本文主要是介绍SQL255 给出employees表中排名为奇数行的first_name,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
题目来源:
给出employees表中排名为奇数行的first_name_牛客题霸_牛客网
描述
对于employees表中,输出first_name排名(按first_name升序排序)为奇数的first_name
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,PRIMARY KEY (`emp_no`));如,输入为:
INSERT INTO employees VALUES(10001,'1953-09-02','Georgi','Facello','M','1986-06-26');
INSERT INTO employees VALUES(10002,'1964-06-02','Bezalel','Simmel','F','1985-11-21');
INSERT INTO employees VALUES(10005,'1955-01-21','Kyoichi','Maliniak','M','1989-09-12');
INSERT INTO employees VALUES(10006,'1953-04-20','Anneke','Preusig','F','1989-06-02');
输出格式:
| first |
| Georgi |
| Anneke |
请你在不打乱原序列顺序的情况下,输出:按first_name排升序后,取奇数行的first_name。
如对以上示例数据的first_name排序后的序列为:Anneke、Bezalel、Georgi、Kyoichi。
则原序列中的Georgi排名为3,Anneke排名为1,所以按原序列顺序输出Georgi、Anneke。
drop table if exists `employees` ;
CREATE TABLE `employees` (`emp_no` int(11) NOT NULL,`birth_date` date NOT NULL,`first_name` varchar(14) NOT NULL,`last_name` varchar(16) NOT NULL,`gender` char(1) NOT NULL,`hire_date` date NOT NULL,PRIMARY KEY (`emp_no`));
INSERT INTO employees VALUES(10001,'1953-09-02','Georgi','Facello','M','1986-06-26');
INSERT INTO employees VALUES(10002,'1964-06-02','Bezalel','Simmel','F','1985-11-21');
INSERT INTO employees VALUES(10005,'1955-01-21','Kyoichi','Maliniak','M','1989-09-12');
INSERT INTO employees VALUES(10006,'1953-04-20','Anneke','Preusig','F','1989-06-02');
解决
解决方案一:
先用row_number()对first_name排序,再利用mod()函数取出奇数行,这样取出的行里面的first_name就是我们要的了,由于要返回的是初始的排序状态,所以我们再套一层select直接从employees表取first_name,只要这里的first_name在我们上面取出的first_name里面就好了:
select e.first_name from employees e
where e.first_name in
(select a.first_name as first_name from
(select first_name,ROW_NUMBER() over(order by first_name) as rk
from employees) a
where mod(a.rk,2)!=0);解决方案二:
mysql> select m1.first_name from-> (select e1.first_name,count(*) as 'rowid' from-> employees e1-> left join employees e2-> on e1.first_name >= e2.first_name-> group by e1.first_name ) as m1-> where m1.rowid % 2 = 1;
+------------+
| first_name |
+------------+
| Georgi |
| Anneke |
+------------+
2 rows in set (0.01 sec)以下是我解题过程:
在我的查询中,我使用了 JOIN 条件 e1.first_name >= e2.first_name,这意味着查询返回的结果中,e1 表中的每一行都会与 e2 表中所有满足条件的行进行连接,找出小于等于他名字的计数。连接的结果不再按照原表的顺序排列,而是根据连接条件的满足程度和其他优化因素来确定最终的顺序。 (这是gpt说的)
mysql> select e1.first_name,count(*) from-> employees e1-> join employees e2-> on e1.first_name >= e2.first_name-> group by e1.first_name;
+------------+----------+
| first_name | count(*) |
+------------+----------+
| Kyoichi | 4 |
| Georgi | 3 |
| Bezalel | 2 |
| Anneke | 1 |
+------------+----------+
4 rows in set (0.00 sec)mysql>
mysql> select e1.first_name,count(e1.first_name) from-> employees e1-> join employees e2-> on e1.first_name >= e2.first_name-> group by e1.first_name;
+------------+----------------------+
| first_name | count(e1.first_name) |
+------------+----------------------+
| Kyoichi | 4 |
| Georgi | 3 |
| Bezalel | 2 |
| Anneke | 1 |
+------------+----------------------+
4 rows in set (0.00 sec)但是这样查出来的 数据改变了数据的顺序: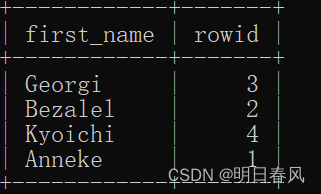
mysql> select first_name from employees;
+------------+
| first_name |
+------------+
| Georgi |
| Bezalel |
| Kyoichi |
| Anneke |
+------------+
4 rows in set (0.00 sec)mysql> select e1.first_name from-> employees e1-> join employees e2-> on e1.first_name >= e2.first_name-> group by e1.first_name;
+------------+
| first_name |
+------------+
| Kyoichi |
| Georgi |
| Bezalel |
| Anneke |
+------------+
4 rows in set (0.00 sec)mysql> select e1.first_name from-> employees e1-> join employees e2-> on e1.first_name >= e2.first_name;
+------------+
| first_name |
+------------+
| Kyoichi |
| Georgi |
| Kyoichi |
| Bezalel |
| Georgi |
| Kyoichi |
| Anneke |
| Kyoichi |
| Bezalel |
| Georgi |
+------------+
10 rows in set (0.00 sec)为了不改变表中的数据顺序,所以我想到了左连接,把e1表当作主表,外连接的功能就是把主表中的数据全部查出来,副表中没有一条数据与之匹配上的,就用null字段代替,且分组函数自动忽略null值:
mysql> select e1.first_name from-> employees e1-> left join employees e2-> on e1.first_name >= e2.first_name;
+------------+
| first_name |
+------------+
| Georgi |
| Georgi |
| Georgi |
| Bezalel |
| Bezalel |
| Kyoichi |
| Kyoichi |
| Kyoichi |
| Kyoichi |
| Anneke |
+------------+
10 rows in set (0.00 sec)
mysql> select * from-> employees e1-> left join employees e2-> on e1.first_name >= e2.first_name;
+--------+------------+------------+-----------+--------+------------+--------+------------+------------+-----------+--------+------------+
| emp_no | birth_date | first_name | last_name | gender | hire_date | emp_no | birth_date | first_name | last_name | gender | hire_date |
+--------+------------+------------+-----------+--------+------------+--------+------------+------------+-----------+--------+------------+
| 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 | 10006 | 1953-04-20 | Anneke | Preusig | F | 1989-06-02 |
| 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 | 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 |
| 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 | 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 |
| 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 | 10006 | 1953-04-20 | Anneke | Preusig | F | 1989-06-02 |
| 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 | 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 |
| 10005 | 1955-01-21 | Kyoichi | Maliniak | M | 1989-09-12 | 10006 | 1953-04-20 | Anneke | Preusig | F | 1989-06-02 |
| 10005 | 1955-01-21 | Kyoichi | Maliniak | M | 1989-09-12 | 10005 | 1955-01-21 | Kyoichi | Maliniak | M | 1989-09-12 |
| 10005 | 1955-01-21 | Kyoichi | Maliniak | M | 1989-09-12 | 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 |
| 10005 | 1955-01-21 | Kyoichi | Maliniak | M | 1989-09-12 | 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 |
| 10006 | 1953-04-20 | Anneke | Preusig | F | 1989-06-02 | 10006 | 1953-04-20 | Anneke | Preusig | F | 1989-06-02 |
+--------+------------+------------+-----------+--------+------------+--------+------------+------------+-----------+--------+------------+
10 rows in set (0.00 sec)mysql> select * from-> employees e1-> left join employees e2-> on e1.first_name > e2.first_name;
+--------+------------+------------+-----------+--------+------------+--------+------------+------------+-----------+--------+------------+
| emp_no | birth_date | first_name | last_name | gender | hire_date | emp_no | birth_date | first_name | last_name | gender | hire_date |
+--------+------------+------------+-----------+--------+------------+--------+------------+------------+-----------+--------+------------+
| 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 | 10006 | 1953-04-20 | Anneke | Preusig | F | 1989-06-02 |
| 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 | 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 |
| 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 | 10006 | 1953-04-20 | Anneke | Preusig | F | 1989-06-02 |
| 10005 | 1955-01-21 | Kyoichi | Maliniak | M | 1989-09-12 | 10006 | 1953-04-20 | Anneke | Preusig | F | 1989-06-02 |
| 10005 | 1955-01-21 | Kyoichi | Maliniak | M | 1989-09-12 | 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 |
| 10005 | 1955-01-21 | Kyoichi | Maliniak | M | 1989-09-12 | 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 |
| 10006 | 1953-04-20 | Anneke | Preusig | F | 1989-06-02 | NULL | NULL | NULL | NULL | NULL | NULL |
+--------+------------+------------+-----------+--------+------------+--------+------------+------------+-----------+--------+------------+
7 rows in set (0.00 sec)现在就跟这个顺序一样了:
最终代码:
mysql> select m1.first_name from-> (select e1.first_name,count(*) as 'rowid' from-> employees e1-> left join employees e2-> on e1.first_name >= e2.first_name-> group by e1.first_name ) as m1-> where m1.rowid % 2 = 1;
+------------+
| first_name |
+------------+
| Georgi |
| Anneke |
+------------+
2 rows in set (0.01 sec)改进的方案二:
方案一虽然能通过,其实并不完美,因为方案一没有问题的前提是employees 中的first_name没有重名的,如果我加了一条重名字的数据进去,就出问题了:
mysql> INSERT INTO employees VALUES(10007,'1953-09-02','Georgi','Facello','M','1986-06-26');
Query OK, 1 row affected (0.01 sec)没执行insert操作前: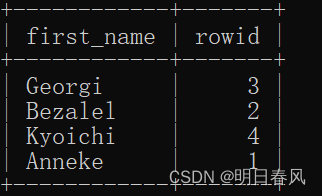
如果你要像方案二一样通过join两张表来获得排名,那就必须去重, 要不然Georgi 为8,意味着小于等于他名字的有八个,这不就摇身一变,变成了名字最大的了吗
执行了insert操作后:
mysql> select e1.first_name,count(*) as 'rowid' from-> employees e1-> left join employees e2-> on e1.first_name >= e2.first_name-> group by e1.first_name ;
+------------+-------+
| first_name | rowid |
+------------+-------+
| Georgi | 8 |
| Bezalel | 2 |
| Kyoichi | 5 |
| Anneke | 1 |
+------------+-------+
4 rows in set (0.00 sec)原因如下:
mysql> select * from-> employees e1-> left join employees e2-> on e1.first_name >= e2.first_name;
+--------+------------+------------+-----------+--------+------------+--------+------------+------------+-----------+--------+------------+
| emp_no | birth_date | first_name | last_name | gender | hire_date | emp_no | birth_date | first_name | last_name | gender | hire_date |
+--------+------------+------------+-----------+--------+------------+--------+------------+------------+-----------+--------+------------+
| 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 | 10007 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 |
| 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 | 10006 | 1953-04-20 | Anneke | Preusig | F | 1989-06-02 |
| 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 | 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 |
| 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 | 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 |
| 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 | 10006 | 1953-04-20 | Anneke | Preusig | F | 1989-06-02 |
| 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 | 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 |
| 10005 | 1955-01-21 | Kyoichi | Maliniak | M | 1989-09-12 | 10007 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 |
| 10005 | 1955-01-21 | Kyoichi | Maliniak | M | 1989-09-12 | 10006 | 1953-04-20 | Anneke | Preusig | F | 1989-06-02 |
| 10005 | 1955-01-21 | Kyoichi | Maliniak | M | 1989-09-12 | 10005 | 1955-01-21 | Kyoichi | Maliniak | M | 1989-09-12 |
| 10005 | 1955-01-21 | Kyoichi | Maliniak | M | 1989-09-12 | 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 |
| 10005 | 1955-01-21 | Kyoichi | Maliniak | M | 1989-09-12 | 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 |
| 10006 | 1953-04-20 | Anneke | Preusig | F | 1989-06-02 | 10006 | 1953-04-20 | Anneke | Preusig | F | 1989-06-02 |
| 10007 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 | 10007 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 |
| 10007 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 | 10006 | 1953-04-20 | Anneke | Preusig | F | 1989-06-02 |
| 10007 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 | 10002 | 1964-06-02 | Bezalel | Simmel | F | 1985-11-21 |
| 10007 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 | 10001 | 1953-09-02 | Georgi | Facello | M | 1986-06-26 |
+--------+------------+------------+-----------+--------+------------+--------+------------+------------+-----------+--------+------------+
16 rows in set (0.00 sec)mysql>
mysql> select e1.first_name from-> employees e1-> left join employees e2-> on e1.first_name >= e2.first_name;
+------------+
| first_name |
+------------+
| Georgi |
| Georgi |
| Georgi |
| Georgi |
| Bezalel |
| Bezalel |
| Kyoichi |
| Kyoichi |
| Kyoichi |
| Kyoichi |
| Kyoichi |
| Anneke |
| Georgi |
| Georgi |
| Georgi |
| Georgi |
+------------+
16 rows in set (0.00 sec)我们需要联合两个字段去重:
mysql> select distinct e1.first_name ,e2.first_name #distinct去掉重名的-> from employees e1-> left join employees e2-> on e1.first_name >= e2.first_name;
+------------+------------+
| first_name | first_name |
+------------+------------+
| Georgi | Georgi |
| Georgi | Anneke |
| Georgi | Bezalel |
| Bezalel | Anneke |
| Bezalel | Bezalel |
| Kyoichi | Georgi |
| Kyoichi | Anneke |
| Kyoichi | Kyoichi |
| Kyoichi | Bezalel |
| Anneke | Anneke |
+------------+------------+
10 rows in set (0.00 sec)mysql> select count(*) as rowid,m1.first_name from-> (->-> select distinct e1.first_name , e2.first_name as name-> from employees e1-> left join employees e2-> on e1.first_name >= e2.first_name-> ) as m1 group by m1.first_name;
+-------+------------+
| rowid | first_name |
+-------+------------+
| 3 | Georgi |
| 2 | Bezalel |
| 4 | Kyoichi |
| 1 | Anneke |
+-------+------------+
4 rows in set (0.01 sec)最终答案:
mysql> select m2.first_name from-> (select count(*) as rowid,m1.first_name from-> (->-> select distinct e1.first_name , e2.first_name as name-> from employees e1-> left join employees e2-> on e1.first_name >= e2.first_name-> ) as m1 group by m1.first_name)as m2 where m2.rowid % 2 = 1;
+------------+
| first_name |
+------------+
| Georgi |
| Anneke |
+------------+
2 rows in set (0.00 sec)
这篇关于SQL255 给出employees表中排名为奇数行的first_name的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






