本文主要是介绍机器学习中对抗性攻击的介绍和示例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

来源:DeepHub IMBA
本文约1000字,建议阅读5分钟
本文为你展示微小的变化如何导致灾难性的影响。概念
对抗样本是专门设计的输入,旨在欺骗机器学习 (ML) 模型,从而导致高置信度的错误分类。有趣的是这种方式对图像所做的修改虽然温和,但足以欺骗 ML 模型。在这篇文章中,我想展示微小的变化如何导致灾难性的影响。下图总结了对抗性攻击的过程:
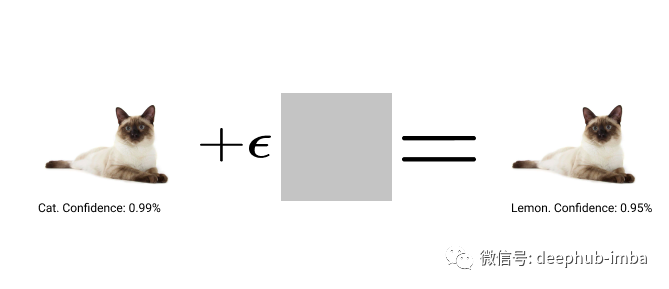
考虑上面的猫的图像,我们添加了一个小的扰动,经过计算使图像被高置信度地识别为柠檬。更具体地说,我们将获取图像并计算相对于所需标签的损失(在本例中为“柠檬”)。我们获得输入图像计算的梯度,并将其乘以一些小的常数 epsilon。经过多次这样的迭代,我们的模型被欺骗了,虽然肉眼看到是猫的图像,但是这这使得我们的 ML 模型可以高度自信地将它归类为柠檬。
这种方法非常健壮,而且简单易懂。这使得对抗样本可能非常危险。例如,攻击者可能让我的 AI 柠檬水制作机器人挤压我的猫并制作另一个柠檬水。😂
实际操作示例
例如,我将在Imagenet上接受ResNet50的预训练。列表中总共有1000个类,我使用Siamese Cat作为初始输入,我想要的标签是柠檬。

正如所见,模特正确地将我的形象归类为“暹罗猫”。由于图像的大小大于用于训练的图像,置信度很低。现在我们试着愚弄我们的模型,把它归类为柠檬。
def predict_on_image(input):model.eval()show(input)input = image2tensor(input)pred = model(input)pred = F.softmax(pred, dim=-1)[0]prob, clss = torch.max(pred, 0)clss = image_net_ids[clss.item()]print(f'PREDICTION: `{clss}` @ {prob.item()}')这是我做预测的辅助函数。输入的是我的猫的图像。它获取我的输入并打印出预测的类及其概率。
from tqdm import trangelosses = []def attack(image, model, target, epsilon=1e-6):input = image2tensor(image)input.requires_grad = Truepred = model(input)loss = nn.CrossEntropyLoss()(pred, target)loss.backward()losses.append(loss.mean().item())output = input - epsilon * input.grad.sign()print(input.grad.sign())output = tensor2image(output)del inputreturn output.detach()modified_images = []desired_targets = ['lemon']for target in desired_targets:target = torch.tensor([image_net_classes[target]])image_to_attack = original_image.clone()for _ in trange(10):image_to_attack = attack(image_to_attack, model, target)modified_images.append(image_to_attack)正如我已经描述过的,我如何攻击的过程被概括为“attack”方法。我运行这个函数10次,这足以使我们的ResNet50错误地将它分类为柠檬。注意我们只取梯度的sign,也就是1或-1,然后乘以,也就是1e-6。

我实现了我们的目标。这个模型现在把我们的猫归类为柠檬的概率非常高,但我们可以清楚地看到图像在视觉上仍然是一只猫。
最后总结
如你所见,对抗性攻击非常简单和有趣。通过这个例子,我们在使用公开发布的模型时一定要小心,这可能有潜在的危险并可能质疑人工智能的可靠性。因为这是最近的一个主要研究领域。强化学习代理也可以被对抗性的例子操纵。
如果你对对抗性攻击感兴趣,请查看OpenAI的这篇博客,有更详细的介绍:
https://openai.com/blog/adversarial-example-research/
编辑:于腾凯

这篇关于机器学习中对抗性攻击的介绍和示例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




