本文主要是介绍计算机组成原理【CO】Ch1 计算机系统概述,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
冯诺依曼机的特点
- 指令和数据以同等地位存储在存储器中,并按地址寻问
- 按存储单元的地址进行存取
- 指令和数据均以二进制代码表示
- CPU区分指令和数据的依据是指令周期的不同阶段。取值IF阶段是指令,译码ID阶段是数据
- 数据由指令的地址码给出
- 指令在存储器内按顺序存放。通常,指令是顺序执行的,在特定条件下可根据运算结果或根据设定的条件改变执行顺序
- 早期冯诺依曼机以运算器为中心,输入输出设备通过运算器与存储器传送数据
- 现代是以存储器为中心
- 是单处理机
- 基本工作方式是控制流驱动方式[存储程序思想]
- 控制流驱动:从程序存储器中拿到操作指令后,再去数据存储器中取操作数进行计算;[在程序执行前, 指令和数据需预先存放在存储器中, 中央处理器可以从存储器存取代码]
- 数据流驱动:只要数据已经准备好,有关的指令可并行执行。
【※】计算机性能指标
主频和CPU时钟周期
- 主频:机器内部主时钟的频率,代表每秒执行多少个时钟周期数
- 值越大代表一个操作所需时间越少,CPU运行速度越快
- CPU时钟周期:通常为节拍脉冲或T周期,即主频的倒数
- 是CPU中最小的时间单位,每个动作至少需要1个时钟周期
- 时钟周期=1/主频,如主频为2.4GHz,则时钟周期=1/2.4G 秒
CPI
- 执行一条指令所需要的时钟周期数
- CPI与系统结构,指令集,计算机组织有关,与时钟频率无关
- 时钟频率并不会影响CPI,但可加快指令的执行速度。
- 例如,执行一条指令需要10个时钟周期,则一台主频为1GHz的CPU,执行这条指令要比一台主频为100MHz的CPU快。
- CPI=时钟周期数量/指令数量
CPU执行时间
- 运行一个程序所花费的时间
- 执行时间= 时钟周期数量×时钟周期
Ch1 计算机系统概述
冯诺依曼机的特点
- 指令和数据以同等地位存储在存储器中,并按地址寻问
- 按存储单元的地址进行存取
- 指令和数据均以二进制代码表示
- CPU区分指令和数据的依据是指令周期的不同阶段。取值IF阶段是指令,译码ID阶段是数据
- 数据由指令的地址码给出
- 指令在存储器内按顺序存放。通常,指令是顺序执行的,在特定条件下可根据运算结果或根据设定的条件改变执行顺序
- 早期冯诺依曼机以运算器为中心,输入输出设备通过运算器与存储器传送数据
- 现代是以存储器为中心
- 是单处理机
- 基本工作方式是控制流驱动方式[存储程序思想]
- 控制流驱动:从程序存储器中拿到操作指令后,再去数据存储器中取操作数进行计算;[在程序执行前, 指令和数据需预先存放在存储器中, 中央处理器可以从存储器存取代码]
- 数据流驱动:只要数据已经准备好,有关的指令可并行执行。
【※】计算机性能指标
主频和CPU时钟周期
- 主频:机器内部主时钟的频率,代表每秒执行多少个时钟周期数
- 值越大代表一个操作所需时间越少,CPU运行速度越快
- CPU时钟周期:通常为节拍脉冲或T周期,即主频的倒数
- 是CPU中最小的时间单位,每个动作至少需要1个时钟周期
- 时钟周期=1/主频,如主频为2.4GHz,则时钟周期=1/2.4G 秒
CPI
- 执行一条指令所需要的时钟周期数
- CPI与系统结构,指令集,计算机组织有关,与时钟频率无关
- 时钟频率并不会影响CPI,但可加快指令的执行速度。
- 例如,执行一条指令需要10个时钟周期,则一台主频为1GHz的CPU,执行这条指令要比一台主频为100MHz的CPU快。
- CPI=时钟周期数量/指令数量
CPU执行时间
- 运行一个程序所花费的时间
- 执行时间= 时钟周期数量×时钟周期
MIPS
- MIPS:每秒执行多少百万条指令 [Million instructions per second]
- M I P S = 指令条数 / ( 执行时间 × 1 0 6 ) = 主频 / ( C P I × 1 0 6 ) MIPS=指令条数/(执行时间×10^6)=主频/(CPI×10^6) MIPS=指令条数/(执行时间×106)=主频/(CPI×106)
- MFLOPS:每秒执行多少百万次浮点运算
- M F L O P S = 浮点操作数次数 / ( 执行时间 ∗ 1 0 6 ) MFLOPS = 浮点操作数次数/(执行时间 * 10^6) MFLOPS=浮点操作数次数/(执行时间∗106)
- GFLOPS:每秒执行多少十亿次浮点运算
- G F L O P S = 浮点操作数次数 / ( 执行时间 ∗ 1 0 9 ) GFLOPS = 浮点操作数次数/(执行时间 * 10^9) GFLOPS=浮点操作数次数/(执行时间∗109)
- TFLOPS:每秒执行多少万亿次浮点运算
- T F L O P S = 浮点操作数次数 / ( 执行时间 ∗ 1 0 12 ) TFLOPS = 浮点操作数次数/(执行时间 * 10^{12}) TFLOPS=浮点操作数次数/(执行时间∗1012)
- P F L O P S = 浮点操作数次数 / ( 执行时间 ∗ 1 0 15 ) PFLOPS = 浮点操作数次数/(执行时间 * 10^{15}) PFLOPS=浮点操作数次数/(执行时间∗1015)
- E F L O P S = 浮点操作数次数 / ( 执行时间 ∗ 1 0 18 ) EFLOPS = 浮点操作数次数/(执行时间 * 10^{18}) EFLOPS=浮点操作数次数/(执行时间∗1018)
- Z F L O P S = 浮点操作数次数 / ( 执行时间 ∗ 1 0 21 ) ZFLOPS = 浮点操作数次数/(执行时间 * 10^{21}) ZFLOPS=浮点操作数次数/(执行时间∗1021)
- MGTPEZ
工作频率, 时钟频率之间的关系
假设总线传送一次数据是由N个时钟周期完成.
- 1 / 工作频率 1/工作频率 1/工作频率:表示每次完成数据传输所花费的时间
- 1 / 时钟频率 1/时钟频率 1/时钟频率:表示每次执行1个时钟周期所花费的时间
又因为每次完成传输数据都需要经过N个时钟周期来完成,根据时间关系所以有:
工作频率 = 时钟频率 / N 工作频率 = 时钟频率/N 工作频率=时钟频率/N
【※】各种字长的概念
指令字长
- 指令中包含二进制代码的位数,即一条指令的总长度
- 取决于:
- 操作码的位数(即多少操作)
- 操作数地址的长度(取决于主存的大小,如果容量为1GB的主存按字节寻址,每个操作数地址的长度都需要30位地址码)
- 操作数地址的个数(四、三、二、一、零地址等)。
- 为了硬件设计方便,指令字长一般取字节或存储字长的整数倍。
- 如果指令字长等于存储字长的2倍,那么需要2次访存,那么取指周期就等于机器周期的2倍。
机器字长
- CPU进行一次整数运算所能处理的二进制数据的位数
- 通常和ALU直接相关,由运算器内部寄存器决定【一般相等】。
- 反映了计算机的处理信息的能力
- 等于计算机的字长
- 是一个硬件概念
存储字长
- 是指一个存储单元存储的二进制代码(存储字)的长度。
- 通常和MDR位数相同。
- 一般情况下等于机器字长,也可以是机器字长的倍数
数据通路带宽
- 数据总线一次可以传递的位数,通常大于MDR位数
操作系统位数
- OS 可以寻址的位数,是软件概念
机器字长、指令字长和存储字长,三者在数值上可以相等也可以不等,视不同机器而定。
【※】各种周期概念
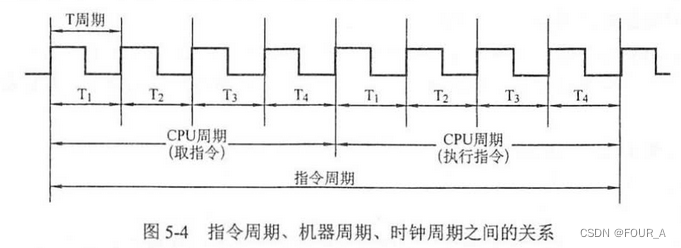
指令周期
- 从一条指令的启动到下一条指令启动所经历的时间。
- 通常由多个机器周期组成。
- CPU每取出并执行一条指令所需的全部时间,即CPU完成一条指令的时间,称为指令周期。
时钟周期(节拍周期)
- 计算机主频周期,通常将一个时钟周期定义为一个节拍。
- 时钟周期是计算机操作的最小单位时间,由计算机的主频决定,是主频的倒数。
- 工作脉冲是控制器的最小时间单位,起定时触发作用,一个时钟周期有一个工作脉冲。
机器周期(CPU周期)
- 在计算机中,为了便于管理,常把一条指令的执行过程划分为若干个阶段,每一个阶段完成一项工作,如取指令、存储器读、存储器写等,每一项工作称为一个基本操作。
- 完成一个基本操作所需的时间称为机器周期,也称为CPU工作周期或基本周期,通常等于取指时间(或访存时间)。
- 一般情况下,一个机器周期由若干个时钟周期构成。
总线周期
- CPU对存储器和I/O接口的访问通过总线实现。
- 把CPU通过总线对存储器或I/O接口进行一次访问所需时间称为一个总线周期。
- 总线的传输周期(总线周期):一次总线操作所需的时间(包括申请阶段、寻址阶段、传输阶段和结束阶段)通常由若干个总线时钟周期构成。
微指令周期
- 读出微指令的时间加上执行该条微指令的时间。
- 注意:微指令周期常取成和机器周期相等。
存取周期
- 存取周期指存储器进行连续两次独立的存储器操作(要么连续两次读操作,要么连续两次写操作)所需的最小间隔时间。
- 存取周期 = 存取时间 + 恢复时间
- 存取时间又称为存储器的访问时间,指启动一次存储器操作(读或写)到完成该操作所需的全部时间。
- 存取时间分为读出时间和写入时间两种。
CPU访存的过程
- CPU通过总线把数据地址送给存储器。
- 存储器得到地址后启动存储器即准备数据。
- CPU输出控制信号或其他操作。
- 数据准备完毕【此过程完成数据准备即一个存储周期】,再由总线送回CPU。
存储周期与总线周期
- 一个存储周期是对存储器的两次存取操作的时间间隔,在这个时间间隔里面可以包含多个总线传输周期,因为一次存取操作不一定读取一个数据总线宽度的数据,所以一个存取周期可以包含多个总线传输周期。
- 所以,通常存储周期 > 总线周期,CPU不能连续存取数据,必须等待。
- 为提高传输效率,由此也引出了两个概念:
- 总线突发传输方式:即总线可以在一个总线周期内传输一个地址和一批地址连续的数据,代替常规传输的一个地址一个数据。
- 多体并行存储器:存储器采用多个存储模块组成,以流水线方式准备数据,从而提高存储带宽。
【※】各种线的条数的确定
- 地址总线线数 —> 可寻址的范围 —> 存储器最大容量【存储单元的个数】—>一般和MAR的位数一样
- 数据总线线数 —> 一次可取的数据位数 —> MDR的位数 —> 运算器一次处理的位数 —>运算器寄存器位数—>通常与存储字长相等 —>n位CPU的n
- 控制总线线数 —> 一次可并行传送的控制信息位数
- IO线数 —> 与外设通信的并行程度
【※】从源文件到可执行文件
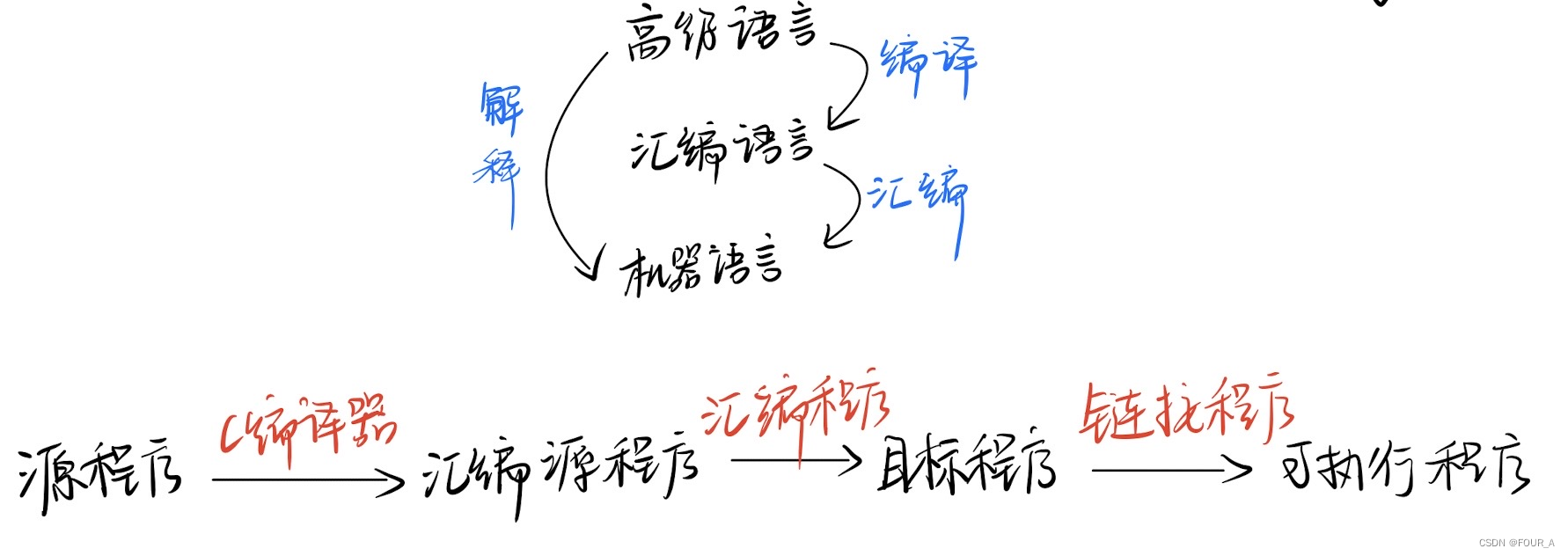
三种程序转换图
-
三个语言:
- 机器语言:是计算机唯一可以直接识别和执行的语言
- 汇编语言:由汇编程序(系统软件)汇编成为机器语言后,才能执行
- 高级语言:
- 如C,C++,Java
- 一种是经过编译程序,编译得到汇编语言,然后经过汇编操作,得到机器语言,然后再执行【高级语言->汇编语言->机器语言】
- 一种是由高级语言程序直接翻译成机器语言(边翻译边执行,不生成可执行文件)【高级语言->机器语言】
-
三种程序:
- 汇编程序(汇编器) :将汇编语言程序翻译为机器语言程序。
- 编译程序(编译器) :将高级语言源程序一次翻译成目标程序(汇编语言或机器语言)
- 解释程序(解释器) :将源程序的一条语句翻译成对应的机器目标代码并立即执行,并不形成目标程序。
-
预处理阶段:预处理器(cpp) 根据以字符#开头的命令,修改原始的C程序,得到另一个C程序,通常以i作为文件扩展名。
-
编译阶段:编译器(ccl) 将文本文件hello.i翻译成文本文件hello.s,它包含一个汇编语言程序。
-
汇编阶段:汇编器(as)将hello.s翻译成机器语言指令,把这些指令打包成一种叫做可重定位目标程序的格式,并将结果保存在目标文件hello.o中。
-
链接阶段:hello程序调用了printf函数,printf函数存在于一个名为prntf.o的单独的一个预编译好了的目标文件中,而这个文件必须以某种方式合并到我们的hello.o程序中。链接器(ld) 就负责处理这种合并。结果得到hello文件,它是一个可执行目标文件,可以被加载到内存中,由系统执行。
应用软件和系统软件
应用软件
- 办公软件
- 多媒体软件
- 辅助设计软件
- 企业应用软件
- 网络应用软件
- 安全防范软件
- 科学计算类软件
- 工程设计类程序
- 数据统计与处理程序
- 娱乐休闲软件
- 数据库系统
系统软件
- 操作系统
- 网络服务程序【连接程序】
- 语言处理程序【编译程序】
- 数据库管理系统
- 软件系统
- 分布式系统
- 程序设计语言
- 其他实用程序和工具
这篇关于计算机组成原理【CO】Ch1 计算机系统概述的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






