本文主要是介绍Deep Learning for Single Image Super-Resolution: A Brief Review,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
TMM 2019
用深度学习来解决SISR问题(single image super resolution)的问题,从两个方面
- 高效的网络结构,efficient architectures;
- 有效的优化目标,OPTIMIZATION OBJECTIVES;
问题的定义
由LR y y y恢复HR x x x, k k k表示卷积核, ↓ s \downarrow_s ↓s表示下采样操作, n n n表示噪声;
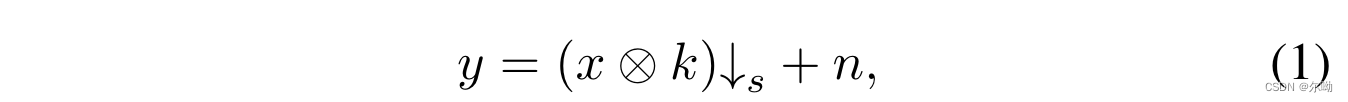
方法分为三类:
- Interpolation-based SISR methods
- Reconstruction-based SR methods
- Learning-based SISR methods
- 本综述主要针对深度学习的方法
指标:

数据集: - 291 dataset
- ImageNets
- DIV2K dataset
efficient architectures
- benchmark:SRCNN,输入输出相同大小,输入LR的bicubic差值之后的结果,输出是HR,损失是MSE;
- baseline主要存在的问题:
– 输入是LR经过差值之后得到的和HR一样尺寸的结果;
– SRCNN网络过于简单,只是三层的卷积; - FSRCNN使用反卷积来实现输入直接是LR;
- ESPCN不使用deconvolution,而是使用在channel维度进行扩展,之后再rearrange得到结果;
- VDSR使用了更深的网络结构,并且在训练的时候输入是不同rate的LR来达到一个模型实现多种scale的SR任务;
- DRCN也使用了更深的网络,最后的HR结果是所有中间层结果的加权和;
- SRResNet, DRRN使用了残差网络来实现;
- EDSR也使用了残差网络,但是去掉了BN操作,之后MDSR考虑不同scale之间的联系,所以训练的时候也是多种scale一起进行的;
- SRDenseNet使用的densenet,MemNet和RDN也是;
- SCN将采用稀疏编码和神经网络相结合(稀疏编码不知道是啥?);
- MSCN输入LR,得到多个HR输出,之后融合;
- DEGREE, LapSRN都使用了progressive methodology(resnet的中间层的特征输入到最后的层也能得到还行的效果,scale2的模型可以约束高scale的解空间);
- PixelSR使用PixelRNN来实现,LR作为条件,自回归的进行生成HR;
- DBPN使用神经网络来模拟interative backprojection的过程;
- DEGREE使用了边缘图,SFT-GAN使用了分割图,SRMD考虑了LR的不同退化;
- ……
OPTIMIZATION OBJECTIVES
- benchmark:SRCNN MSE loss
这篇关于Deep Learning for Single Image Super-Resolution: A Brief Review的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








