本文主要是介绍Re66:读论文 Bottom-Up Abstractive Summarization,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
诸神缄默不语-个人CSDN博文目录
诸神缄默不语的论文阅读笔记和分类
论文全名:Bottom-Up Abstractive Summarization
EMNLP官方论文下载地址:https://aclanthology.org/D18-1443/
模型可以简称为BottomUp
官方GitHub项目:sebastianGehrmann/bottom-up-summary
本文是2018年EMNLP论文,算是经典早期生成式摘要工作。
解决端到端生成模型选取内容时的问题(不会选择内容,复制机制会复制整句……):限制只能负责selector选择的一部分token(以token为单位匹配摘要标签中复制自原文的内容)
content selector → summarizer
content selector仅需在1000个句子的语料上训练
content selector:bottom-up attention(先选取内容,后重述)
有很多技术性细节之类的我都没写,只写了我认为比较重要的内容。
文章目录
- 1. BottomUp
- 1. content selector
- 2. summarizer
- 3. 推理
- 2. 实验
- 1. 案例分析
- 2. baseline设置
- 3. 实验结果
- 4. 模型分析
1. BottomUp
现有的一些先抽取后生成的方案会抽取整句。
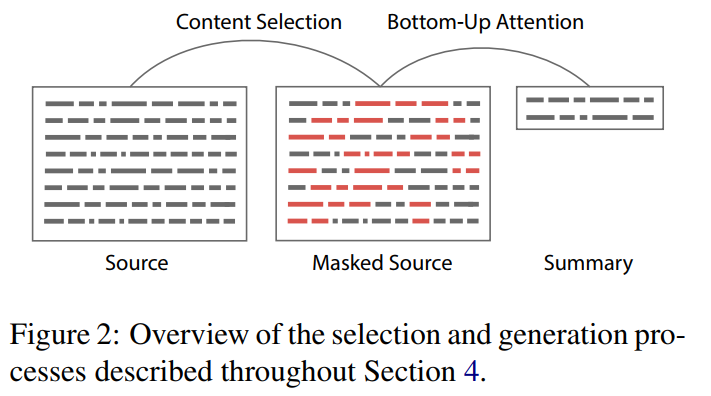
1. content selector
word-level extractive summarization task
选择尽可能多的内容:用序列标注范式进行selection mask,限制复制机制的选择范围
用Bi-LSTM做序列标注,初始表征用GLoVE + 微调过的ELMo:
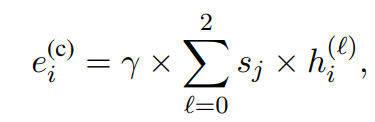
获取训练集:对齐摘要标签,即将原文与摘要标签中匹配的子序列中的token作为抽取标签(去重)
这段原文讲得不清楚,不如看代码:
def make_BIO_tgt(s, t):# tsplit = t.split()ssplit = s#.split()startix = 0endix = 0matches = []matchstrings = Counter()while endix < len(ssplit):# last check is to make sure that phrases at end can be copiedsearchstring = compile_substring(startix, endix, ssplit)if searchstring in t and endix < len(ssplit)-1:endix +=1else:# only phrases, not words# uncomment the -1 if you only want phrases > len 1if startix >= endix:#-1:matches.extend(["0"] * (endix-startix + 1))endix += 1else:# First one has to be 2 if you want phrases not wordsfull_string = compile_substring(startix, endix-1, ssplit)if matchstrings[full_string] >= 1: # 去重matches.extend(["0"]*(endix-startix))else:matches.extend(["1"]*(endix-startix))matchstrings[full_string] +=1#endix += 1startix = endixreturn " ".join(matches)def compile_substring(start, end, split):if start == end:return split[start]return " ".join(split[start:end+1])
2. summarizer
复制机制(基本上就是PGN的逻辑)
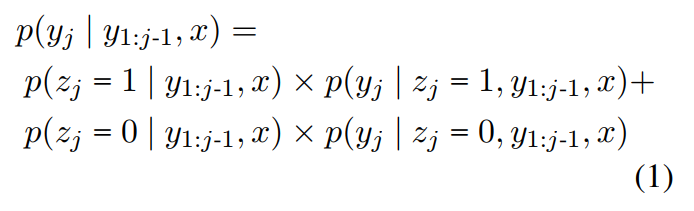
其中 p ( z ) p(z) p(z)是 p ( y ) p(y) p(y)在这个token上的attention的和。
BottomUp中复制机制只能选择在selector中选择的token:
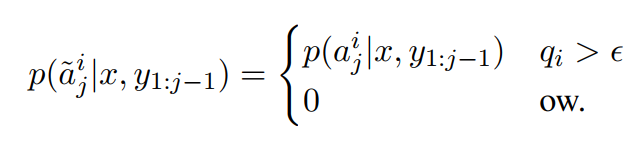
↑ renormalization
3. 推理
在概率得分中增加罚项:
length penalty l p lp lp and a coverage penalty c p cp cp

l p lp lp鼓励生成长文本:
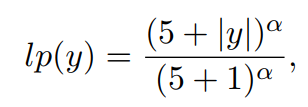
c p cp cp减少重复:
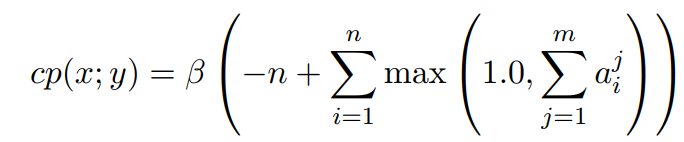
(↑ 这个我也没看懂是啥意思)
禁止生成重复trigrams
2. 实验
1. 案例分析
禁止生成的字符为灰色 ↓
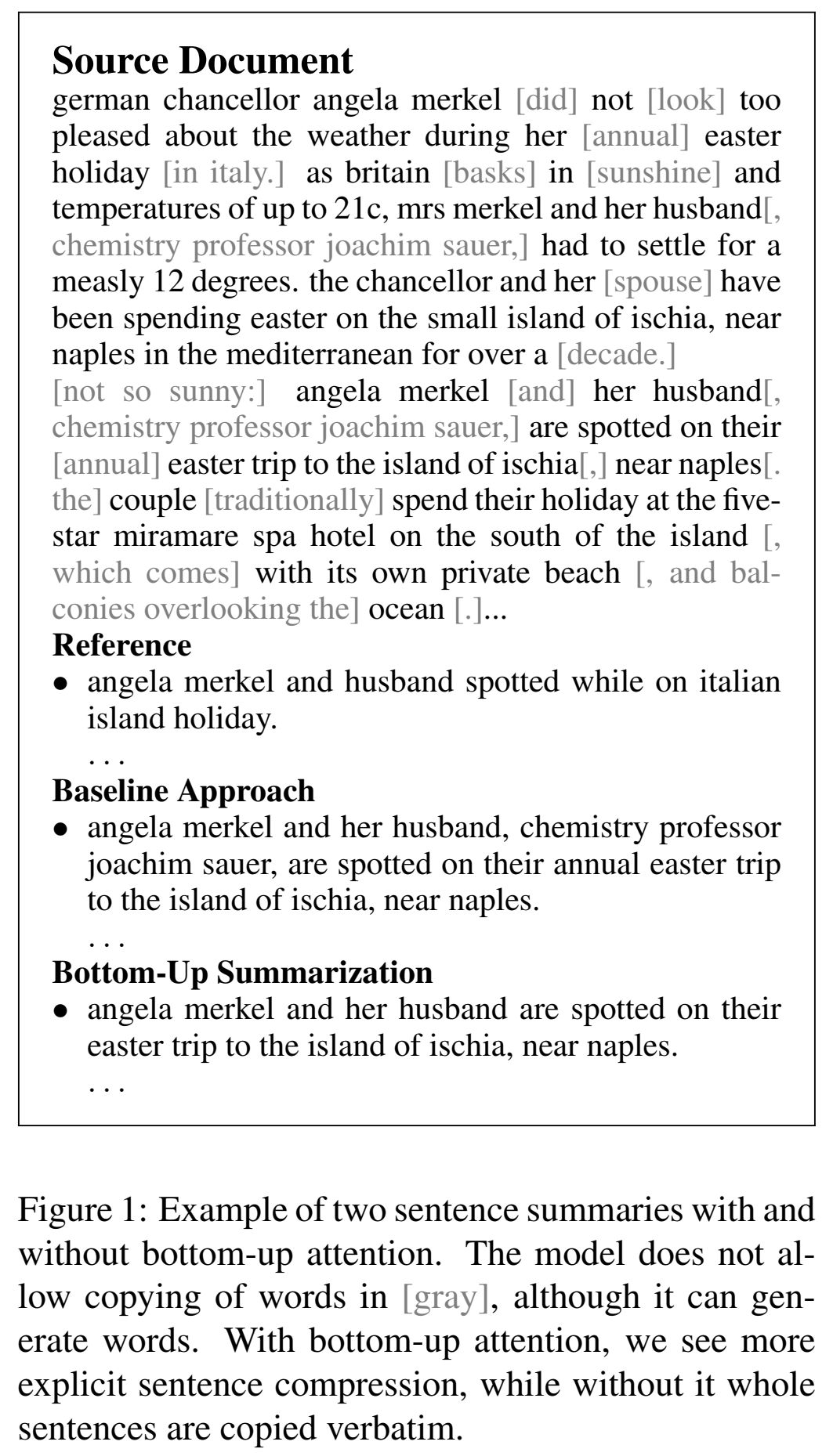
2. baseline设置
CopyTransformer是随机选了一个注意力头来实现复制
端到端的变体:
- mask only:仅在训练阶段使用selector结果作为mask,在测试时不用
- 多任务学习
- 可微分mask
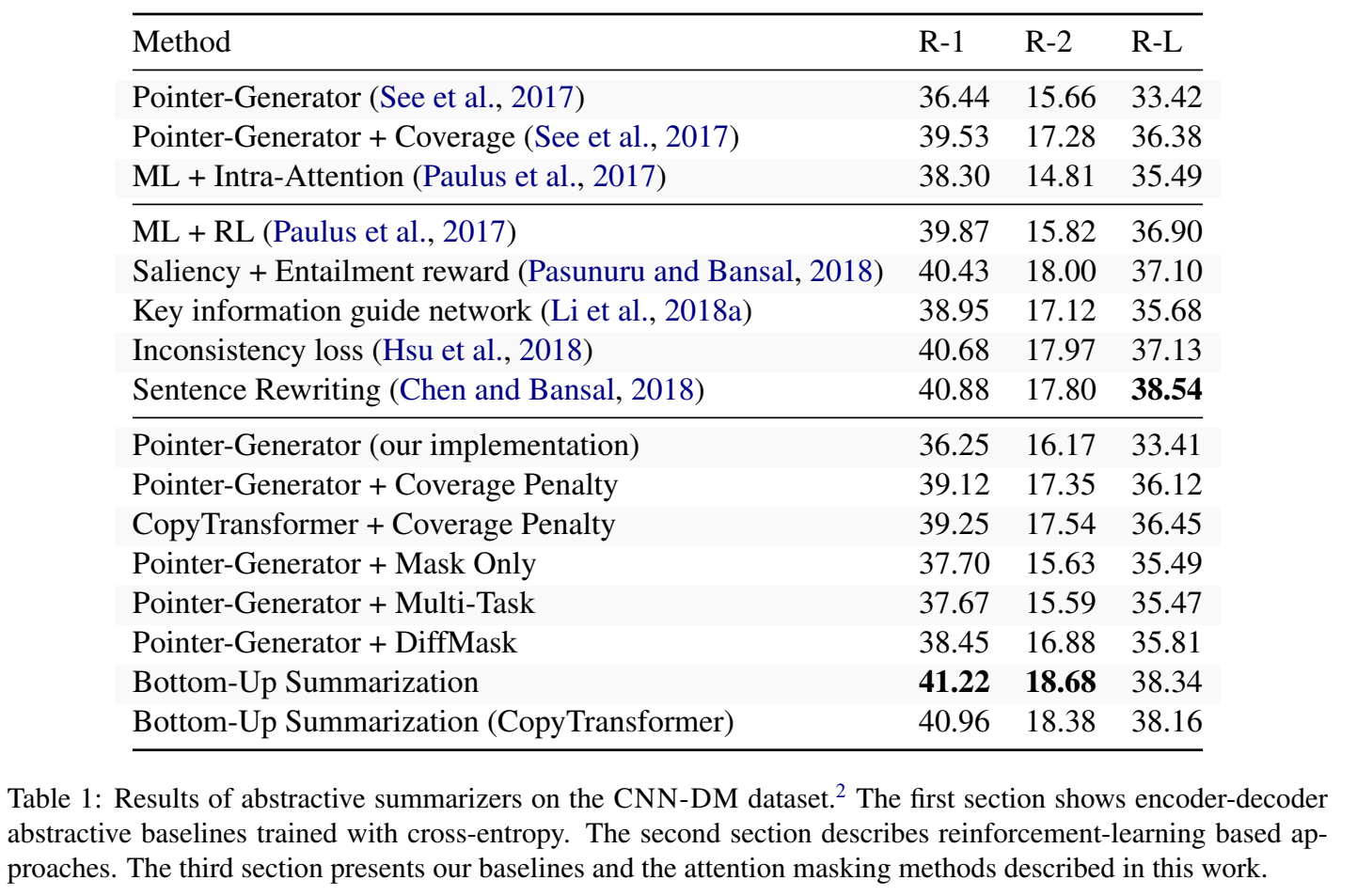
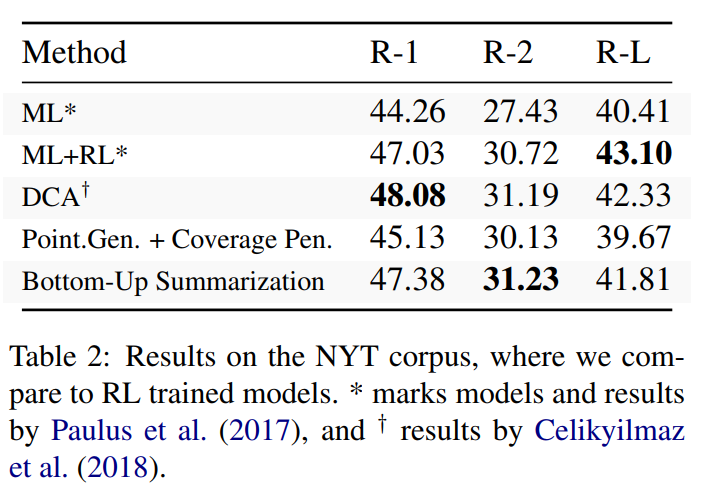
3. 实验结果
4. 模型分析
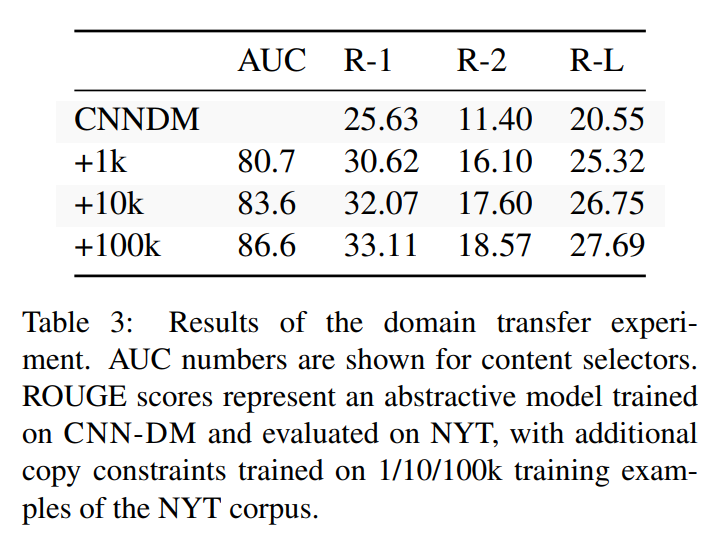
selector只需要少量训练样本,因此容易实现迁移:

selector的抽取效果:
(top-3是直接用selector中copy概率最高的3句话)
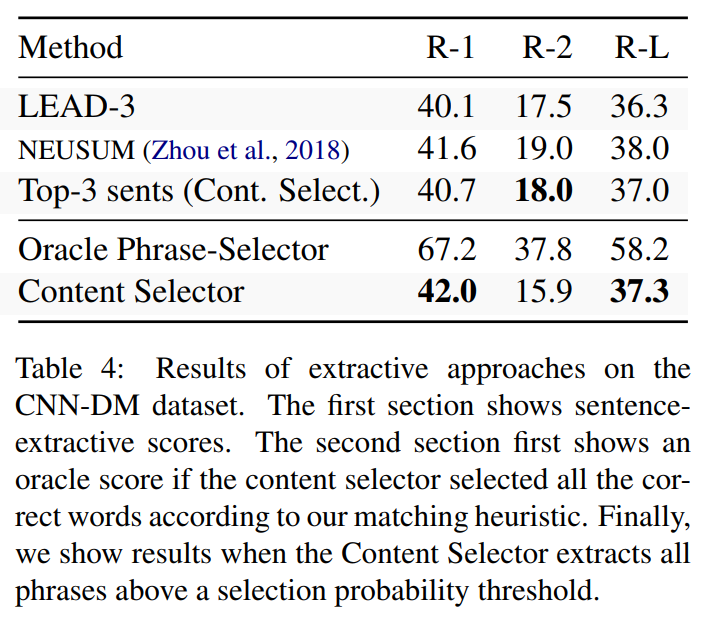
↑ R-1体现关键词抽取的能力,R-2体现流畅度、语法和组合词语的能力。
BottomUp的生成程度(复制机制的效果):生成文本中新词的比例,和其中不同词性的比例
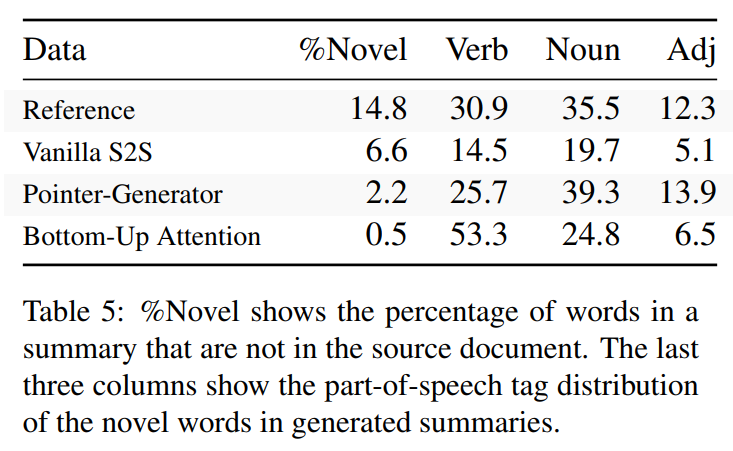
↑ 动词的变化主要是时态和人称的变化,名词是同义词
复制的长度(体现了content selection mask减少复制长句的效果):

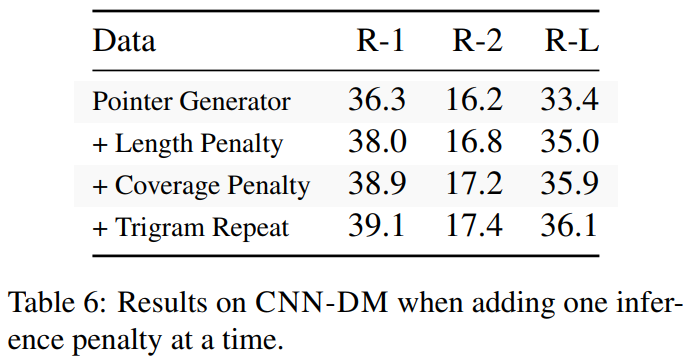
推理时得分罚项的消融实验(说明PGN其实挺强的,但是选择信息和推理方法不够好):
这篇关于Re66:读论文 Bottom-Up Abstractive Summarization的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)

