本文主要是介绍论文复现---MUTANT,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

Robust anomaly detection for multivariate time series through
temporal GCNs and attention-based VAE

基于时序神经网络和基于注意力的VAE的多变量时间序列鲁棒异常检测

https://github.com/Coac-syf/MUTANT

* numpy==1.21.2* torch==1.9.1* scipy==1.7.1* scikit-learn==0.24.2* pandas==0.25.0* tqdm==4.62.3* git+https://github.com/thu-ml/zhusuan.git* git+https://github.com/haowen-xu/tfsnippet.git@v0.2.0-alpha1
要求python 3+版本,其中pandas安装不上,我采用的默认版本。

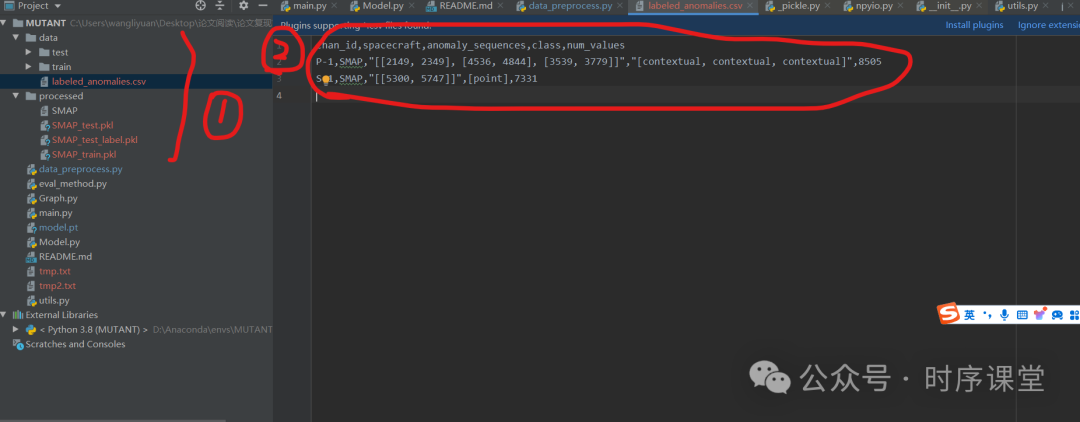
首先下载数据集并放入创建的data目录下,即可。这里复现的数据集是SMAP数据集,这里由于作者电脑性能不足删除了部分数据集,如圈2展示。数据集下载可参考:
时序数据集---SMAP&MSL

-
运行data_preprocess.py文件,会在processed目录下生成对应的3个.pkl文件。
-
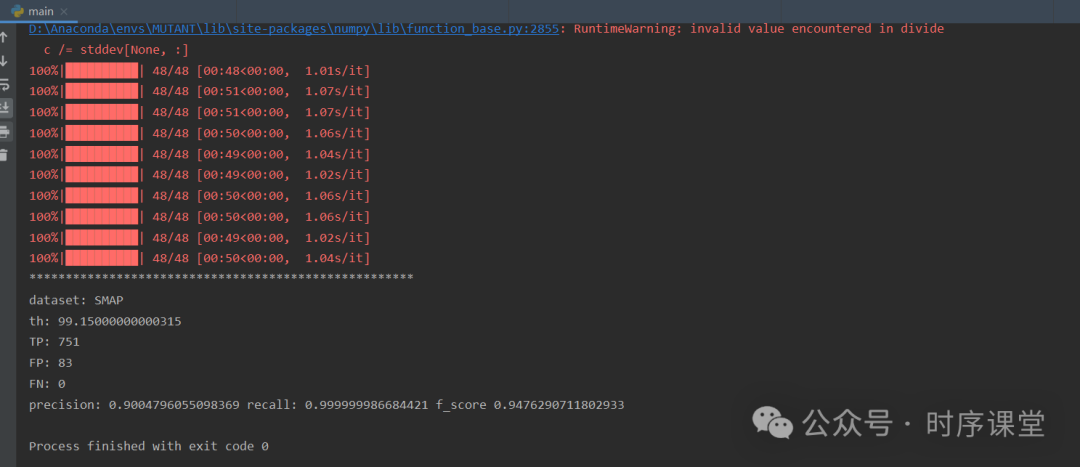
运行main.py

https://github.com/ldxdy/MUTANT
这篇关于论文复现---MUTANT的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)

