本文主要是介绍GEE数据集——巴基斯坦国家级土壤侵蚀数据集(2005 年和 2015 年),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介
巴基斯坦国家级土壤侵蚀数据集(2005 年和 2015 年)
该数据集采用修订的通用土壤流失方程 (RUSLE),并考虑了六个关键影响因素:降雨侵蚀率 (R)、土壤可侵蚀性 (K)、坡长 (L)、坡陡 (S)、覆盖管理 (C) 和保护措施 (P),对 2005 年至 2015 年巴基斯坦的土壤侵蚀动态进行了全面评估。土壤侵蚀图从低侵蚀率到极高侵蚀率分为四个等级,有助于了解研究期间土壤侵蚀模式的空间分布和变化。侵蚀等级之间的过渡分析揭示了侵蚀强度的变化,同时对巴基斯坦七个行政单位的空间模式和动态进行了评估。数据集显示,在人口增长、基础设施发展和自然资源开发引起的土地覆盖和土地利用变化的推动下,全国范围内的土壤侵蚀从 2005 年的 1.79 ± 11.52 吨/公顷-¹年-¹增加到 2015 年的 2.47 ± 18.14 吨/公顷-¹年-¹。利用修订的通用土壤流失方程 (RUSLE) 模型和六个影响因素,以 1 平方公里的空间分辨率对 2005 年和 2015 年巴基斯坦的土壤侵蚀动态进行全面评估。水土流失图分为低、中、高和极高四个等级,显示全国水土流失从 1.79 吨/公顷-¹年-¹增加到 2.47 吨/公顷-¹年-¹。点击此处阅读论文全文
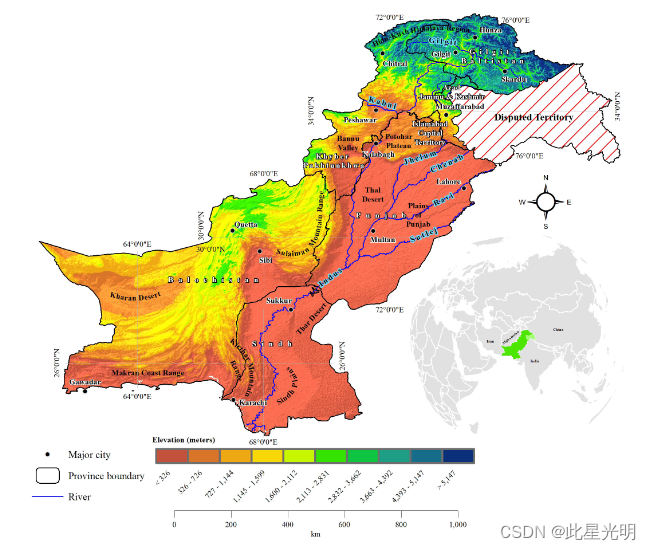
巴基斯坦国家级土壤侵蚀数据集(2005 年和 2025 年)的 1 千米空间分辨率数据可在此处获取
结论
我们的研究利用免费提供的遥感数据和易于操作的 RUSLE,对巴基斯坦国家和国家以下各级的十年(2005-2015 年)土壤侵蚀变化进行了定量空间评估。它提供了巴基斯坦七个行政单位土壤侵蚀强度的基线信息。与基于实地的评估和评价相比,目前的方法为土壤侵蚀动态提供了一个可行的解决方案。这项研究采用了一种新颖的方法,不仅将土壤侵蚀结果与当地的土壤侵蚀研究进行比较,还与全球数据集进行比较,并根据纬度窗口提取土壤侵蚀率。这项研究结果将用于确定土壤侵蚀易发区,并在国家和国家以下范围转换 LCLU,以规划省级流域管理活动。从这些结果中可以得出有关巴基斯坦土壤和 LCLU 变化动态的国际和国内报告。高纬度窗口的土壤侵蚀变化动态报告将有助于规划者、政策制定者和决策者控制/减少土壤侵蚀,并确定保护的优先事项。土壤侵蚀变化与 LCLUC(2005-2015 年)之间的双变量分析表明,有必要在全境范围内采取土壤侵蚀控制措施。
代码
var pk_soil_erosion_2005 = ee.Image('projects/sat-io/open-datasets/NSSED-PAKISTAN/Pakistan_soil_erosion_2005_1km');
var pk_soil_erosion_2015 = ee.Image('projects/sat-io/open-datasets/NSSED-PAKISTAN/Pakistan_soil_erosion_2015_1km');// Define the visualization parameters using SLD format
var sld_visualization = {min: 0,max: 20,palette: ["#C2533C","#F7D728","#0EC441","#0B2C7B"],sld:'<RasterSymbolizer>' +'<ColorMap type="ramp">' +'<ColorMapEntry color="#00FF00" quantity="1" label="Low" />' +'<ColorMapEntry color="#FFFF00" quantity="5" label="Medium" />' +'<ColorMapEntry color="#FFA500" quantity="20" label="High" />' +'<ColorMapEntry color="#FF0000" quantity="21" label="Very High" />' +'</ColorMap>' +'</RasterSymbolizer>'
};// Center the map on the image
Map.centerObject(pk_soil_erosion_2005,6);// Add the layers with the specified visualization
Map.addLayer(pk_soil_erosion_2005, sld_visualization, "Soil Erosion 2005");
Map.addLayer(pk_soil_erosion_2015, sld_visualization, "Soil Erosion 2015");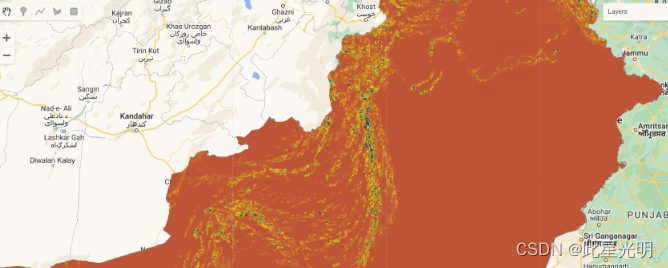
文章引用
Gilani, H., Ahmad, A., Younes, I., & Abbas, S. (2021). Impact assessment of land cover and land use changes on soil erosion changes (2005–2015) in Pakistan. Land Degradation & Development, 33(1):204–217. [doi.org/10.1002/ldr.4138](https://doi.org/10.1002/ldr.4138)
数据引用
Gilani, Hammad, Ahmad, Adeel, Younes, Isma, & Abbas, Sawaid. (2021). National-scale soil erosion dataset for Pakistan (2005 and 2025) at 1km spatial resolution (1.0) [Dataset]. Zenodo. https://doi.org/10.5281/zenodo.10694225
代码链接
https://code.earthengine.google.com/?scriptPath=users/sat-io/awesome-gee-catalog-examples:soil-properties/NATIONAL-SOIL-ERODABILITY-DATASET-PK
License¶
The datasets are licensed under a Creative Commons Attribution (CC-BY) 4.0 International License.
Created by: Gilani et al. 2021
Curated in GEE by : Adeel Ahmad and Samapriya Roy
Keywords: soil erosion, soil conservation, RUSLE, Pakistan, temporal soil erosion
Last updated in GEE: 2024-02-20
网址推荐
0代码在线构建地图应用
https://sso.mapmost.com/#/login?source_inviter=nClSZANO
机器学习
https://www.cbedai.net/xg
这篇关于GEE数据集——巴基斯坦国家级土壤侵蚀数据集(2005 年和 2015 年)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







