本文主要是介绍数据传承:多元环境下的HDFS文件上传与配置调优探索,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 主要内容
- 代码1部分
- 代码2部分
- 代码3部分
主要内容
完成windows上传文件到hdfs以及linux上传文件(集群中的节点、非集群中的节点)到hdfs文件的功能。尝试在程序中可以通过configuration对象配置分块大小,副本数等属性,观察不同配置文件对程序执行结果的影响。
例如:linux上传/usr/test文件夹的内容到hdfs的/myusr文件夹中。
【选择尝试】输出/myusr/test下的文件内容,输出信息:路径、文件名、所有者、是否是文件,块文件大小和块存储信息
代码1部分
该代码作用是 设置属性+本地文件上传到hdfs的文件中
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;public class testwinhdfs {public static void main(String[] args) throws Exception {Configuration conf = new Configuration();
//根据运行需要设置或不设置属性conf.set("fs.defaultFS", "hdfs://192.168.222.171:9000");System.out.println(conf.get("fs.defaultFS"));conf.set("dfs.replication","1");conf.set("dfs.blocksize","64M");FileSystem fs=FileSystem.get(conf);
//根据运行需要选择正确的文件路径fs.copyFromLocalFile(new Path("/usr/test/wr.txt"),new Path("/user"));fs.close();}
}
代码2部分
代码作用是:创建一些方法,创建目录,子目录,删除目录,修改文件名
import java.util.Arrays;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.BlockLocation;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.RemoteIterator;public class localwrdir {
static Configuration conf;
static FileSystem fs;
public static void main(String args[]) throws Exception{getinit();//testcreatedir();//testmksubdir();//testdeldir();//testrenamedir();showall();//依次调用其他的方法 //例如:testcreatedir();
}public static void getinit() throws Exception{conf = new Configuration();//可以根据访问hdfs的要求设置fs.defaultFSfs = FileSystem.get(conf);}public static void testcreatedir() throws Exception {//创建目录Path p = new Path("E:/dst2");fs.mkdirs(p);fs.close();}public static void testmksubdir()throws Exception{//创建子目录Path p = new Path("E:/dst2/subdir");fs.mkdirs(p);fs.close();}public static void testdeldir()throws Exception{//删除目录及子目录Path p = new Path("E:/dst2");//第二个参数为是否级联(递归)删除,false为否,如果文件夹不为空则抛出异常IOExceptionfs.delete(p,true);fs.close(); }public static void testrenamedir()throws Exception{//修改文件夹名字Path p = new Path("E:/dst1");Path p2 = new Path("E:/mynewfolder");fs.rename(p, p2);}public static void showall()throws Exception{//显示文件元数据信息Path p = new Path("E:/mynewfolder");RemoteIterator<LocatedFileStatus> locatedStatus = fs.listLocatedStatus(p);//使用FileSystem对象的listLocatedStatus方法获取路径p下所有文件的状态迭代器//istFiles(p, true);while(locatedStatus.hasNext()){ //循环遍历所有文件状态LocatedFileStatus next = locatedStatus.next(); //获取下一个文件的状态BlockLocation[] blockLocations = next.getBlockLocations(); // 获取文件的块位置信息long blockSize = next.getBlockSize();//文件块的大小Path path = next.getPath();//文件的路径String name = path.getName();//文件的名称Path suffix = path.suffix("E:/mynewfolder/");String sufstring = suffix.toString();//带有后缀的路径转换为字符串String pathstring = path.toString();//文件路径转换为字符串String groupstr = next.getGroup();//获取文件所属的用户组boolean isfile = next.isFile();//检查当前状态是否为文件String owner = next.getOwner();//获取文件的所有者System.out.println(sufstring+":-------------- "+pathstring+"\t\t"+name+"\t"+owner+"\t"+isfile+"\t"+blockSize/1024/1024+"\t"+Arrays.toString(blockLocations)); }}
}
代码3部分
import java.util.Arrays;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.BlockLocation;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.LocatedFileStatus;
import org.apache.hadoop.fs.Path;
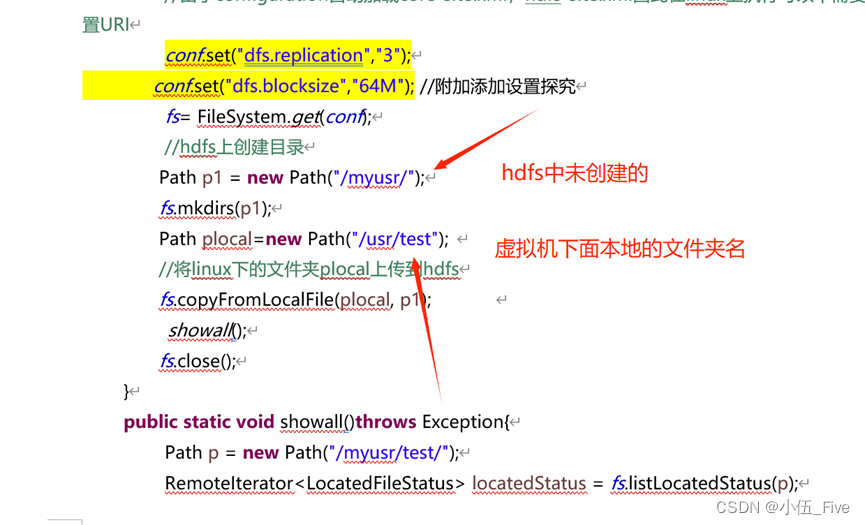
import org.apache.hadoop.fs.RemoteIterator;public class linuxwrdir {static Configuration conf= new Configuration();static FileSystem fs;public static void main(String[] args) throws Exception {//由于configuration自动加载core-site.xml,hdfs-site.xml因此在linux上执行可以不需要设置URIconf.set("dfs.replication","3");conf.set("dfs.blocksize","64M"); //附加添加设置探究fs= FileSystem.get(conf);//hdfs上创建目录Path p1 = new Path("/myusr/");fs.mkdirs(p1);Path plocal=new Path("/usr/test"); //将linux下的文件夹plocal上传到hdfsfs.copyFromLocalFile(plocal, p1); showall();fs.close();}public static void showall()throws Exception{Path p = new Path("/myusr/test/");RemoteIterator<LocatedFileStatus> locatedStatus = fs.listLocatedStatus(p);System.out.println("—————————locatedstatus——————————");while(locatedStatus.hasNext()){LocatedFileStatus next = locatedStatus.next();BlockLocation[] blockLocations = next.getBlockLocations();long blockSize = next.getBlockSize();Path path = next.getPath();String name = path.getName();//Path suffix = path.suffix("/usr/dst/");//String sufstring = suffix.toString();String pathstring = path.toString();String groupstr = next.getGroup();boolean isfile = next.isFile();String owner = next.getOwner();System.out.println(pathstring+"\t"+name+"\t"+owner+"\t"+isfile+"\t"+blockSize/1024/1024+"\t"+Arrays.toString(blockLocations)); }System.out.println("——————————status————");FileStatus[] listStatus = fs.listStatus(p);for (int i = 0; i < listStatus.length; i++) {String filename = listStatus[i].getPath().getName();long len = listStatus[i].getLen();boolean directory = listStatus[i].isDirectory();System.out.println(filename+"\t"+len+"\t"+directory);}}
}
代码打包
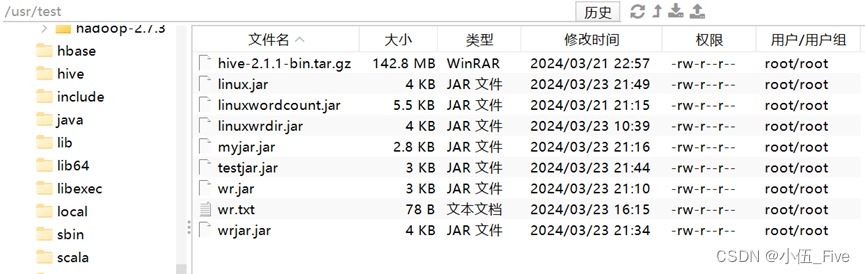
文件下加入文件:(按照要求,创建一些文件或文件夹,最好有超过128M或64M的文件,方便后面查看结果)
然后就是jar命令运行,和上面一样:
Hadoop jar jar包名 包名.类名
成功后,
打开浏览器
找50070
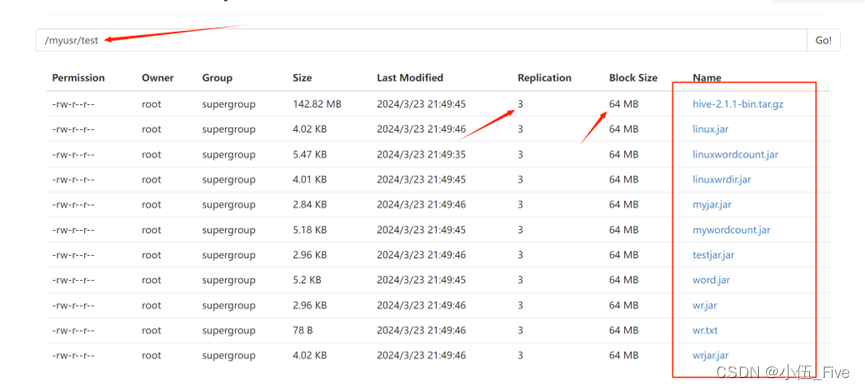
找到输出文件路径:
发现文件全部上传,且分块数量和块大小和代码设定一致,探究成功!
至此,全部完成!
这篇关于数据传承:多元环境下的HDFS文件上传与配置调优探索的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






