本文主要是介绍清华朱文武团队斩获NIPS 2018 AutoML挑战赛亚军,高校排名第一,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

来源:新智元
本文约2000字,建议阅读10分钟。
本文介绍了NIPS 2018 AutoML挑战赛的最终结果,清华大学计算机系朱文武团队斩获第二,高校排名雄踞第一。

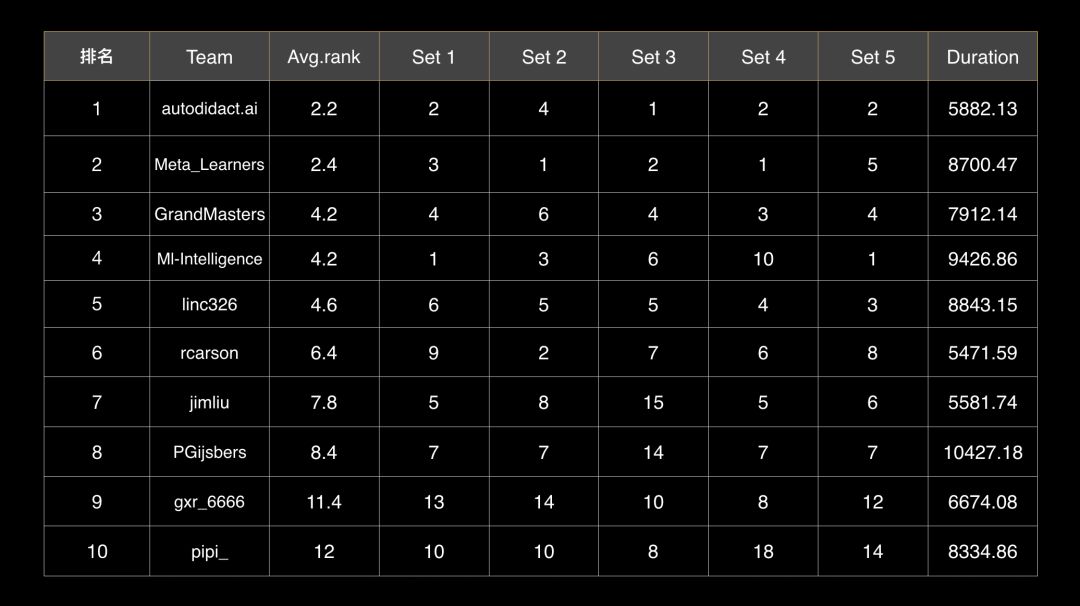
NIPS 2018 AutoML挑战赛结果出炉:印度团队autodidact.ai第一,清华计算机系朱文武实验室Meta_Learners团队斩获第二。
值得注意的是,清华Meta_Learners团队是本次参赛高校成绩第一,且仅与冠军差0.2个排名!
AutoML,全称为Automated Machine Learning,是机器学习领域的一个新兴方向。旨在自动化整个机器学习的流程,降低数据预处理、特征工程、模型选择、参数调节等环节中的人工成本。
随着机器学习系统的日益复杂化,AutoML得到了产学研各界的广泛关注,已成为人工智能领域最热门的研究方向之一。
本次赛事共有近三百支队伍参赛,包括了麻省理工学院、加州大学伯克利分校、德州农工大学、清华大学、北京大学等国内外顶尖高校,微软、腾讯、阿里巴巴等科技巨头,autodidact.ai、Rapids.ai等新兴创业公司,Auto-sklearn、Auto-keras等著名AutoML开源框架的作者团队。
根据官方公布的排名结果来看,朱文武实验室Meta_Learners团队在Set 2和Set 4上的排名均居第一,在其它3个Set上也都取得了较高名次。
全球名校、企业同台竞争:清华斩获第二,高校第一!
Meta_Learners团队成员包括计算机系博士毕业生张文鹏、在读硕士生熊铮、在读博士生蒋继研,由张文鹏担任队长,朱文武教授担任指导教师。
团队从2015年开始持续关注和布局AutoML领域,目前已经具备了较为丰富的领域知识和较为深厚的技术积累,今年首次参加AutoML比赛即摘得亚军。
今年的赛事题目聚焦于真实应用场景下存在概念迁移的大规模流式数据中的AutoML问题,对AutoML系统的自适应能力、鲁棒性都提出了较以往比赛更高的要求。
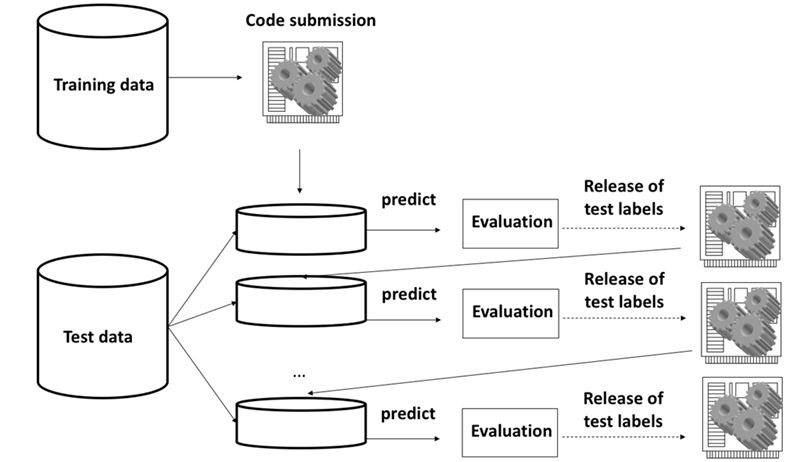
比赛分为两个阶段:Feedback阶段和AutoML阶段。
Feedback阶段是代码提交阶段。主办方会提供5个与第二阶段的数据集具有相似特性的训练数据集;参赛者在训练数据集上构建AutoML系统,并根据线上运行结果进行优化。
AutoML阶段是盲测阶段,无法进行代码提交。参赛者在Feedback阶段提交的最后一版代码会在5个全新的数据集上进行自动化的训练与测试,得到的盲测结果将作为比赛最终排名的依据。
每个数据集内部按时间顺序分为10个Batch,每个Batch代表终身(Lifelong)学习场景中的一个阶段。
参赛者提交的AutoML系统使用数据集中的第一个Batch作为训练数据生成初始模型,并在第一个测试Batch(整个数据集中的第二个Batch)上进行预测。随后,系统将得到当前测试Batch的标签,并对初始模型进行修正。系统将在后续的所有测试Batch上迭代进行预测与模型修正,直到完成对所有测试Batch的预测。
比赛制胜法宝:做好不同层次的平衡(Tradeoff)
在本次比赛中,Meta_Learners团队采用了梯度提升树(Gradient Boosting Tree),在传统的AutoML框架上,结合本次比赛数据的特性做了有针对性的设计:
特征工程方面,主要针对类别特征高基数、长尾分布的特点,采用了频数编码、中值编码等不同编码方式,以及离散化、分位数变换等处理技巧。
迁移适应方面,针对数据存在概念迁移的问题采用了自适应的流式编码技术。
资源控制方面,自动监测系统中各个组件的运算花销,并使用Bandit技术对搜索空间进行压缩和剪枝。
团队认为AutoML比赛的关键在于做好不同层次的平衡(Tradeoff)。
首先是宏观方法论层面的平衡。AutoML比赛和传统的数据挖掘比赛有很多相似之处,但也有本质的不同。相似之处在于特征工程都发挥着至关重要的作用。不同之处在于,传统数据挖掘比赛的训练集和测试集一般来自于同一场景,在第一阶段表现好的方法,在第二阶段更换新的测试集后一般仍然会好。但是在AutoML比赛中,第二阶段会更换崭新的数据集(与第一阶段的数据集有一定相似性,但并不同源)。
因此,AutoML系统如果过分适应第一阶段的数据,就会导致在第二阶段的排名出现较大波动。所以该团队的策略是并不刻意追求第一阶段的排名,而是注重提升整个系统的泛用性和自适应能力,也就是做好第一阶段和第二阶段的平衡。
其次是搜索空间和资源约束之间的平衡。搜索空间大会覆盖更多的候选配置(特征、算法和参数的组合),但太大则会超出系统资源的约束。AutoML系统需要根据不同数据集的大小和数据特性,自适应地设计和分配搜索空间,以保证在不超出资源限制的前提下,选择出更好的配置。
AutoML技术的关键在于如何理解Auto的过程
而此次比赛结果,Meta_Learners团队与第一名仅差0.2个排名,对此次的惜败,团队成员表示时间利用不够充分是主要理由。
比赛中期,由于一些临时事件的耽误,团队内部交流和讨论不够充分,导致进度停滞了一段时间。
在处理概念迁移的过程中,团队曾出现技术路线的偏离,在数周内进展缓慢。团队最初沿着序列化检测和自适应的思路进行探索,效果并不理想;经过仔细分析,团队发现Batch间的迁移并无趋同性,不符合序列化模型的场景假设。因此,团队放弃了该技术路线,但确实耽误了很多时间。
由于前面时间的耽误,比赛最后阶段,模型整合优化的时间不够充分,一些在某些数据集上效果良好的算法并没有纳入最终AutoML框架的自动选择范围内。例如,迁移学习中基于密度比估计的重要性采样(Importance sampling),在波动较大的Batch上有很好的效果,但算法本身计算成本高,需要做进一步优化。最终由于时间有限,团队并没有把该方法优化得很好,也就没有把它纳入最终的解决方案。
对于AutoML技术本身,团队认为,关键在于如何理解Auto的过程。对此,不同研究者有着不同的视角,进而衍生出了基于贝叶斯优化、强化学习、迁移学习、遗传算法、Bandit和梯度下降等不同方法的技术路线。更好的理解会有助于产生出更优化的算法。
学术界和产业界都关注如何提高AutoML算法的性能和效率。相对而言,有一些问题学术界会关注得更多一点,比如,算法的最优性保证、算法中的Auto可以做多少层等;与此相对应,产业界可能会更关注一些具体实际场景中的AutoML问题,比如,本次比赛关注存在概念迁移的大规模流式数据中的AutoML问题。当然,团队也从中提取了一些有研究价值的学术问题。
团队介绍
Meta_Learners团队由清华大学博士张文鹏、硕士研究生熊铮、博士研究生蒋继研组成,由张文鹏担任队长。
在本次比赛中,张文鹏负责技术路线的选择和比赛节奏的把控;熊铮负责基础框架、控制模块的构建和部分特征工程;蒋继研负责概念迁移的处理和部分特征工程。
该团队从2015年开始关注AutoML领域,当时谷歌还没有提出相关概念。最初,张文鹏发现神经网络的调参非常复杂,进而意识到AutoML的价值和潜力。朱文武老师也非常认同,果断组建团队开始该领域的研究。在该团队中,熊铮主要关注基于贝叶斯优化的AutoML系统,蒋继研则关注Bandit方法在AutoML中的应用。
2017年,该团队提出了利用强化学习构建决策树模型的元学习算法并发表于NIPS 2017的Meta Learning Workshop,这也是国内相关领域最早的研究成果之一。
此外,该团队目前也有布局特征工程、深度学习、计算机视觉、自然语言处理等领域的AutoML研究。


这篇关于清华朱文武团队斩获NIPS 2018 AutoML挑战赛亚军,高校排名第一的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!

![BUUCTF靶场[web][极客大挑战 2019]Http、[HCTF 2018]admin](https://i-blog.csdnimg.cn/direct/ed45c0efd0ac40c68b2c1bc7b6d90ebc.png)






