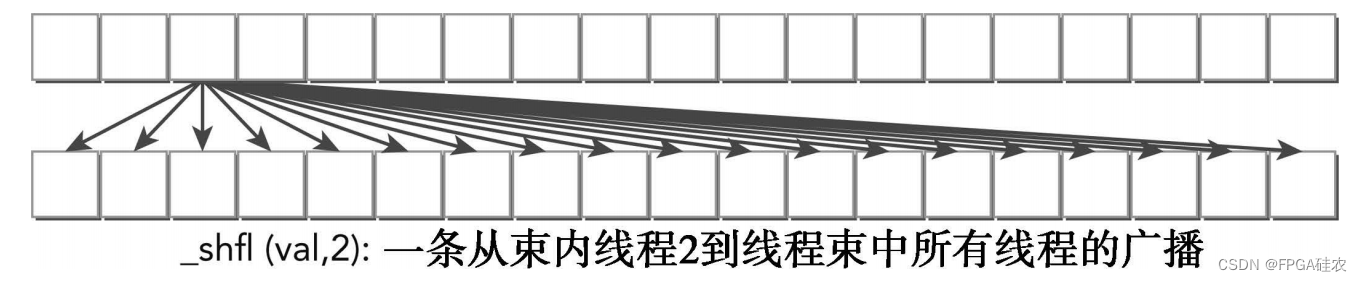
洗牌操作的另一种形式是从与调用线程相关的线程中复制数据:

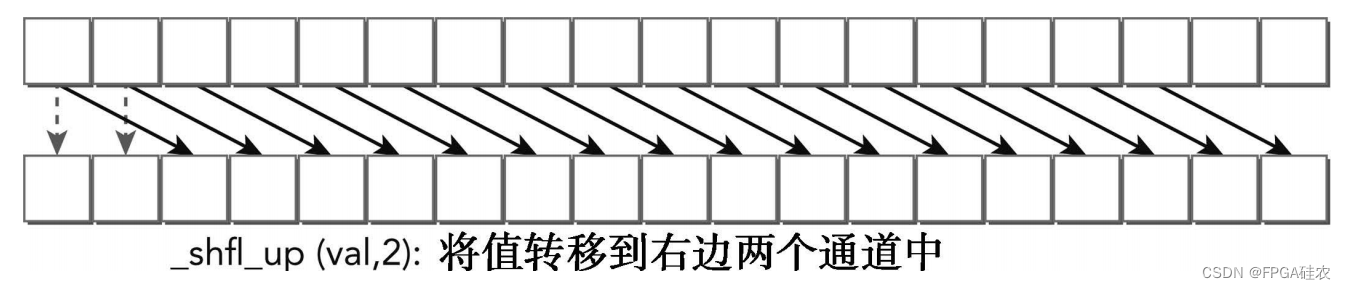
__shfl_up通过减去调用的束内线程索引delta来计算源束内线程索引。返回由源线程所持有的值。因此,这一指令通过束内线程delta将var右移到线程束中。__shfl_up周围没有线程束,所以线程束中最低的线程delta将保持不变,如图所示。
相反,洗牌指令的第三种形式是从相对于调用线程而言具有高索引值的线程中复制:

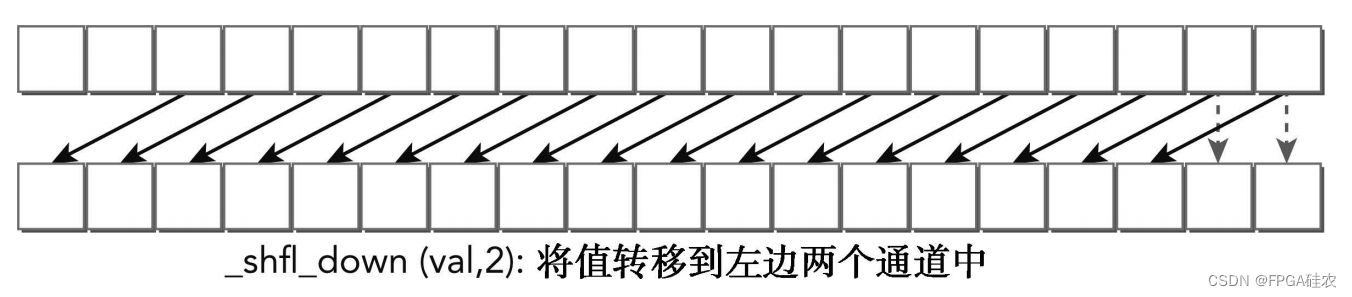
__shfl_down通过给调用的束内线程索引增加delta来计算源束内线程索引。返回由源线程持有的值。因此,该指令通过束内线程delta将var的值左移到线程束中。使用__shfl_down时周围没有线程束,所以线程束中最大的束内线程delta将保持不变,如图所示。
洗牌指令的最后一种形式是根据调用束内线程索引自身的按位异或来传输束内线程中的数据:

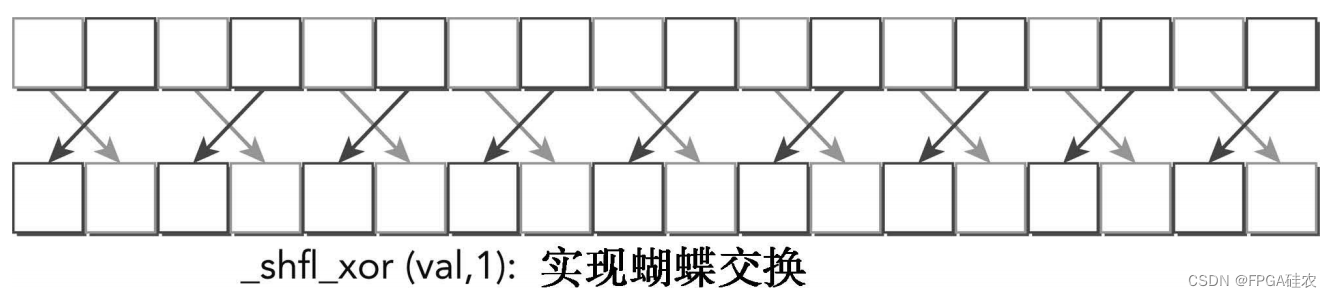
通过使用laneMask执行调用束内线程索引的按位异或,内部指令可计算源束内线程索引。返回由源线程持有的值。该指令适合于蝴蝶寻址模式(a butterfly addressing pattern),如图所示。
洗牌函数还支持单精度浮点值。浮点洗牌函数采用浮点型的var参数,并返回一个浮点数。
线程束内的共享数据
跨线程束值的广播
下面的内核实现了线程束级的广播操作。每个线程都有一个寄存器变量value。源束内线程由变量srcLane指定,它等同于跨所有线程。每个线程都直接从源线程复制数据。

为了简单起见,使用有16个线程的一维线程块:

调用内核的方法如下。通过第三个参数test_shfl_broadcast将源束内线程设置为每个线程束内的第三个线程。全局内存的两片被传递到内核:输入数据和输出数据。
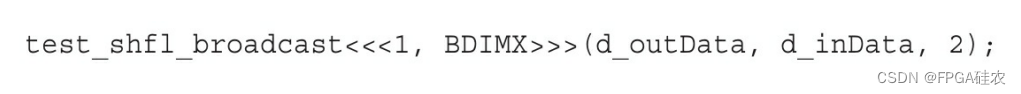
调用后的结果如下:

线程束内上移
下面的内核实现了洗牌上移的操作。线程束中每个线程的源束内线程都是独一无二的,并由它自身的线程索引减去delta来确定。

通过指定delta为2调用核函数:
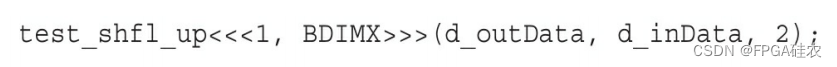
其结果是,每个线程的值向右移动两个束内线程,结果如下所示。最左边的两个束内线程值保持不变。

线程束内下移
下面的内核实现了下移操作。线程束中每个线程的源束内线程都是独一无二的,并由它自身的线程索引加上delta来确定。

通过指定delta为2调用核函数:
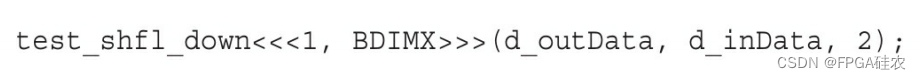
每个线程的值向左移动两个束内线程,结果如下所示。最右边的两个束内线程值保持不变。

线程束内环绕移动
下面的核函数实现了跨线程束的环绕移动操作。每个线程的源束内线程是不同的,并由它自身的束内线程索引加上偏移量来确定。偏移量可为正数也可为负数。

通过指定一个正偏移量来调用内核,代码如下:
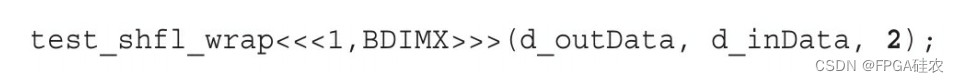
这个内核实现了环绕式左移操作,如下所示。不同于由test_shfl_down产生的结果,最右边的两个束内线程的值也变化了。

跨线程束的蝴蝶交换
下面的内核实现了两个线程之间的蝴蝶寻址模式,这是通过调用线程和线程掩码确定的。

调用掩码值为1的内核将导致相邻的线程交换它们的值。
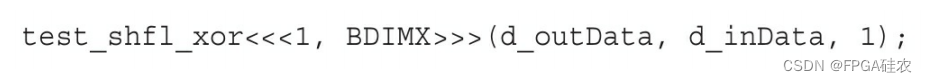
这个内核启动的输出如下:

使用线程束洗牌指令的并行归约
一个线程块中可能有几个线程束。对于线程束级归约来说,每个线程束执行自己的归约。每个线程不使用共享内存,而是使用寄存器存储一个从全局内存中读取的数据元素:
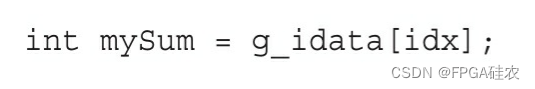
线程束级归约作为一个内联函数实现,如下所示:

在这个函数返回之后,每个线程束的总和保存到基于线程索引和线程束大小的共享内存中,如下所示:

对于线程块级归约,先同步块,然后使用相同的线程束归约函数将每个线程束的总和进行相加。之后,由线程块产生的最终输出由块中的第一个线程保存到全局内存中,如下所示:

对于网格级归约,g_odata被复制回到执行最终归约的主机中。下面是完整的reduceShfl核函数:

这篇关于CUDA编程---线程束洗牌指令的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






