本文主要是介绍使用Pandas实现股票交易数据可视化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、折线图:展现股价走势
1.1、简单版-股价走势图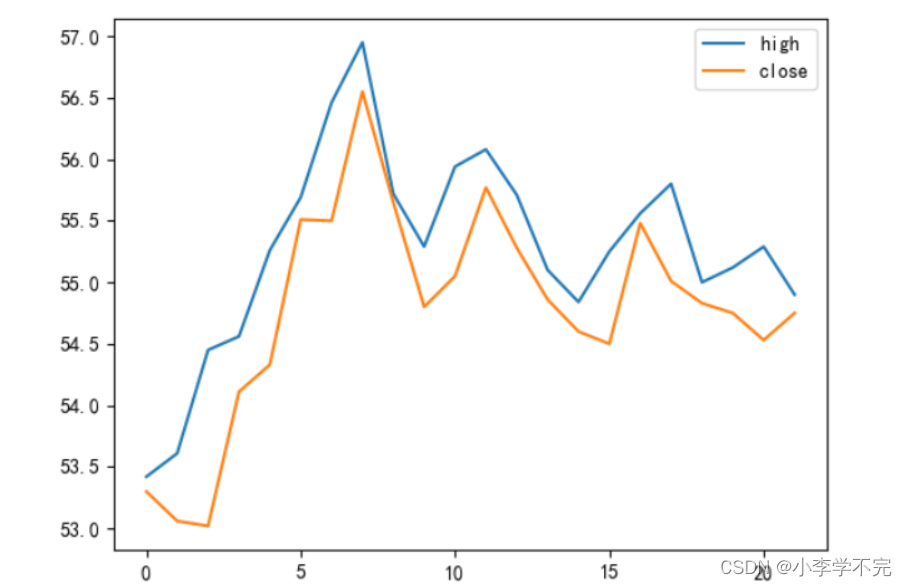
# 简洁版import pandas as pdimport matplotlib.pyplot as plt# 读取CSV文件df = pd.read_csv('../数据集/格力电器.csv')data = df[['high', 'close']].plot()plt.show()首先通过df[['high','close']]从df中获取最高价和收盘价这两列特征数据,其为一个DataFrame数组对象,调用该对象的plot()对象,就可以完成绘制。
plot()函数生成图形时,默认将DataFrame对象的索引传给Matplotlib绘制X轴,DataFrame对象的各列数据作为Y轴分别绘制折线等图形。使用plt.show()函数展示。
| 参数名称 | 描述 |
|---|---|
| x | 指定应用于X轴的行标签或位置,默认为None,仅对DataFrame有效 |
| y | 指定应用于Y轴的行标签或位置,如果有多个,存放于list中,默认为None,仅对DataFrame有效 |
| kind | str,指定绘制的图形类型:"line":折线图(默认)。"density":密度图。"bar":条形图。"area":面积图。"barth":横向条形图。"pie":饼图。"hist":直方图。"scatter":散点图,需要指定X轴、Y轴**。"box":箱线图。"hexbin":蜂巢图,需要指定X轴、Y轴。"kde":密度图。 |
| ax | 绘制图形的subplot对象,默认为当前的subplot对象 |
| subplots | bool。是否针对不同列单独绘制子图 |
| sharex | 如果ax为None,则默认为True,否则为False |
| sharey | bool。在subplots=True前提下,如果有子图,子图是否共享Y轴,默认为False |
| figsize | 元组型。(wigth,height),指定画布尺寸大小,单位为英寸 |
| user_index | bool。是否使用索引作为X轴数据,默认为True |
| title | 标题 |
| grid | bool。是否显示网格 |
| legend | bool。是否显示网格的图例,默认为True |
| xticks | 序列。设置X轴的刻度值 |
| yticks | 序列。设置Y轴的刻度值 |
| xlim | 数值(最小值)、列表或元组(区间范围)。设置X轴范围 |
| ylim | 数值(最小值)、列表或元组(区间范围)。设置Y轴范围 |
| xlabel | 设置X轴的名称。默认使用行索引名。仅支持Pandas1.1.0及以上版本 |
| ylabel | 设置Y轴的名称。仅支持Pandas1.1.0及以上版本 |
| rot | int。设置轴刻度旋转角度,默认为None |
| fontsize | int。设置轴刻度字体大小 |
| colormap | string或colormap对象。设置图区域颜色 |
| secondary_y | bool或序列。是否需要在次Y轴上绘制,或者在次Y轴上绘制哪些列 |
| stacked | bool,是否创建堆积图。折线图和条形图默认为F alse,面积图默认为True |
1.2、美化版-股价走势图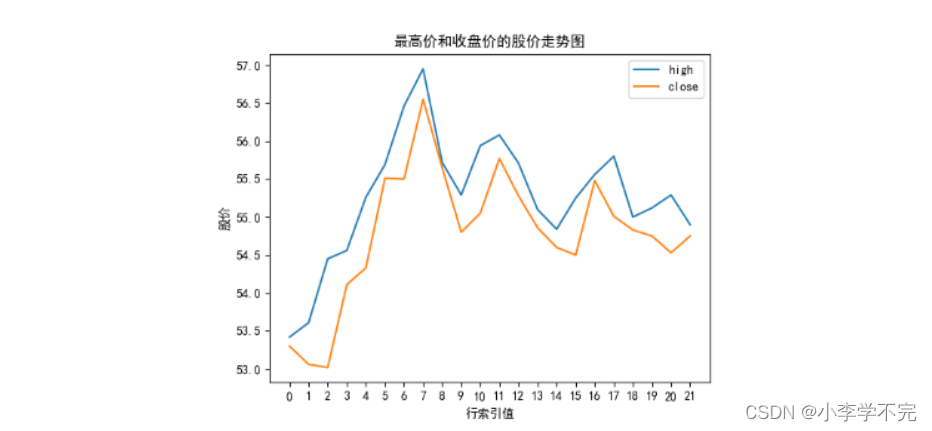
import pandas as pdimport matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文格式plt.rcParams['axes.unicode_minus'] = False # 正常显示负号df = pd.read_csv('../数据集/格力电器.csv')data = df[['high','close']].head(22)# x轴刻度x_ticks = [i for i in range(data.shape[0])]# 美化版data.plot(title='最高价和收盘价的股价走势图',xlabel='行索引值', # 默认值ylabel='股价',xticks=x_ticks)plt.show() # 展示图形1.3、添加日期的股价走势图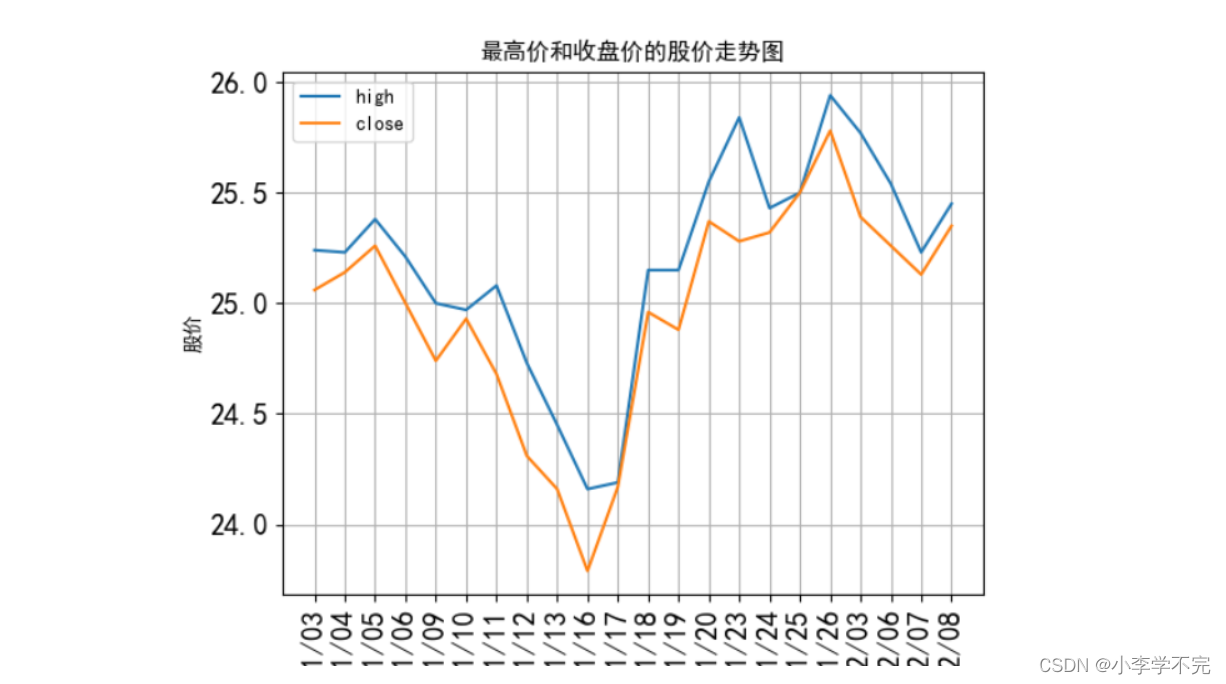
import pandas as pdimport matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文格式plt.rcParams['axes.unicode_minus'] = False # 正常显示负号df = pd.read_csv('../数据集/格力电器.csv')# 日期转换->'2024/04/08/date = df['trade_date'].astype(str)year = date.str[:4] # 提取前4位,即年份month=date.str[4:6] # 提取月day=date.str[6:8] # 提取日# 合并日期,格式为YYYY/MM/DD格式的字符串df['trade_date'] = year + '/' + month + '/' +daydf.sort_values(by='trade_date',inplace=True) # 由大到小排序x_ticks = [i for i in range(22)]df.head(22).plot(x='trade_date',y=['high','close'],xticks = x_ticks, # X轴刻度值rot=90, # X轴刻度值倾斜度fontsize=15, # 字体大小title='最高价和收盘价的股价走势图',xlabel='日期', # 默认值ylabel='股价',grid=True # 显示网格线)plt.show()二、散点图:展示股价影响因素
2.1、散点图
使用plot()函数绘制散点图,将kind参数设置为"scatter"即可,
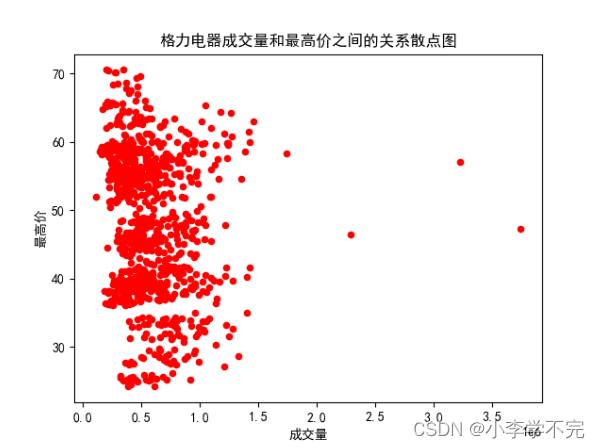
import pandas as pdimport matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文格式plt.rcParams['axes.unicode_minus'] = False # 正常显示负号# 读取数据df = pd.read_csv('../数据集/格力电器.csv')# ---------------------------## 绘制图形df.plot(x='vol',y='high',kind='scatter',# 默认为折线图,scatter为散点图title='格力电器成交量和最高价之间的关系散点图',xlabel='成交量',ylabel='最高价',c='red',)# 展示图形plt.show()2.2、散点图-子图
若还想展示成交量、成交额、收盘价、涨跌额、涨跌幅之间关系的散点图,可以作为子图放到一个大的画布中:
import pandas as pdimport matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文格式plt.rcParams['axes.unicode_minus'] = False # 正常显示负号df = pd.read_csv('../数据集/格力电器.csv') # # 读取数据fig,axes = plt.subplots(2,2) # 准备画布# 子图1:df.plot(x='vol',y='high',kind='scatter',# 默认为折线图,scatter为散点图title='格力电器成交量和最高价之间的关系散点图',xlabel='成交量',ylabel='最高价',c='red',ax=axes[0][0])# 子图2:df.plot(x='vol',y='close',kind='scatter',# 默认为折线图,scatter为散点图title='格力电器成交量和收盘价之间的关系散点图',xlabel='成交量',ylabel='收盘价',c='green',ax=axes[0][1])# 子图3:df.plot(x='amount',y='high',kind='scatter',# 默认为折线图,scatter为散点图title='格力电器成交额和最高价之间的关系散点图',xlabel='成交额',ylabel='最高价',c='red',ax=axes[1][0])# 子图4:df.plot(x='amount',y='close',kind='scatter',# 默认为折线图,scatter为散点图title='格力电器成交额和收盘价之间的关系散点图',xlabel='成交额',ylabel='收盘价',c='green',ax=axes[1][1])plt.subplots_adjust(wspace=0.8, # 子图之间的距离hspace=0.5)plt.show()三、条形图:展现同比成交量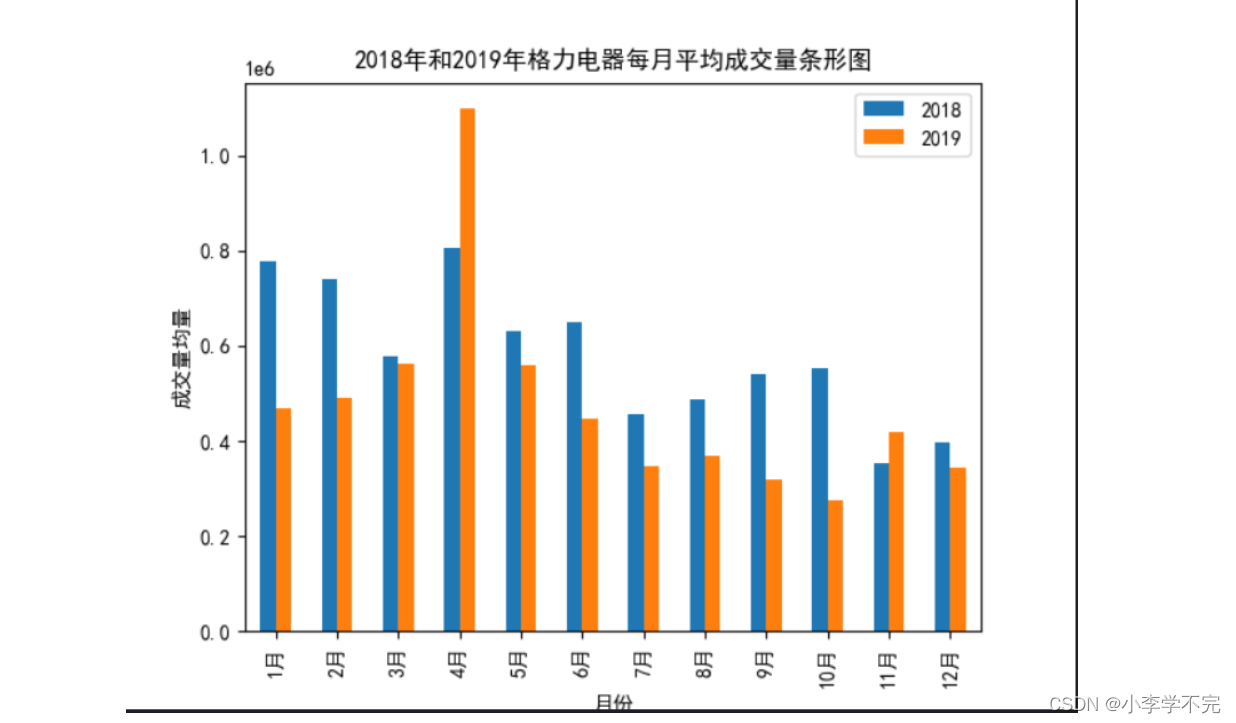
import matplotlib.pyplot as pltimport pandas as pdplt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文格式plt.rcParams['axes.unicode_minus'] = False # 正常显示负号# 1、读取CSV文件df = pd.read_csv('../数据集/格力电器.csv')date = df['trade_date'].astype(str)# 2、提取年和月year = date.str[:4]month = date.str[4:6]df['year'] = yeardf['month'] = month# 3、按照年和月分组,获取2018和2019年的每月平均成交量group = df[['year', 'month', 'vol']].groupby(by=['year', 'month']) # 按照年和月分组g_m = group.mean() # 获取所有字段的平均值m_18 = g_m['vol']['2018'] # 获取2018年每月平均成交量m_19 = g_m['vol']['2019'] # 获取2019年每月平均成交量# 4、将2018和2019年每月成交量平均值数据存储于DataFrame中df2 = pd.DataFrame(list(zip(m_18, m_19)), index=[str(i) + '月' for i in range(1, 13)], columns=['2018', '2019'], )# 5、绘制条形图df2.plot(kind='bar', # 条形图title='2018年和2019年格力电器每月平均成交量条形图',xlabel='月份',ylabel='成交量均量')plt.show()若要绘制堆叠条形图,只需在plot()函数中将参数stacked设置为True即可。
若要将条形显示为横向条形图,只需将参数kind设置为barh即可。
四、饼图:展现成交量占比关系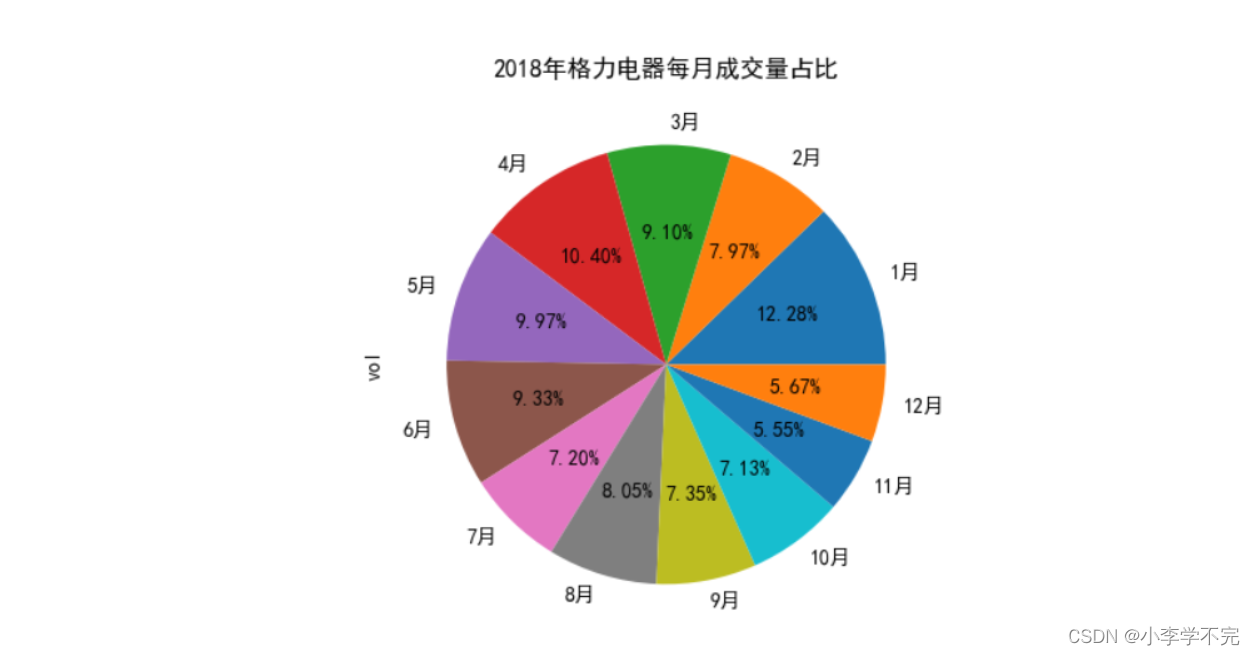
import pandas as pdimport matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文格式plt.rcParams['axes.unicode_minus'] = False # 正常显示负号#1、读取CSV文件df = pd.read_csv('../数据集/格力电器.csv')#2、提取年和月date = df['trade_date'].astype(str)year = date.str[:4] # 提取前4位,即年份month = date.str[4:6] # 提取月份df['year'] = year # 将年份插入到数据集中df['month'] = month # 将月份插入到数据集中#3、按照年和月分组,获取2018年每月总成交量group = df[['year','month','vol']].groupby(by=['year','month']) # 按年和月分组g_s = group.sum() # 获取所有字段总和s_18 = g_s['vol']['2018'] # 获取2018年每月总成交量s_18.index= [str(i) + '月' for i in range(1,13)]#4、绘制图形s_18.plot(kind='pie',title='2018年格力电器每月成交量占比',autopct='%.2f%%', # 百分比)plt.show()五、K线图:展现股价走势
5.1、mplfinance的安装与下载
pip install mplfinance
5.2、绘制K线图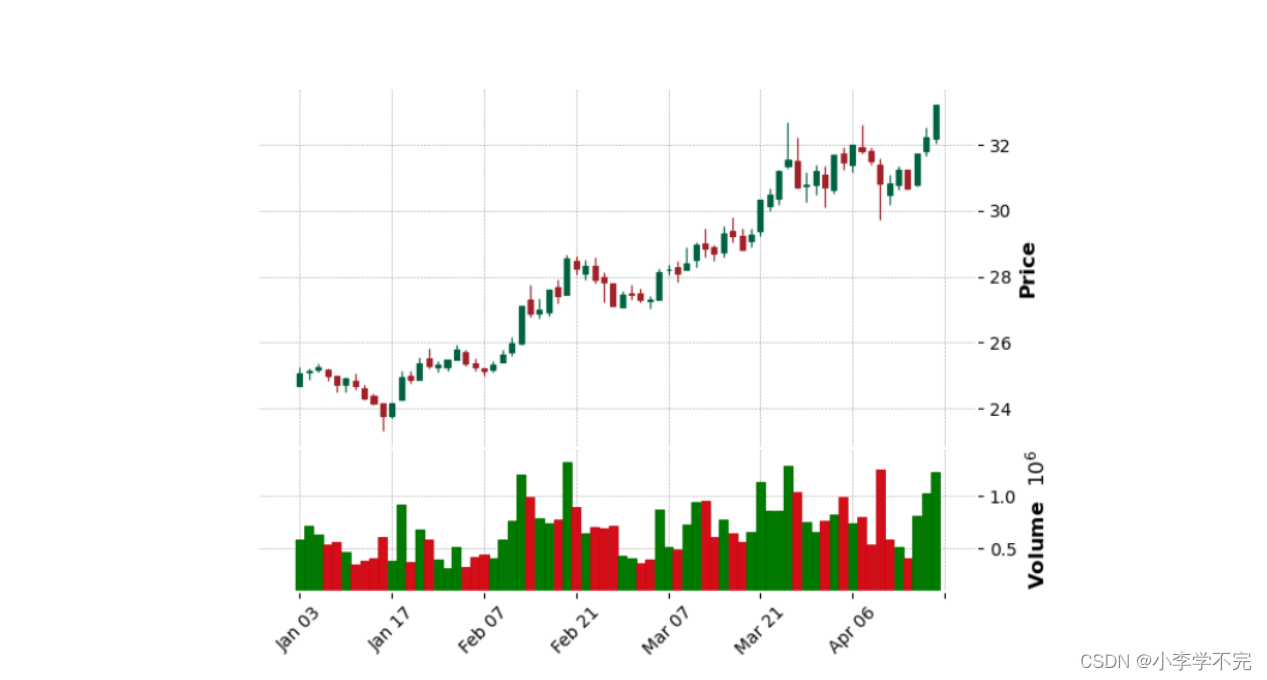
import mplfinance as mpfimport pandas as pddata = pd.read_csv('../数据集/格力电器.csv')data.sort_values(by=['trade_date'], inplace=True)date = data['trade_date'].astype(str)year = date.str[:4]month = date.str[4:6]day = date.str[6:8]data['trade_date'] = year + '/' + month + '/' + daydata.index = pd.DatetimeIndex(data['trade_date'])data = data[['open', 'close', 'high', 'low', 'vol']]data.columns = ['Open', 'Close', 'High', 'Low', 'Volume']mpf.plot(data.head(70), # 绘制图形的数据(选取前70条)type='candle', # 设置图像类型volume=True, # 是否显示成交量style='charles')# 设置图表样式为"charles"mplfinance的plot()函数的常用参数:
| 参数 | 描述 |
|---|---|
| type | 设置绘制的 图像类型,有'ohlc'、'candle'、'line'、'renko'类型 |
| volume | 是否显示成交量,默认不显示 |
| style | 设置的图表样式,可以通过mpf.available_style()方法获取mplfinance提供的样式名称,有'binance','blueskies','brasil'....。可以自定义样式。 |
| title | 设置标题 |
| ylabel | 设置主图Y轴标题 |
| ylabel_lower | 设置次图的Y轴标题 |
| mav | 设置均线,如2日均线,5日均线,10日均线等 |
| savefig | 保存图片 |
下面通过自定义图表样式来美化K线图:
import mplfinance as mpf
import pandas as pddata = pd.read_csv('../数据集/格力电器.csv')
data.sort_values(by=['trade_date'], inplace=True)
date = data['trade_date'].astype(str)year = date.str[:4]
month = date.str[4:6]
day = date.str[6:8]
data['trade_date'] = year + '/' + month + '/' + day
data.index = pd.DatetimeIndex(data['trade_date'])data = data[['open', 'close', 'high', 'low', 'vol']]
data.columns = ['Open', 'Close', 'High', 'Low', 'Volume']# 设置K线颜色
my_color = mpf.make_marketcolors(up='red', # 设置阳线柱填充颜色down='green', # 设置阴线柱填充颜色edge='i', # 设置蜡烛线边缘颜色wick='black', # 设置蜡烛上下影线的颜色volume={'up': 'red', 'down': 'green'} # 设置成交量颜色)# 设置图表样式
my_style = mpf.make_mpf_style(marketcolors=my_color,gridaxis='both', # 设置网格线位置,both双向gridstyle='-.', # 设置网格线类型base_mpf_style='charles',rc={'font.family': 'SimHei'} # 设置字体为黑体)# 绘制K线图
mpf.plot(data.head(70),type='candle', # 设置图像类型'ohlc'/'candle'/'line/renko'mav=(2, 5, 10), # 绘制2日均线、5日均线和10日均线volume=True, # 显示成交量style=my_style, # 自定义图表样式title='格力电器2018年K线图', # 设置标题ylabel='价格', # 设置主图Y轴标题ylabel_lower='成交量' # 设置次图Y轴标题)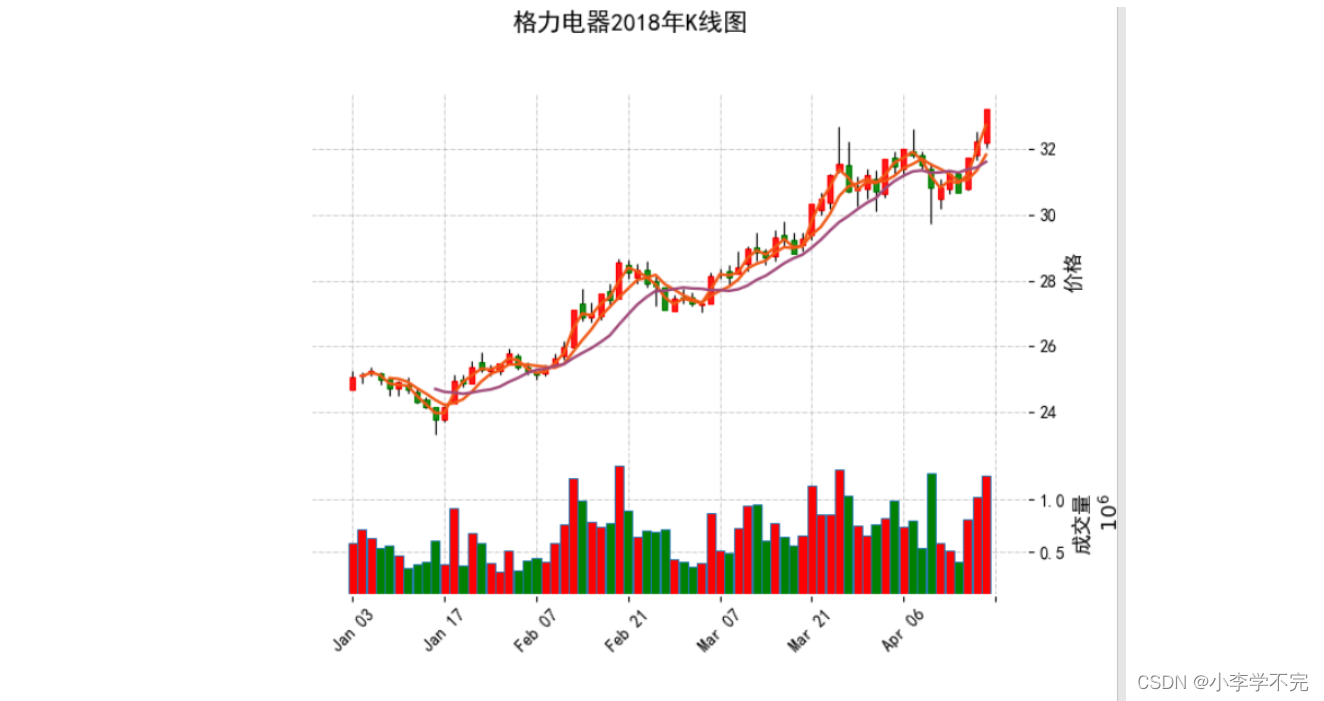
mplfinance的make_mpf_style()函数的常用参数:
| 参数 | 描述 |
|---|---|
| base_mpf_style | 使用mplfinance中的系统样式,可以在make_marketcolors方法中使用,也可以在make_mpf_style中使用 |
| base_mpl_style | 使用mplfinance中的系统样式,比如:base_mpl_style='seaborn' |
| marketcolors | 使用自定义样式 |
| mavcolors | 设置nav均线颜色,必须使用列表传递参数 |
| facecolor | 设置前景色 |
| edgecolor | 设置边缘线颜色 |
| figcolor | 设置填充色 |
| gridcolor | 设置网格线颜色 |
| gridaxis | 设置网格线方向,'both'、'horizontal'、'vertical‘ |
| gridstyle | 设置网格线线型。'-'[或solid]、’-’[或dashed]、'-.'[或dashdot]、':'[或dotted]、None |
| y_on_right | 设置Y轴位置是否在左右 |
| rc | 使用rcParams的dict设置样式,如果内容与上面自定义的设置相同,那么自定义设置覆盖rcParams设置 |
这篇关于使用Pandas实现股票交易数据可视化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






