本文主要是介绍获取公募基金持仓【数据分析系列博文】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
从指定网址获取公募基金持仓数据,快速解析并存储数据。
(该博文针对自由学习者获取数据;而在投顾、基金、证券等公司,通常有Wind、聚源、通联等厂商采购的数据)
1. 导入必要的库:
pandas 用于数据处理和操作。
requests 用于发送 HTTP 请求并获取响应。
re 用于正则表达式的匹配,用来从网页源代码中提取所需数据。
sqlalchemy 用于数据库操作。
pymysql 用于连接 MySQL 数据库。2. 定义请求头部信息:
包括 Accept、Accept-Encoding、Accept-Language、Cache-Control、Connection、Cookie、Host、Referer 和 User-Agent。这些信息模拟了浏览器向服务器发送请求的情况,以防止被服务器拒绝或误认为是爬虫。3. 主程序逻辑:
使用 requests.get() 方法发送 HTTP GET 请求获取网页源代码。 使用
response.raise_for_status() 检查请求是否成功,若出现 HTTP 错误则抛出异常。
使用正则表达式从网页源代码中提取股票名称、代码、占比、持股数和持股市值等信息,并将其保存到 DataFrame 中。 对于
DataFrame 中的数据,去除其中的逗号并将其转换为浮点数类型。 在 DataFrame 中插入基金代码和日期信息。 将处理后的
DataFrame 数据写入 MySQL 数据库中。
4. 异常处理:
捕获 requests.exceptions.RequestException 异常,以处理可能的网络请求异常。
源码
import pandas as pd
import requests
import re
import sqlalchemy
import pymysql"""desc: 采集公募基金十大重仓author: xiong
"""headers = {"Accept": "*/*","Accept-Encoding": "gzip, deflate, br, zstd","Accept-Language": "zh-CN,zh;q=0.9","Cache-Control": "no-cache","Connection": "keep-alive","Cookie": "st_si=58097080196087; st_asi=delete; qgqp_b_id=7443897b6898879ff2ccc867c516cf28; EMFUND1=null; EMFUND2=null; EMFUND3=null; EMFUND4=null; EMFUND5=null; EMFUND6=null; EMFUND7=null; ASP.NET_SessionId=ara523stptbsluodcwpalkrv; searchbar_code=001323; EMFUND0=null; EMFUND8=04-17%2000%3A04%3A19@%23%24%u4E1C%u5434%u79FB%u52A8%u4E92%u8054%u6DF7%u5408C@%23%24002170; EMFUND9=04-17 00:05:09@#$%u4E1C%u5434%u79FB%u52A8%u4E92%u8054%u6DF7%u5408A@%23%24001323; st_pvi=04007721649495; st_sp=2022-12-16%2010%3A38%3A55; st_inirUrl=https%3A%2F%2Fwww.1234567.com.cn%2F; st_sn=81; st_psi=2024041722594817-112200305283-3132686277","Host": "fundf10.eastmoney.com","Referer": "https://fundf10.eastmoney.com/ccmx_002170.html","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36"
}if __name__ == '__main__':print(f'-------------------------开始爬取基金十大重仓股-----------------------')fund_code = "002170"year = 2024month = 1url = f'https://fundf10.eastmoney.com/FundArchivesDatas.aspx?type=jjcc&code={fund_code}&topline=10&year={year}&' \f'month={month}&rt=0.5428172332180803' \try:# 1. 爬取数据response = requests.get(url=url, headers=headers)response.raise_for_status() # Raises an exception for HTTP errorsprint(f'-------------------------1. 成功爬取数据-----------------------')# 使用正则表达式提取股票名称、代码、占比、持股数、持股市值matches = re.findall(r'href=.*?>(\d+)</a></td><td class=\'tol\'><a.*?>(.*?)</a></td><td class=\'tor\'><span.*?></span></td>'r'<td class=\'tor\'><span.*?></span></td><td class=\'xglj\'><a.*?>.*?</a><a.*?>.*?</a><a.*?>.*?</a></td>'r'<td class=\'tor\'>(.*?)</td><td class=\'tor\'>(.*?)</td><td class=\'tor\'>(.*?)</td></tr>',response.text)fund_top_ten_df = pd.DataFrame(matches, columns=['GPDM', 'GPMC', 'CCZB', 'CCS', 'CCSZ'])# 数据包含了逗号,去掉逗号并转换为浮点数fund_top_ten_df['CCS'] = fund_top_ten_df['CCS'].str.replace(',', '').astype(float)fund_top_ten_df['CCSZ'] = fund_top_ten_df['CCSZ'].str.replace(',', '').astype(float)fund_top_ten_df.insert(0, 'FCODE', fund_code)fund_top_ten_df.insert(6, 'TDATE', str(year)+'-'+str(month))print(fund_top_ten_df)print(f'-------------------------2. 完成解析数据-----------------------')# 3. 数据入库pymysql.install_as_MySQLdb()engine: sqlalchemy.engine.Engine = sqlalchemy.create_engine('mysql://root:282013@localhost/xjjjj?charset=utf8', pool_size=50, pool_recycle=200)fund_top_ten_df.to_sql('fund_top_ten', con=engine, if_exists='append', index=False)print(f'-------------------------3. 完成数据入库-----------------------')except requests.exceptions.RequestException as e:print(f"Error fetching data: {e}")数据库
-- ----------------------------
-- Table structure for fund_top_ten
-- ----------------------------
DROP TABLE IF EXISTS `fund_top_ten`;
CREATE TABLE `fund_top_ten` (`FCODE` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '基金代码',`GPDM` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL DEFAULT '' COMMENT '股票代码',`GPMC` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '股票名称',`CCZB` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '持仓占比',`CCS` double(16, 8) DEFAULT NULL COMMENT '持仓数(万股)',`CCSZ` double(16, 8) DEFAULT NULL COMMENT '持仓市值(万元)',`TDATE` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci DEFAULT NULL COMMENT '状态日期'
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;SET FOREIGN_KEY_CHECKS = 1;
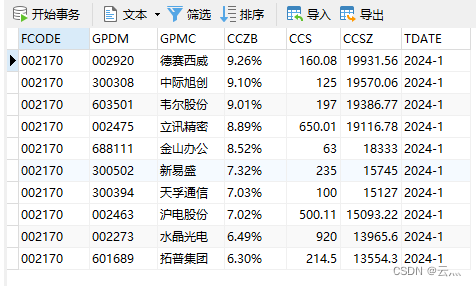
结果

预告
下一期:待定
这篇关于获取公募基金持仓【数据分析系列博文】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



