本文主要是介绍探索Python中的生成器:让数据流动起来,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1. 生成器
- 1.1 基础
- 1.2 工作原理
- 1.3 表达式
- 1.4 高级应用
- 2. 生成器是不是相当于函数中的return
- 3. 生成器为什么叫yield
在Python面试中,深入了解生成器是关键。这一特性通过延迟计算优化内存使用,广泛应用于数据流处理和异步编程,对提升编程效率至关重要。
1. 生成器
1.1 基础
在Python中,生成器是一种特殊的迭代器,其主要功能是控制函数的执行流程,允许函数在执行过程中暂停,并在适当的时候继续执行。生成器的使用可以使内存使用更加高效,特别适合处理大数据流或是执行复杂的计算。
示例代码:
def simple_generator():yield 1yield 2yield 3# 使用生成器
for value in simple_generator():print(value)
在上述示例中,simple_generator 函数通过使用 yield 关键字,依次生成数值 1、2、3。每次调用生成器会暂停在每一个 yield 语句处,返回相应的值,直到下一次迭代请求或生成器执行结束。
1.2 工作原理
生成器背后的工作机制基于状态的保存。当生成器函数执行到 yield 时,函数的状态(包括局部变量、指令指针等)被保存下来,函数暂停执行。当生成器再次被请求数据时,它从上次暂停的地方恢复执行。
示例代码:
def countdown(n):while n > 0:yield nn -= 1# 调用生成器
for i in countdown(5):print(i)
在 countdown 函数中,生成器从传入的数字开始倒数。每次迭代时,它输出当前的计数并减一,直到计数到 0 为止。通过 yield,函数在每一次迭代中暂停并恢复,这使得它的执行非常内存高效。
1.3 表达式
生成器表达式是一种更加简洁的生成器定义方式,语法上类似于列表推导式,但使用圆括号而不是方括号。
示例代码:
squares = (x*x for x in range(10))for square in squares:print(square)
这里定义了一个生成器表达式 squares,它计算从 0 到 9 的数的平方。与列表推导式不同,生成器表达式不会一次性计算所有元素,而是生成一个可迭代的生成器,每次迭代计算一个值。
1.4 高级应用
生成器不仅仅可以用于简单的值生成,它们的延迟计算特性使得它们非常适合于管道和数据流操作中。
示例代码:
def fibonacci(n):a, b = 0, 1while n > 0:yield ba, b = b, a + bn -= 1# 打印斐波那契数列的前10个数
for num in fibonacci(10):print(num)
此示例中的 fibonacci 函数生成斐波那契数列。生成器每次迭代时返回数列中的下一个数字,通过简单的赋值操作来更新数列的下一个值。这种方式特别适合计算那些依赖之前元素的序列。
2. 生成器是不是相当于函数中的return
生成器中的 yield 关键字与函数中的 return 关键字有相似之处,但它们在用途和行为上有明显的区别。这里列出了它们之间的一些主要对比点:
相似点:
- 返回值:
yield和return都用于在函数中返回值。它们都可以将值传递给调用者。
区别点:
- 函数终止:
return:当函数执行到return语句时,它会结束函数的执行,并返回指定的值。一旦return被执行,函数的局部状态(变量等)就会被清除。yield:与return不同,yield用于暂停函数的执行并返回一个值给调用者,但它保留了函数的状态,使得函数可以在下一次从它暂停的地方继续执行。
- 返回类型:
return:返回一个具体的值。yield:返回一个生成器对象,这个对象是一个迭代器,支持通过迭代来逐个获取由yield产生的值。
- 使用场景:
return:用于常规函数中,适合于一次性计算并返回一个结果的场景。yield:用于生成器函数中,适合于需要逐步产生多个结果的场景,尤其是在处理大型数据集或是需要延迟计算的情况。
这个生成器函数逐个返回数字,每次调用都会在 yield 语句处暂停,下一次迭代时从上次暂停的地方继续。
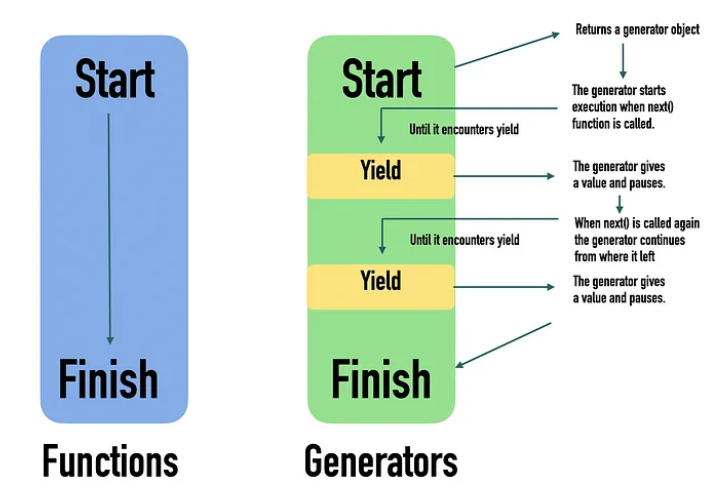
总结来说,尽管 yield 和 return 都可以在函数中用于返回值,但 yield 更适合于需要多次返回值的场景,它支持生成值的流式处理,而不需要一次性计算所有数据。这种方式特别适合处理数据流、大规模数据集或需要增量计算的场景。
3. 生成器为什么叫yield
生成器函数使用yield关键字,这个词在英语中的字面意思是“产生”或“屈服”。yield用于生成器函数中,有以下含义和理由:
- 产生值:
yield关键字用于在每次迭代中产生或返回一个值,而不是终止函数。这种方式使得生成器能够逐个产出值,每产生一个值后,函数的执行会被暂停,直到下一次迭代请求继续产生下一个值。因此,yield可以看作是逐步“产生”结果的工具。 - 暂时屈服控制权:使用
yield时,函数实际上是在“屈服”其控制权给调用者。函数暂停执行,并将控制权交回给调用者,直到调用者再次激活函数继续执行。这种控制流的暂停和恢复是生成器的核心特性。 - 协程的基础:在更高级的用法中,
yield可以用于协程,这是一种程序组件,可以更细粒度地控制其执行。在协程中,yield不仅仅是产生数据,还可以接收外部通过send()发送的数据,这种双向通信机制使得yield在协程中扮演着非常重要的角色。
推荐: python 错误记录
参考:How To Use Yield in Python To Make Your Functions More Efficient
这篇关于探索Python中的生成器:让数据流动起来的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




