本文主要是介绍BIO, NIO, select, poll, epoll,multiplexing以及netty, reactor编程模式,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
阅读本文之前,请先阅读本人的另外一篇博文:
你真的理解java BIO/NIO的accept()方法了么?
https://blog.csdn.net/Tom098/article/details/116107072?spm=1001.2014.3001.5501
该文章与本文紧密联系,讲的比较深入,可以做为基础先看一下。
以下是自己对相关概念的初步理解。主要基于Linux操作系统。其中netty和reactor只是一笔带过,不是本文重点。后续后写专门的文章介绍自己对netty和reactor(响应式或者叫被动型网络编程模型,相对于proactive - 就是传统的主动型网络编程模型)的理解。
1. Doug Lee的Scalable IO 文章链接
http://gee.cs.oswego.edu/dl/cpjslides/nio.pdf
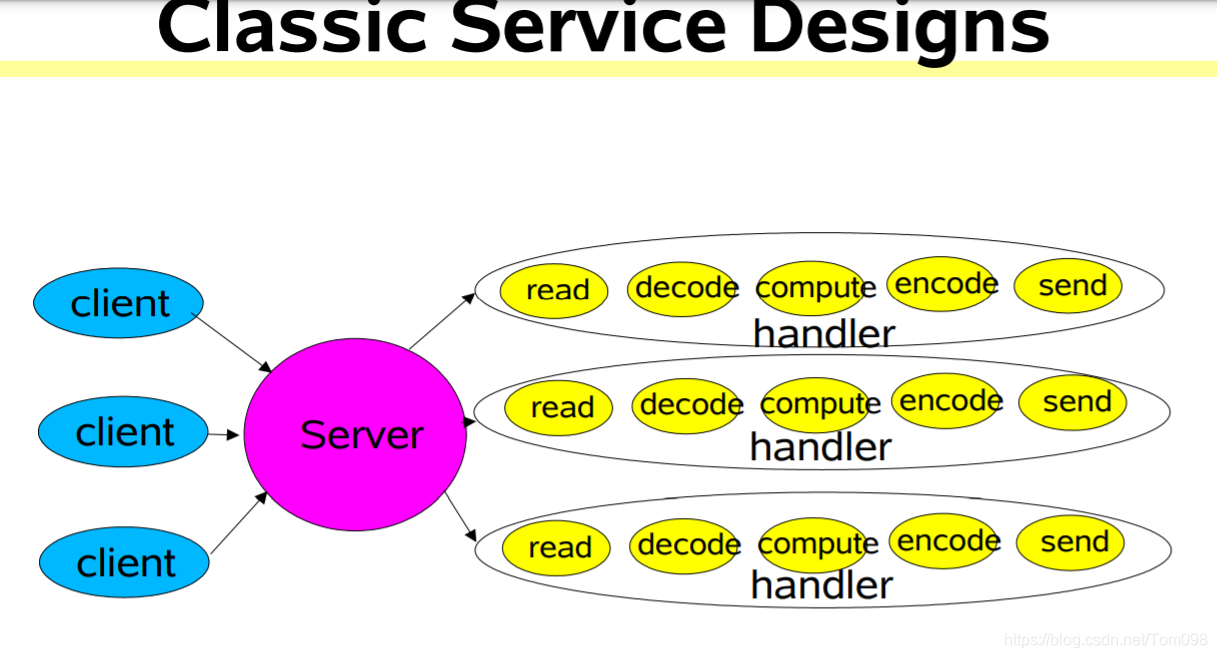
2. BIO阻塞IO,使用的是JDK的阻塞IO API。典型的服务器实现架构如下。缺点:
a. 针对每一个客户端请求,开启一个线程。会导致服务端内存耗尽。
b. 如果使用线程池,可以避免a. 中提到的问题,但是由于socket 的 accept(),read()方法都是阻塞式的,会导致新进的连接和现有socket上的数据读取不及时,时间都用在等待客户端数据发送上了。效率低下
3. NIO 相对于BIO, NIO的相关accept(), read()方法都是非阻塞式的,即使socket中没有可读数据,也会立即返回。不会让线程被阻塞等待。
但是如果单纯使用NIO开发服务器端程序,不结合select/poll/epoll使用,也有缺点。比如:
如果大量已建立的socket中没有数据,服务端程序就需要循环不停的调用accept(), read()方法轮询,每次调用这些方法,都会对应一次系统调用,耗费大量资源,而大多时候都是去查询缓冲区中没有数据的socket,相当于是在空转,浪费大量资源。
4. select方式。使用NIO + select 方式,是在JDK1.5以前版本中使用。select 的好处是每次对服务器程序现有的socket轮询时(包括处于listening状态用于建立连接的和established状态用来收、发客户端业务数据的),不会第一时间由服务器用户代码来做(在用户空间做),而是通过执行select()库函数进行select()系统调用(为了简化用户代码进行系统调用,系统会提供库函数,对系统调用进行一层封装,这样用户代码再调用库函数时,就简单很多),让内核程序先在内核轮询一遍。在调用时,用户代码会将所有需要轮询的sockets的FD(File descriptor)以FD数组的形式传递给内核。内核在轮询时,如果发现有收到数据的socket,就会直接返回给调用程序,并返回传过来的FD数组,只不过会把其中接收缓冲区中有数据的socket给标识出来。然后调用程序(用户空间,服务器程序自己代码)再针对所有数据的socket做read()轮询操作。这样就避免了对没有可读数据的socket做轮询操作。
5. multiplexing: 多路复用。这种NIO + select以及后边NIO 和poll/epoll的结合,很多资料也叫他多路复用。多路复用是可以用到很多场合的概念,wikipedia给的例图如下:

这好比中间是一条主干道,左侧有三条道路并入主干道,主干道右侧又有三个出口。左侧的三条道路编号是1,2,3, 右侧三条道路编号也是1,2,3。如果中间没有一条主干道,而是左右三条道路分别直接联通,这样每条道路上车只在自己的道路上通行,但偏偏是中间只有一条通路,这时左右两侧的道路上的车辆就需要汇入到主干道,在主干道出口时,再分别进入到自己的道路。多路复用在网络的世界中用到也很多,比如下图。

而NIO + select/pool/epoll实现的多路复用如何理解呢?比如下图,针对每一个established socoket,server端都会建立一个线程去读取数据。不管该线程是采用BIO还是NIO,都会导致客户端连接很多时,线程数也会很多,造成系统瓶颈。

而采用的了NIO + select/pool/epoll的方式之后,其大致的结构图如下。因为基于select,在用户空间的应用可以有多种方式实现socket数据读写,这里的结构图也不太好画,基于不同的实现方式,有不同的画法。但是大致我们可以理解成这样的:
用户空间可以有一个主线程负责进行select()系统调用以获取处于可读 状态的socket,然后这时如果该主线程可以有多种选择,
- 自己不读取业务数据,而是只是返回可读socket的列表,然后由业务线程再分别直接从socket中读取数据。
- 自己将这些有数据的socket的数据读出来,进行封装,放到一个queue中,再由业务处理线程池的worker thread来读取queue。
- 指定几个专门的线程,专门用于从这些有可读数据的socket中读取数据,并放到一个queue中,然后由worker thread来处理。
那除了第一种情况,另外两种情况,我们是否可以理解成客户端业务数据的经由路径是先到各个socket的读缓冲区中,然后再统一经由负责select()调用的线程处理,然后再分发给后台的业务线程。这样大致可以认为也是multiplexing。

6. poll的方式相比于select, 做了一些优化。突破了select的最多轮询1024个sockets的限制(就是在调用select()系统调用时, FD数组最大只能1024)。
7. epoll: 从jdk.5开始支持。epoll是even poll 事件轮询的缩写。目前主流的服务端程序都是基于NIO + epoll的。epoll的工作流程大致如下:
8. epoll有三个基本的系统函数:
epoll_create(): 在操作系统内核空间创建epoll 实例(就是一个内存数据结构)。其中有两个主要的集合,一个集合是包含所有注册到该epoll的socket,另一个集合是叫ready list,包含所有接收缓冲区有接收到数据的socket。官方说法用event 取代socket,但是感觉event是对socket的一次封装,用event,可以更好的描述基于event drivent机制(类似于设计模式的观察者模式)的epoll模型,但本质上最重要的数据还是缓冲区有数据的socket的FD。
epoll_ctl(): 将已建立连接的、处于established状态的socket和处于listening状态的socket注册到epoll实例上。当然还可以从epoll实例删除、修改相关的socket
epoll_wait(): 查询epoll实例的ready list,如果是空,阻塞。如果非空直接返回。如果是空,进程会被阻塞住,这时如果有客户端向该进程的一个socket发送数据,网卡驱动将数据拷贝到内存,通过中断通知CPU,CPU会调用对应的中断程序,将该数据copy到对应的socket的读缓冲区中,同时检查该socket有没有关联到一个epoll实例上,如果有,会将该socket加入到epoll实例的ready list集合中,并唤醒用户进程使epoll_wait()继续执行,将ready list中的sockets返回给用户空间程序。(这里写的非常粗犷,有的文章有提到在创建epoll实例或者创建新的连接时,会将一个程序注册到网卡数据读取中断程序中,以便内核在将网卡数据从内存copy到socket读缓冲区时,会回调该程序,用来将该socket放到epoll实例的ready list中,以及唤醒等待进程)
9. netty是对NIO, epoll的完美封装,使用户聚焦于核心业务应用,不必聚焦socket的建立,读写等底层繁琐的使用。并且netty做了巨大的优化,使您的基于netty开发的服务端程序在处理客户端发送的连接请求和业务数据这两块儿做到了很好的平衡。
10. Reactor编程模型也是利用到NIO和epoll。具体参考1中提到的Doug大神的文章。

总结:
epoll是Linux内核提供的,在solaris中,类似的模型是DevPoll。windows使用的是winsock2来实现类似的功能。
操作系统从最初的只提供BIO系统调用,到后来支持NIO,以及一步一步又支持select, poll和epoll,我们可以看到操作系统也是在根据用户空间程序的痛点在不断改进的。
思考:
1. 为什么在netty或者上图的reactor模型中,为专门处理用户连接请求建立的lisening socket建立一个selector或者reactor?
个人理解是如果当前有大量的连接请求进来,如果让处理从established socket中读数据和从lisening socket读数据操作放在一个selector/reactor 或者线程中,那么该线程压力会很大。如果读的慢,可能会导致lisening socket的读缓冲区满(Recive queue),客户端新连接请求无法被处理。
注:上图中每个线程对应一个sector (或者一个reactor)。
这篇关于BIO, NIO, select, poll, epoll,multiplexing以及netty, reactor编程模式的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





