本文主要是介绍张鸿轩:大数据让无形之风尽在掌握 | 优秀毕业生专访,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

[ 导读 ]清华-青岛数据科学研究院(以下简称“数据院”)自2014年4月成立以来,秉承“学校统筹,问题引导,社科突破,商科优势,工科整合,业界联盟”的指导原则,搭建跨学科交叉融合平台,创新跨学科交叉培养模式,培养具有大数据思维和创新能力的“π”型人才。
大数据能力提升项目由清华大学研究生院,数据院及相关院系共同组织,面向在校研究生(包括硕士和博士)。项目形成大数据思维与技能、跨界学习、实操应用相结合的大数据课程体系和线上线下混合式教学模式,旨在提升学生数据分析和管理数据的能力,让学生在本专业的学习和实践中扩宽思维,并锻炼在本专业领域的数据研究能力。
截至2019年6月,已有来自31个院系的271名同学获得“大数据能力提升项目”证书,其中信息类同学160人,非信息类同学111人。
大数据提升项目究竟为同学们带来了什么改变?下面,就让我们聆听优秀毕业生们与大数据结缘的故事,一起发现大数据对他们学习、科研和创业的启发与帮助吧!

张鸿轩是清华大学电气工程专业硕士3字班的同学,师从胡伟副教授,即将入职中国南方电网电力调度控制中心。目前,主要研究方向是多能互补电力系统的优化运行和电力大数据的应用,参与并承担了相关研究领域的一项国家重点研发计划子课题和多项国家电网科技项目,发表了2篇SCI期刊论文和2篇EI会议。
志趣所向
“大数据项目让我找到了自己真正的兴趣”
“
大学阶段有个很大的优势就是“试错”成本低,在清华这样一个平台上,有着接触各类新鲜事物的机会,我们可以通过不断尝试从而找准自己真正感兴趣的研究方向。
”张鸿轩向我们分享,自己与大数据的结缘是一个不断尝试的过程,并在这个过程中逐渐感受到了对大数据相关技术的浓厚兴趣。“最初学习大数据系统基础课时,我还只能算是一个小白,在老师的教导和小组成员的帮助下,我才逐渐成长,最终能在一个比较成功的课程项目中尽自己的一份力,这也是很有收获感的一件事;后来,人工智能课程则让我在基础理论上有了更全面的认识,也第一次让我觉得自己真的对于大数据相关技术有着浓厚的兴趣;而后随着不断地学习和进步,我在大数据分析课程中已经能够快速、高质量地完成作业,也对大数据技术和交叉学科的研究愈发热爱。”他表示,大数据技术有着广泛的应用前景,对它的交叉研究既有趣也很有意义的事情。
大数据的学习让张鸿轩明确了自己真正的兴趣方向,也让他在团队合作的过程中感受到了自己专业能力的成长。“在课程组队参加的2018腾讯广告算法大赛和暑期实践中,我作为主干力量取得不错的成绩。在学习过程中,小组成员间的相互帮助、相互理解和相互包容也让我感受颇深。在大数据项目的课程学习和实践中,我能真切地感受到自己的不断成长,这段经历是我在大学阶段很宝贵的回忆。”
尝试是一个有趣的过程,但同时也势必面临着许多阻碍和困难,对此,张鸿轩认为,面对进入新领域的一些基本困难,只要愿意为其时间和精力,并且认真地坚持一段时间,就可能迎来一片新的天地。“虽然研究初期面临了各种阻碍,比如理论推导太过复杂、知识点记不住或者编程效率太低等,但只要愿意花时间,这些困难其实都是可以克服的,而且感受着自己的不断进步和成长也是很有自豪感的一件事!”
专业突破
“大数据让我抓到了风”
“我的主要研究方向是多能互补电力系统优化运行,也就是使用生成模型(generative model)对风光有功出力的多时空不确定性进行研究。通俗地讲,就是运用大数据模型更准确地抓到风。”涉及到自身专业的问题,张鸿轩兴致勃勃地向我们讲述了“如何运用大数据模型抓到风”。
“风电和光伏的有功出力会在很大程度上受到气候条件的影响,因此,风光出力不确定性的准确描述对于促进新能源消纳具有重要意义。但是,传统方法难以对考虑时空特性的大范围风电场和光伏电站有功出力的联合分布进行准确建模,我尝试使用生成模型(generative model)对风光有功出力的多时空不确定性进行了研究。目前最常用的生成模型包括了变分自编码器(VAE)和生成式对抗网络(GAN)两大类。在真实数据样本采集成本较高且难以大量获取的研究领域,GAN可以在少量数据样本中高效学习到各类特征,进而生成得到高质量的数据集;通过GAN网络也可以通过从历史数据中拟合得到的分布对当前数据进行修复,可以进一步提升采集系统的可靠性;GAN对于随机变量不确定性准确描述的能力更是使得其在大多数工科领域都有一定的应用潜力。”
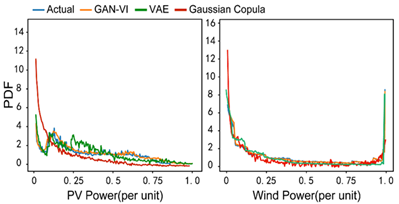
Fig. 1. 不同方法对风光有功出力概率密度函数的拟合情况
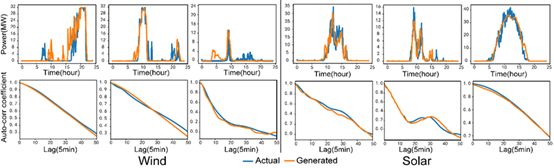
Fig. 2. 真实样本和基于改进GAN生成样本结果的对比
在没有利用大数据前,“传统方法难以对考虑时空特性的大范围风电场和光伏电站有功出力的联合分布进行准确建模”,数据拟合性不够,导致风电场的出电效率不高。但是,通过利用大数据和人工智能相结合的方式进行数据建模,张鸿轩在“风光有功出力”问题上做出了创新性的科研突破,他真正在数据的形式上“抓住了”风。他表示:“利用大数据方法对于风光有功出力的拟合能力明显优于传统方法,且能够通过生成高质量的场景来准确描述风光出力的时空不确定性,这会是未来比较热门的研究方向。”
目前,大数据技术正蓬勃发展,在众多工程领域有着广泛的应用前景,对交叉学科的研究也有着非常重要的技术性和创新性意义。而清华大学大数据能力提升项目,而已经迎来了第三批毕业生,对此,张鸿轩向正在参与和未来可能参与大数据提升项目同学们送上祝福和寄语:
非常感谢清华大学研究生院、数据科学研究院和大数据协会给我们提供了这么好的平台和这么多的学习机会,让众多对数据科学感兴趣的同学能够互相交流、互相学习、共同进步,也希望同学们都能在大数据交叉领域的学习和研究中找到自己的志趣所向,发现大数据的魅力,利用大数据技术在专业领域内做出自己的创新和突破。
”往期毕业生专访:
付睿:对新事物的追寻之旅 | 优秀毕业生专访
刘念宏:道与术,怎样才能真正学好大数据?
聂聪:数据科学让我为城市规划注入创新价值
姚振宇:数据科学培养下 我成为了那个不安分的"细菌"
张玉萍:数据科学的“融”是学术中的“锦上添花”
王斐:大数据学习助我完成行业撑杆跳
金语泽:大数据交叉思维让我更具创新力
王瑞琰:大数据引领我发现法学“新大陆”
龚亚丽:大数据助我打开传统行业发展新思路
张甜甜:在实践中迈进数据科学领域

这篇关于张鸿轩:大数据让无形之风尽在掌握 | 优秀毕业生专访的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






