本文主要是介绍Locust压测框架入门,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
首先客套的来介绍一些Locust是啥:
Locust是一个容易使用、分布式的压力测试工具。它是用于网站压力测试(或其它系统)并找出多少用户一个系统可以承载。
在测试过程中,策略就是一个Locust的蠕虫将会攻击你的网站。每一个locust的行为(或你使用的测试用户)是你自己定义的,并且蠕虫进程从一个网页视图中被实时监测。这样会帮助你来实现测试,在真实用户使用前定义系统的瓶颈。
Locust是完全基于事件的,因此可以在单台机器中支持数以千计的用户在线。和其它基于事件的程序相比较,它是不需要使用回调的。相反,它通过gevent使用轻量级的进程。每一个locust测试你的网站时,实际上是真实的在内部运行它自己的进程(或greenlet,准确的说)。这样就允许你不使用复杂的回调方法,而是使用Python编写复杂的场景。
关于Locust:
1、locust作为一款性能测试工具,没有单独的ui界面,可以说是python下的一些库的集成
locust完全基于python作为编程语言,采用pure python描述测试脚本,其中的http请求也是完全基于Requests库,除了HTTP/HTTPS协议,locust也可以测其他协议的系统,只需要采用python调用对应的库进行请求描述即可,可以说python对应的库还是非常齐全的。
2、与jmeter相比较而言,locust更加的轻量化,采用的是不同于jmeter中进程和线程的处理机制(协程【微线程】),有效避免了系统的资源调度,由此可以大幅度的提高单击系统的并发能力
3、Github地址:
https://github.com/locustio/locust
注:如果想查看python下依赖了哪些库的话,可以进入github,点击setup.py进入查看
上述标红的地方就是依赖的第三方库及支持版本(详细的介绍见下方),安装这些库的时候也应遵循其显示的版本号,如果与当前支持的版本号不一致或者小于当前版本号的时候就会安装失败。
4、locust组成模块(所依赖的库)【gevent】是python下实现协程的一个第三方库,能够使系统获取极高的并发性能(locust基础模块)
简而言之,它的特点就是协程,web管理工具,超级好用。
第一步,安装
依然是老伙伴pip工具(完美安装依赖)
pip install Locust

Locust有六个依赖的python模块
1.gevent:在Python中实现协程的第三方库。协程又叫微线程Corouine。使用gevent可以获取极高的并发能力;
2.flask:Python的一个web开发框架,和django相当;
3.requests:支持http/https访问的库;
4.msgpack-python:一种快速、紧凑的二进制序列化格式,使用与类似json的数据;
5.six:提供了一些简单的工具封装Python2和Python3 之间的差异;
6.pyzmq:安装这个第三方库,可以把Locust运行在多个进程或多个机器(分布式)
安装结束了之后我们就开启Locust之旅了。
第二步,使用
如何快速的创建一个Locust Demo。
from locust import HttpLocust, TaskSet, task
class UserBehavior(TaskSet):
"Locust任务集,定义每个lucost的行为"
@task(1) # 任务的权重为1,如果有多个任务,可以将权重值定义成不同的值,
def get_root(self):
"模拟发送数据"
response = self.client.get('/Hello', name='get_root')
if not response.ok:
print(response.text)
response.failure('Got wrong response')
class TestLocust(HttpLocust):
"""自定义Locust类,可以设置Locust的参数。"""
task_set = UserBehavior
host = "https://www.baidu.com" # 被测服务器地址
min_wait = 5000
# 最小等待时间,即至少等待多少秒后Locust选择执行一个任务。
max_wait = 9000
# 最大等待时间,即至多等待多少秒后Locust选择执行一个任务。
首先需要导入locust模块里面的三个方法,HttpLocust,TaskSet,task
1、创建一个类继承自TaskSet,表示在这个类里面都是Locust的任务,这个类就算Loucst的任务集:
2、创建任务,创建任务其实就算定义一个方法,需要注意的是,这个方法上面多了一个task的装饰器,这个装饰器是用来标是定义的这个方法会被locust识别成它需要做的任务,task装饰器后面会有参数,如果执行单任务的时候,后面这个权重随便写上什么数字都无所谓,这个数字其实就是一个权重值,但是如果有多个任务的情况下,这个时候权重值就会起作用了。
来吃个栗子:
@task(1)
def index1(self):
r=self.client.get('/test/index.html')
print(r.text)
@task(2)
def search1(self):
r=self.client.get('/test/search.html')
print(r.text)
如有index1和search2分别设置权重1、2,如果测试时指定9个模拟用户数,那么会有3个模拟用户数执行index1任务,有6个模拟用户数执行search2任务。
简而言之可以把这个权重理解为执行次数的多少,数值越大,执行的频率就越高。
3、进入测试阶段,需要创建测试类继承自HttpLocust。
在这个类中只需要将刚刚创建的任务集类实例化,并且提供一个服务器的地址就可以进行使用了。
这里还有两个设置参数介绍一下:
min_wait : 最小等待时间,即至少等待多少秒后Locust选择执行一个任务。
max_wait :最大等待时间,即最多等待多少秒后Locust选择执行一个任务。
编写完demo后,我们就可以运行代码了。
运行的时候并不是直接运行,需要在终端键入这样的指令:
locust - f locu.py --logfile = locustfile.log
其中locu.py就是你刚刚编写的demo文件,--logfile就是log日志生成的地方。
我们运行一下代码:

之后就可以打开locust了
在浏览器中输入地址:
http://localhost:8089/
你会看到这样的页面
输入两组数据,第一个是你需要访问的最大总数,第二个是你在同一时间访问的最大数量(并发)
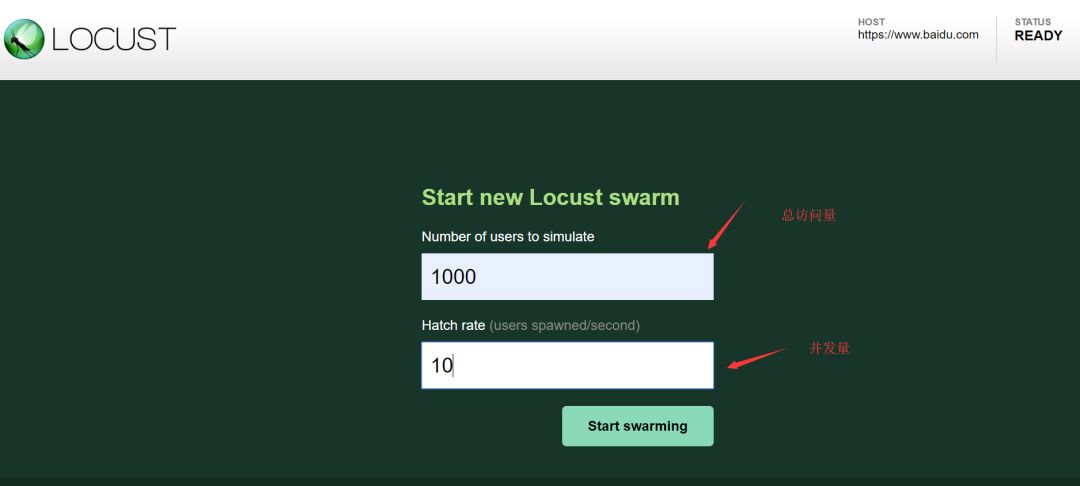
输入完之后就进入测试了:
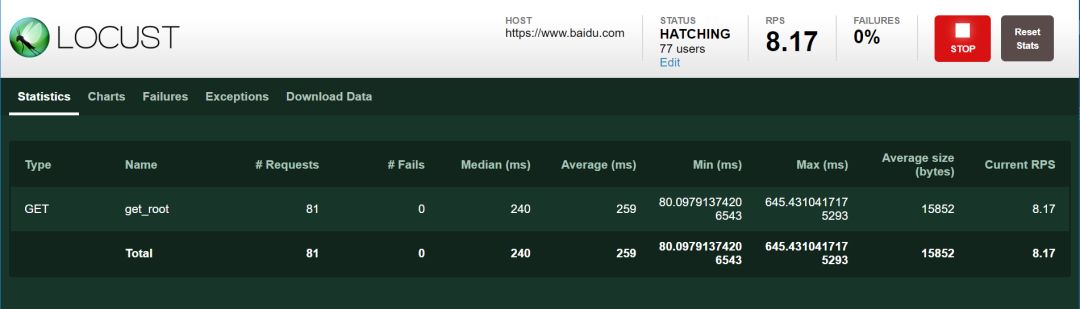

我们看图介绍一下数据:
Type 访问类型
Name 任务名(python中定义的方法名)
Requests 请求的总次数
Fails 失败的次数
Median (ms) 中间数耗时
Average (ms) 平均耗时
Min (ms) 最低耗时
Max (ms) 最大耗时
Average size (bytes) 平均耗时
Current RPS 每秒钟处理的访问的次数
这就是locust最基本的使用方法和用途了!

"Follow It"
这篇关于Locust压测框架入门的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





