本文主要是介绍高效可扩展,使用Dask进行大数据分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大家好,Dask技术作为并行计算领域的创新力量,正在重塑大数据的处理模式。这项开源项目为Python语言带来了强大的并行计算能力,突破了传统数据处理在扩展性和性能上的瓶颈。
本文将介绍Dask的发展历程、架构设计,并分析其在大数据分析和并行计算中的重要影响,以及Dask在推动数据处理技术进步中的关键作用。
1.Dask的演变:填补数据处理的空白
Dask的推出,旨在突破数据分析的瓶颈,传统Python库如NumPy和Pandas在处理数据时受到单机内存限制的制约。面对数据量指数级增长的挑战,市场对可扩展和分布式计算的需求愈发强烈。
Dask应运而生,它不仅能有效处理超出单机内存的大数据集,还能在多核心处理器上高效分配并行任务,为大规模数据分析提供了创新的解决方案。
2.架构:Dask如何促进并行计算
Dask的核心优势在于其动态任务调度和执行机制。不同于传统的静态并行计算模型,Dask通过构建任务图来规划计算流程,实现了任务的灵活调度和执行。这一策略优化了计算资源的使用效率,因为Dask能够智能地安排执行顺序,并在多个任务与处理器之间合理分配内存资源。
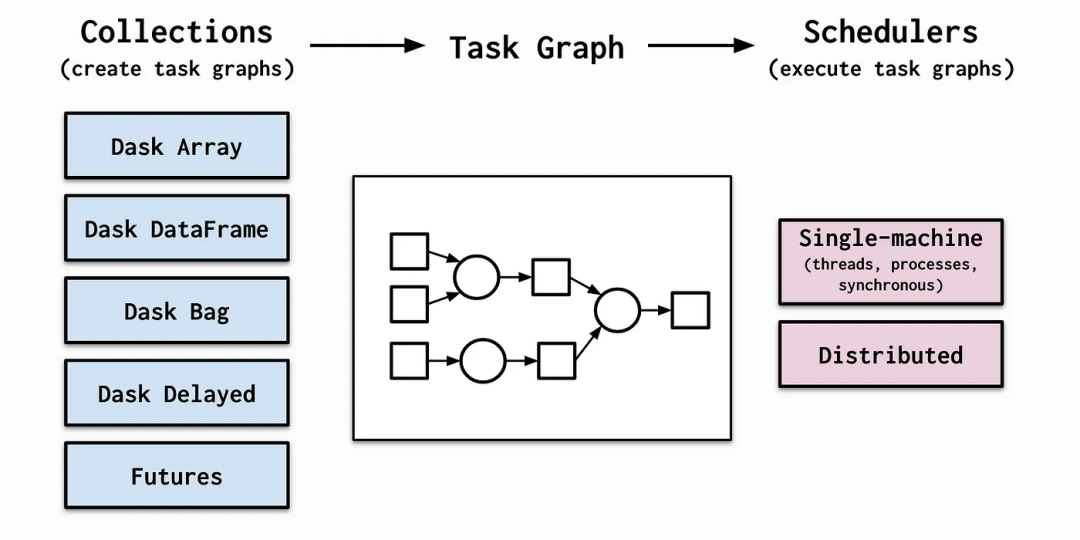
Dask推出了一系列API,这些API不仅复刻了Python中Pandas和NumPy库的核心功能,还进一步地提升了它们的处理能力。
例如,Dask DataFrame API在Pandas的基础上进行了优化,专门针对分布式计算场景,让开发者能够处理那些单台机器内存无法容纳的庞大数据集。同样地,Dask Array API在NumPy的基础上增加了对大规模分布式数组的处理能力。
这些API保持了与Pandas和NumPy一致的语法结构和操作特性,极大简化了用户从Pandas和NumPy向Dask迁移的过程,同时降低了学习成本。
3.对大数据处理和并行计算的重要影响
Dask对大数据处理和并行计算的影响是深远的。通过支持高效、可扩展的计算,Dask赋予了机构和研究者处理和分析庞大数据集的能力。这种能力对于各个领域都至关重要,无论是在科学研究中处理常见的大数据集,还是在工业界利用大数据进行洞察和决策。
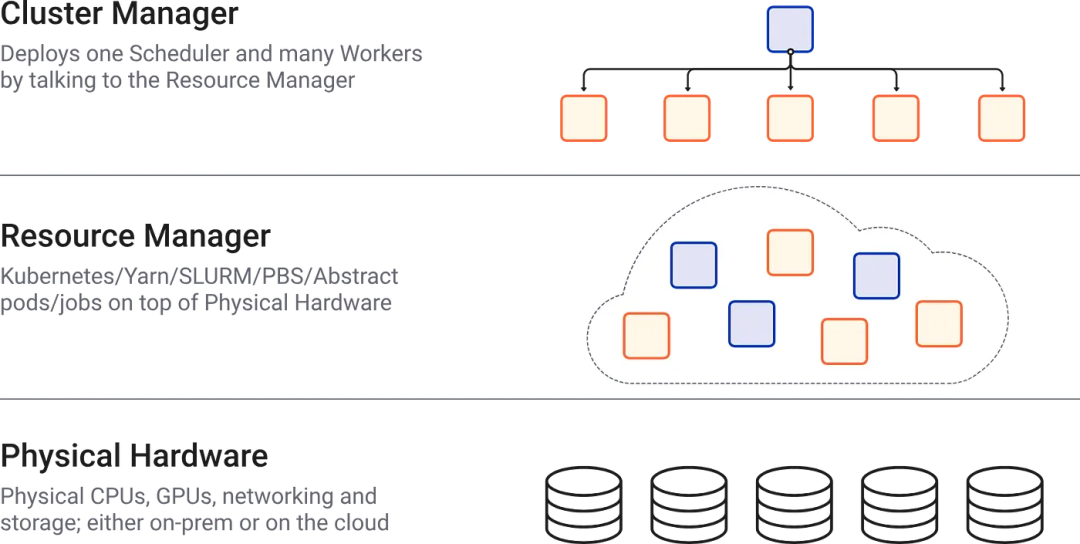
此外,Dask通过与云存储和计算服务等大数据技术的融合,进一步提升了其实用性和适应性。这种融合不仅优化了云环境中的数据处理和分析流程,还为数据驱动的研究和应用开辟了更广阔的前景。
4.Dask运用示例
这里提供一个完整的示例,展示如何运用Dask来生成合成数据集、开展特征工程、计算数据指标、绘制图表以及对结果进行解释。
在这个示例中,假设已经安装好了Dask及其所有依赖项,同时还安装了用于数据处理和图形绘制的pandas、numpy和matplotlib库。
import dask.dataframe as dd
import numpy as np
import pandas as pd
from dask.diagnostics import ProgressBar
import matplotlib.pyplot as plt# 创建合成数据集
data = {'feature1': np.random.rand(10000) * 100,'feature2': np.random.rand(10000) * 100,'target': np.random.randint(0, 2, 10000)
}
df = pd.DataFrame(data)
ddf = dd.from_pandas(df, npartitions=10)# 特征工程:基于现有特征创建新特征
ddf['feature3'] = ddf['feature1'] / (ddf['feature2'] + 1)# 计算一些指标
mean_feature1 = ddf['feature1'].mean()
mean_feature2 = ddf['feature2'].mean()
correlation = ddf[['feature1', 'feature2']].corr().compute()# 绘制特征分布图
with ProgressBar():ddf[['feature1', 'feature2', 'feature3']].compute().hist(bins=50)plt.show()# 显示结果
print("Feature 1的平均值:", mean_feature1.compute())
print("Feature 2的平均值:", mean_feature2.compute())
print("Feature 1和Feature 2之间的相关性:")
print(correlation)# 解释
# 直方图显示了每个特征的值分布。
# 平均值给出了特征的中心趋势的概念。
# 相关性矩阵提供了特征间关系的看法。
在上述代码块中:
-
使用
dask.dataframe以并行、分布式的方式处理数据集。 -
创建了一个包含两个特征和一个二元目标列的合成数据集。
-
从现有特征中工程化了一个新的特征(
feature3)。 -
计算了
feature1和feature2的平均值以及它们之间的相关性。 -
生成图表以可视化特征的分布。
-
打印结果,并提供简要解释。
这个示例展示了Dask的基本工作流程,包括数据操作、计算和可视化。特征工程、指标计算和解释的实际复杂性和具体内容将取决于现实世界的背景和数据的性质。
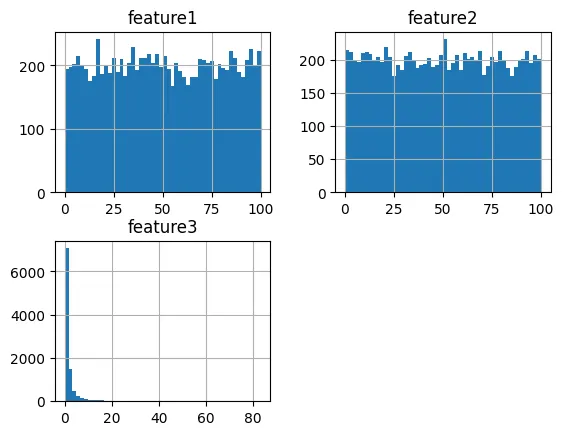
直方图代表了数据集中三个特征的分布。以下是基于所提供可视化的解释:
-
特征1直方图(左下角):这个图表表明了一个高度偏斜的分布,大量值集中在范围的低端。较长的尾部指向更高的值,表明少数实例的值远大于大多数。这可能意味着,尽管大多数数据点具有较低的feature1值,但一些异常值或特殊情况具有较高的值。
-
特征2直方图(右上角):与feature1相比,feature2的分布相对均匀。值在整个范围内更加均匀分布,表明数据没有显著的偏斜。这表明对于feature2,数据集不会显著偏向较低或较高的值,这可能意味着观察结果的测量更加一致或均匀。
-
特征3直方图(左上角):feature3的直方图显示了与feature2类似的均匀分布,但比例不同。条形在整个范围内保持一致,表明数据点在整个值范围内均匀分布。这种均匀性表明feature3可能是一个衍生特征,用于标准化或平衡feature1和feature2的规模,特别是如果它是其他特征的比率或标准化版本。
总之,数据集具有多样化的分布:一个可能需要转换的偏斜特征(feature1),以及两个具有均匀分布的特征,这可能意味着不同类型的底层过程或测量(feature2和feature3)。
理解这些分布对于进一步的数据分析很有必要,因为它们会影响模型假设和预测分析结果。
Feature 1 的平均值: 50.07768072209234
Feature 2 的平均值: 49.70887755277188
Feature 1 和 Feature 2 之间的相关性:feature1 feature2
feature1 1.000000 -0.004829
feature2 -0.004829 1.000000
提供的统计输出有助于进一步了解feature1和feature2的特征:
-
特征1的平均值:
feature1的平均值约为50.08。这表明,feature1的数据点分布在略高于范围中点的中心值周围(假设范围为0-100,基于直方图)。这个中心趋势与直方图一致,显示了一个重左偏但仍然集中在范围中间的分布。 -
特征2的平均值:
feature2的平均值约为49.71,非常接近范围的中点(再次假设范围为0-100)。平均值与直方图一致,显示了在整个范围内的均匀分布。 -
特征1和特征2之间的相关性:
feature1和feature2之间的相关系数为-0.004829,非常接近零。这表明这两个特征之间几乎没有线性关系。换句话说,知道feature1的值并不能预测feature2的值,反之亦然。这种缺乏相关性在许多分析环境中都很重要,因为它意味着这两个特征可以独立地为预测模型做出贡献,而不会带来可能扭曲模型性能的冗余。
解释: 平均值和相关性表明,尽管两个特征在其范围的中点周围具有中心趋势,但它们的行为是独立的。Feature1显示出对较低值的偏斜,有一些较高的异常值,而feature2在其范围内显示均匀分布。缺乏相关性对于数据建模很重要,因为它意味着这些特征可以独立地贡献于预测模型,而不会带来冗余。
综上所述,Dask是数据处理与并行计算领域的一次飞跃进步,提供了一个既高效又可扩展的大数据处理平台,大幅缓解了各领域面临的数据量增长挑战。在数据已成为决策和研究的关键因素的今天,Dask这类能够高效处理大规模数据的工具显得尤为珍贵。正因如此,Dask不仅是数据处理技术发展的重要里程碑,也是推动未来大数据分析和并行计算创新的坚实基石。
这篇关于高效可扩展,使用Dask进行大数据分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




