本文主要是介绍31省结婚、离婚、再婚等面板数据(1990-2022年),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
01、数据介绍
一般来说,经济发达地区的结婚和离婚率相对较高,而经济欠发达地区的结婚和离婚率相对较低。此外,不同省份的文化、习俗、社会观念等因素也会对结婚和离婚情况产生影响。
本数据从1990年至2022年,对各地区的结婚、离婚及再婚情况进行了全面统计。通过对这些数据的深入分析,我们可以洞察婚姻趋势的演变轨迹,以及地区之间的差异性。这些数据不仅反映了人们的婚姻选择、家庭形态的变化,还揭示了社会动态的演变。对于研究家庭结构和社会变迁的学者而言,这份数据提供了宝贵的参考依据和信息。
数据名称:各地区结婚、离婚、再婚等数据
数据来源:统计年鉴
数据年份:1990-2022年(包括原始、线性插值、回归填补无缺失3个版本)
02、数据指标
行政区划代码、地区、长江经济带、年份、结婚登记(万对)、内地居民登记结婚(万对)、内地居民初婚登记(万人)、内地居民再婚登记(万人)、涉外及港澳台居民登记结婚(万对)、离婚登记(万对)、粗离婚率(‰)。
03、数据截图及样例数据

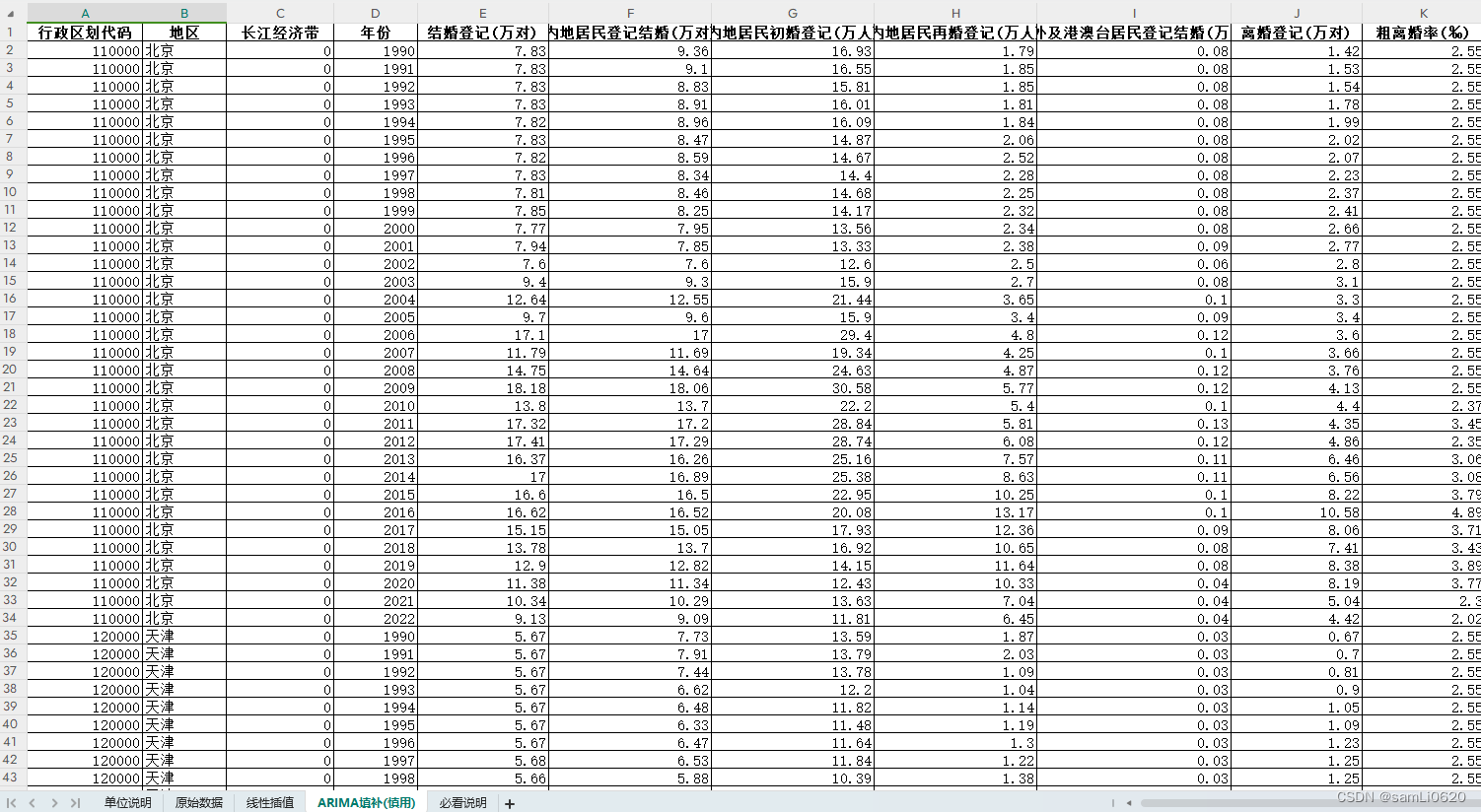
| 行政区划代码 | 地区 | 长江经济带 | 年份 | 结婚登记(万对) | 内地居民登记结婚(万对) | 内地居民初婚登记(万人) | 内地居民再婚登记(万人) | 涉外及港澳台居民登记结婚(万对) | 离婚登记(万对) | 粗离婚率(‰) |
| 110000 | 北京 | 0 | 1990 | 7.83 | 9.36 | 16.93 | 1.79 | 0.08 | 1.42 | 2.55 |
| 110000 | 北京 | 0 | 1991 | 7.83 | 9.1 | 16.55 | 1.85 | 0.08 | 1.53 | 2.55 |
| 110000 | 北京 | 0 | 1992 | 7.83 | 8.83 | 15.81 | 1.85 | 0.08 | 1.54 | 2.55 |
| 110000 | 北京 | 0 | 1993 | 7.83 | 8.91 | 16.01 | 1.81 | 0.08 | 1.78 | 2.55 |
| 110000 | 北京 | 0 | 1994 | 7.82 | 8.96 | 16.09 | 1.84 | 0.08 | 1.99 | 2.55 |
| 110000 | 北京 | 0 | 1995 | 7.83 | 8.47 | 14.87 | 2.06 | 0.08 | 2.02 | 2.55 |
| 110000 | 北京 | 0 | 1996 | 7.82 | 8.59 | 14.67 | 2.52 | 0.08 | 2.07 | 2.55 |
| 110000 | 北京 | 0 | 1997 | 7.83 | 8.34 | 14.4 | 2.28 | 0.08 | 2.23 | 2.55 |
| 110000 | 北京 | 0 | 1998 | 7.81 | 8.46 | 14.68 | 2.25 | 0.08 | 2.37 | 2.55 |
| 110000 | 北京 | 0 | 1999 | 7.85 | 8.25 | 14.17 | 2.32 | 0.08 | 2.41 | 2.55 |
| 110000 | 北京 | 0 | 2000 | 7.77 | 7.95 | 13.56 | 2.34 | 0.08 | 2.66 | 2.55 |
| 110000 | 北京 | 0 | 2001 | 7.94 | 7.85 | 13.33 | 2.38 | 0.09 | 2.77 | 2.55 |
| 110000 | 北京 | 0 | 2002 | 7.6 | 7.6 | 12.6 | 2.5 | 0.06 | 2.8 | 2.55 |
| 110000 | 北京 | 0 | 2003 | 9.4 | 9.3 | 15.9 | 2.7 | 0.08 | 3.1 | 2.55 |
| 110000 | 北京 | 0 | 2004 | 12.64 | 12.55 | 21.44 | 3.65 | 0.1 | 3.3 | 2.55 |
| 110000 | 北京 | 0 | 2005 | 9.7 | 9.6 | 15.9 | 3.4 | 0.09 | 3.4 | 2.55 |
| 110000 | 北京 | 0 | 2006 | 17.1 | 17 | 29.4 | 4.8 | 0.12 | 3.6 | 2.55 |
| 110000 | 北京 | 0 | 2007 | 11.79 | 11.69 | 19.34 | 4.25 | 0.1 | 3.66 | 2.55 |
| 110000 | 北京 | 0 | 2008 | 14.75 | 14.64 | 24.63 | 4.87 | 0.12 | 3.76 | 2.55 |
| 110000 | 北京 | 0 | 2009 | 18.18 | 18.06 | 30.58 | 5.77 | 0.12 | 4.13 | 2.55 |
| 110000 | 北京 | 0 | 2010 | 13.8 | 13.7 | 22.2 | 5.4 | 0.1 | 4.4 | 2.37 |
| 110000 | 北京 | 0 | 2011 | 17.32 | 17.2 | 28.84 | 5.81 | 0.13 | 4.35 | 3.45 |
| 110000 | 北京 | 0 | 2012 | 17.41 | 17.29 | 28.74 | 6.08 | 0.12 | 4.86 | 2.35 |
| 110000 | 北京 | 0 | 2013 | 16.37 | 16.26 | 25.16 | 7.57 | 0.11 | 6.46 | 3.06 |
| 110000 | 北京 | 0 | 2014 | 17 | 16.89 | 25.38 | 8.63 | 0.11 | 6.56 | 3.08 |
| 110000 | 北京 | 0 | 2015 | 16.6 | 16.5 | 22.95 | 10.25 | 0.1 | 8.22 | 3.79 |
| 110000 | 北京 | 0 | 2016 | 16.62 | 16.52 | 20.08 | 13.17 | 0.1 | 10.58 | 4.89 |
| 110000 | 北京 | 0 | 2017 | 15.15 | 15.05 | 17.93 | 12.36 | 0.09 | 8.06 | 3.71 |
| 110000 | 北京 | 0 | 2018 | 13.78 | 13.7 | 16.92 | 10.65 | 0.08 | 7.41 | 3.43 |
| 110000 | 北京 | 0 | 2019 | 12.9 | 12.82 | 14.15 | 11.64 | 0.08 | 8.38 | 3.89 |
| 110000 | 北京 | 0 | 2020 | 11.38 | 11.34 | 12.43 | 10.33 | 0.04 | 8.19 | 3.77 |
| 110000 | 北京 | 0 | 2021 | 10.34 | 10.29 | 13.63 | 7.04 | 0.04 | 5.04 | 2.3 |
| 110000 | 北京 | 0 | 2022 | 9.13 | 9.09 | 11.81 | 6.45 | 0.04 | 4.42 | 2.02 |
04、下载链接:https://download.csdn.net/download/samLi0620/89132050
这篇关于31省结婚、离婚、再婚等面板数据(1990-2022年)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







