本文主要是介绍Postgresql源码(125)游标恢复执行的原理分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
问题
为什么每次fetch游标能从上一次的位置继续?后面用一个简单用例分析原理。
【速查】
恢复扫描需要知道当前页面、上一次扫描到的偏移位置、当前页面一共有几条:
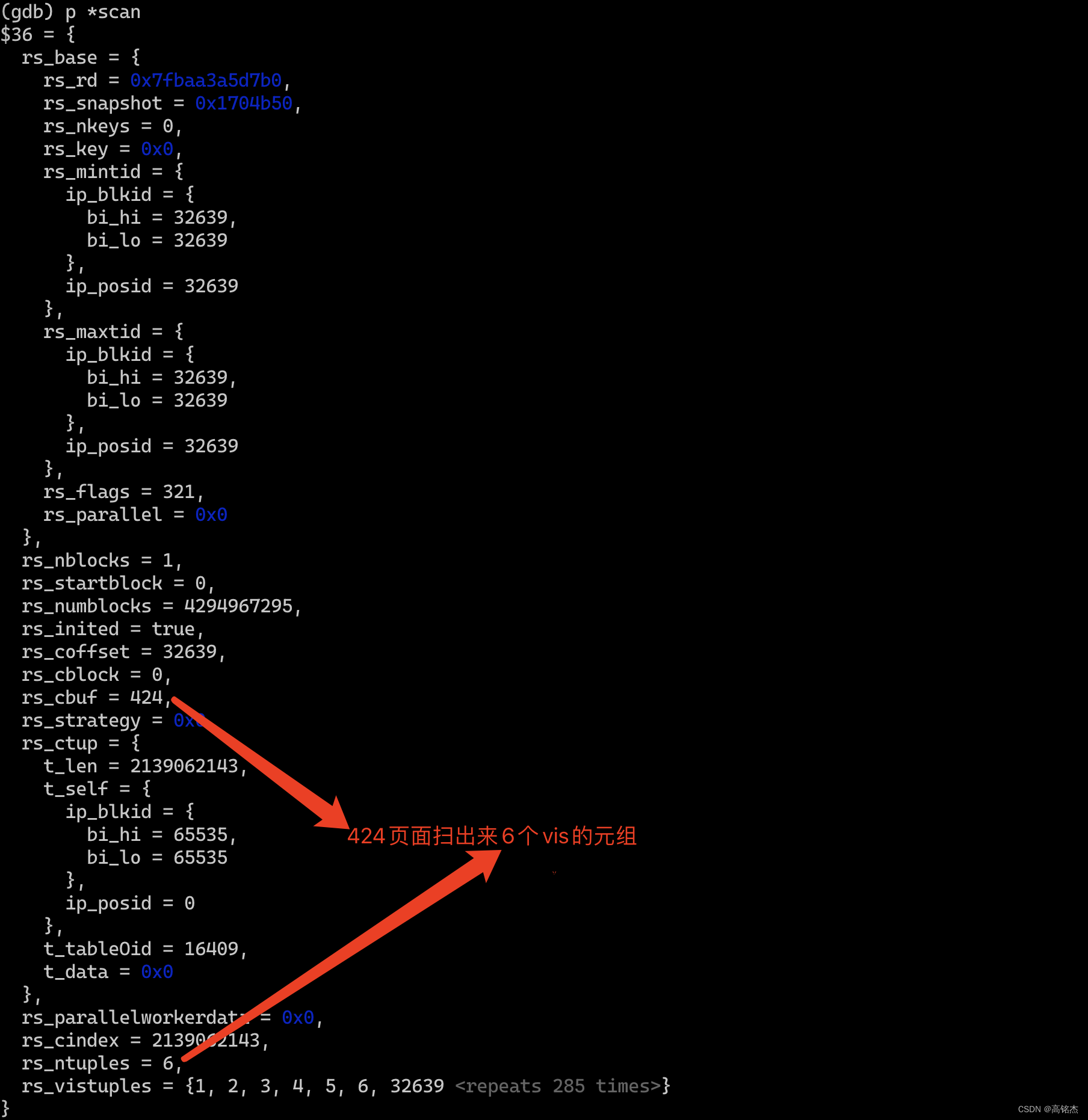
- 当前页面:HeapScanDesc结构中记录了扫到的页面(scan->rs_cblock)
- 上一次扫描到的偏移位置:scan->rs_cindex,注意rs_cindex是每个页面内的可见元组,从0开始算,每个页面都会从0遍历到scan->rs_ntuples为止。
- 当前页面一共有几条:scan->rs_ntuples记录了当前页面有几个vis元组,在heapgetpage函数中计算。
场景一:open curs1 FOR SELECT ...
drop table tf1;
create table tf1(c1 int, c2 int, c3 varchar(32), c4 varchar(32), c5 int);
insert into tf1 values(1,1000, 'China','Dalian', 23000);
insert into tf1 values(2,4000, 'Janpan', 'Tokio', 45000);
insert into tf1 values(3,1500, 'China', 'Xian', 25000);
insert into tf1 values(4,300, 'China', 'Changsha', 24000);
insert into tf1 values(5,400,'USA','New York', 35000);
insert into tf1 values(6,5000, 'USA', 'Bostom', 15000);drop procedure tproc1;
CREATE OR REPLACE PROCEDURE tproc1() AS $$
DECLAREcurs1 refcursor; y tf1%ROWTYPE;
BEGINopen curs1 FOR SELECT * FROM tf1 WHERE c1 > 3;fetch curs1 into y; RAISE NOTICE 'curs1 : %', y.c3;fetch curs1 into y; RAISE NOTICE 'curs1 : %', y.c3;
END;
$$ LANGUAGE plpgsql;call tproc1();
1 OPEN
exec_stmt_open中的执行结构
(gdb) p *stmt
$3 = {cmd_type = PLPGSQL_STMT_OPEN,lineno = 6,stmtid = 1,curvar = 1,cursor_options = 256,argquery = 0x0,query = 0x1824390,dynquery = 0x0,params = 0x0
}
(gdb) p *stmt->query
$5 = {query = 0x1824698 "SELECT * FROM tf1 WHERE c1 > 3",parseMode = RAW_PARSE_DEFAULT,plan = 0x0,paramnos = 0x0,func = 0x0,ns = 0x1824570,expr_simple_expr = 0x0,expr_simple_type = 0,expr_simple_typmod = 0,expr_simple_mutable = false,target_param = -1,expr_rw_param = 0x0,expr_simple_plansource = 0x0,expr_simple_plan = 0x0,expr_simple_plan_lxid = 0,expr_simple_state = 0x0,expr_simple_in_use = false,expr_simple_lxid = 0
}
第一步:exec_prepare_plan
exec_stmt_openexec_prepare_planSPI_prepare_extended_SPI_prepare_planraw_parserCreateCachedPlanpg_analyze_and_rewrite_withcbCompleteCachedPlanSPI_keepplanexec_simple_check_plan
结果保存在stmt->query->plan
第二步:SPI_cursor_open_with_paramlist
exec_stmt_open-- 有参数时会构造ParamListInfo返回-- 这里没参数,返回NULLsetup_param_listSPI_cursor_open_with_paramlistSPI_cursor_open_internalCreateNewPortal-- 没ParamListInfo一定走generic planGetCachedPlanPortalDefineQuery-- 拿快照CommandCounterIncrementGetTransactionSnapshot-- 主要是为了执行InitNodePortalStartCreateQueryDescExecutorStartstandard_ExecutorStartCreateExecutorStateInitPlanExecInitRangeTableExecInitNodeExecGetResultType
2 FETCH
第一步:找到portal
curvar = (PLpgSQL_var *) (estate->datums[stmt->curvar]);
curname = TextDatumGetCString(curvar->value);
portal = SPI_cursor_find(curname);
第二步:计算fetch几个?
if (stmt->expr)how_many = exec_eval_integer(estate, stmt->expr, &isnull);
第三步:FETCH
SPI_scroll_cursor_fetch(portal, FETCH_FORWARD, 1)_SPI_cursor_operation(.., CreateDestReceiver(DestSPI))PortalRunFetch(portal, FETCH_FORWARD, 1, dest=<spi_printtupDR>)MarkPortalActiveDoPortalRunFetchPortalRunSelect(portal, forward=true, count=1, dest=<spi_printtupDR>)PushActiveSnapshotExecutorRun(queryDesc, direction=ForwardScanDirection, count=1, execute_once=false)-- 配置接受者,现在是SPI-- SPI会存到_SPI_current->tuptables中dlist-- 每个元素是 tuptable,tuptable->vals存放HeapTupledest->rStartupspi_dest_startup-- 这里入参有一个numberTuples=1表示只执行一条ExecutePlanfor (;;)-- 这里只执行一次,那么多次fetch是怎么能继续上次执行的?ExecProcNode-- 这里只拿一条,拿到就退if (numberTuples && numberTuples == current_tuple_count)break;PopActiveSnapshot
ExecProcNode展开:执行一次
ExecProcNodeExecProcNodeFirstExecSeqScanExecScanfor (;;)ExecScanFetchSeqNext-- 第一次进来创建scandescif (scandesc == NULL)scandesc = table_beginscan(...)-- 开始扫描table_scan_getnextslot(scandesc, direction, slot)heap_getnextslotheapgettup_pagemode()
heapgettup_pagemode执行第一次:
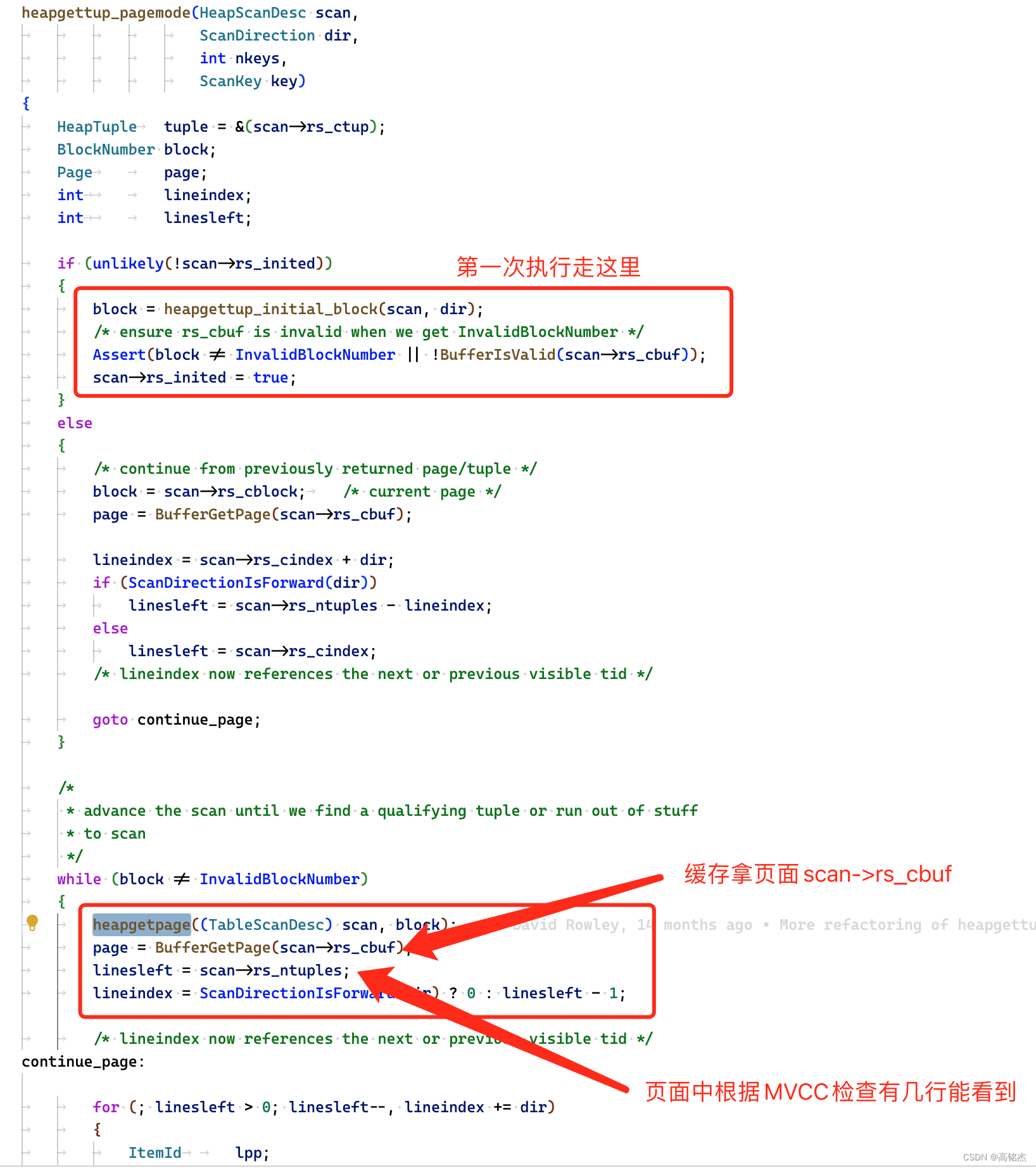
heapgettup_pagemode执行第N次:

所以为什么每次游标fetch都能继续上次的值:
- HeapScanDesc结构中记录了扫到的页面(scan->rs_cblock)、页面中的位置(scan->rs_cindex),注意rs_cindex是每个页面内的可见元组需要,从0开始算,每个页面都会从0遍历到scan->rs_ntuples为止。
- scan->rs_ntuples记录了当前页面有几个vis元组,在heapgetpage函数中计算。
场景二:open curs1 FOR EXECUTE ...
drop table tf1;
create table tf1(c1 int, c2 int, c3 varchar(32), c4 varchar(32), c5 int);
insert into tf1 values(1,1000, 'China','Dalian', 23000);
insert into tf1 values(2,4000, 'Janpan', 'Tokio', 45000);
insert into tf1 values(3,1500, 'China', 'Xian', 25000);
insert into tf1 values(4,300, 'China', 'Changsha', 24000);
insert into tf1 values(5,400,'USA','New York', 35000);
insert into tf1 values(6,5000, 'USA', 'Bostom', 15000);CREATE OR REPLACE PROCEDURE tproc1() AS $$
DECLAREcurs1 refcursor; y tf1%ROWTYPE;
BEGINopen curs1 FOR EXECUTE 'SELECT * FROM tf1 WHERE c1 > $1' using 3;fetch curs1 into y; RAISE NOTICE 'curs1 : %', y.c3;fetch curs1 into y; RAISE NOTICE 'curs1 : %', y.c3;
END;
$$ LANGUAGE plpgsql;call tproc1();
OPEN区别
不在执行exec_prepare_plan直接执行exec_dynquery_with_params:
exec_stmt_openportal = exec_dynquery_with_params-- 第一步:把表达式计算出来 "SELECT * FROM tf1 WHERE c1 > $1"-- 因为有可能使用表达式,比如"select * " || "from " || "tf1" exec_eval_exprSPI_cursor_parse_open_SPI_prepare_planSPI_cursor_open_internalCreateNewPortalGetCachedPlan-- 注意这里会把plan删了,portal define的时候是用的copy的,计划没有缓存。ReleaseCachedPlan(cplan, NULL);stmt_list = copyObject(stmt_list);PortalDefineQuery(stmt_list)PortalStart
FETCH区别
exec_stmt_fetchSPI_scroll_cursor_fetch_SPI_cursor_operationPortalRunFetch
这里的portal没有plan
p *portal
$50 = {name = 0x178b550 "<unnamed portal 10>", prepStmtName = 0x0, portalContext = 0x1841b00, resowner = 0x172efe8, cleanup = 0x6cb0d2 <PortalCleanup>, createSubid = 1, activeSubid = 1, createLevel = 1, sourceText = 0x1841c00 "SELECT * FROM tf1 WHERE c1 > $1", commandTag = CMDTAG_SELECT, qc = {commandTag = CMDTAG_SELECT, nprocessed = 0},stmts = 0x1841c30, <<<<<<<<< ------- 拷贝的计划在这里,运行时用这里的计划cplan = 0x0, <<<<<<<<<<< ------- 注意这里没plan,已经清理了portalParams = 0x18531b8, queryEnv = 0x0, strategy = PORTAL_ONE_SELECT, cursorOptions = 258, run_once = false, status = PORTAL_READY,portalPinned = false, autoHeld = false, queryDesc = 0x1853248, tupDesc = 0x1849288, formats = 0x0, portalSnapshot = 0x0, holdStore = 0x0, holdContext = 0x0, holdSnapshot = 0x0,atStart = true, atEnd = false, portalPos = 0, creation_time = 766486974937570, visible = true}
继续执行
PortalRunFetchDoPortalRunFetchPortalRunSelectExecutorRunfor (;;)ExecProcNode
后续流程相同。
这篇关于Postgresql源码(125)游标恢复执行的原理分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




