本文主要是介绍闲聊数据结构之list,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
听说要下雪了,在这寒冷的冬季。。。风太大,我听不见。。。
依稀记得有一次有人问,在你写一些代码的时候,你会选用什么数据结构呢?有什么选择的标准呢。。。当时也就当为了笑谈,好像并无什么特别的喜好,也没什么特别的感觉。。。
为什么不喜欢的东西丢了,还会念念不忘呢?
数据结构,好像很高深一样,但是从未真正研究,但是真正看起来,耗费的时间和心血不是一点点。。。
原来看书,思维枯竭,现在看书。。。嗬,思维洪流,看一句话能无限的涌入各种相关的信息。。。内存溢出了解一下。。。
数据结构总是与算法息息相关,总体看来,数据结构只是保存数据的一种方式,而算法则是实现数据结构的各种操作,数据结构是静态的,是内存的一种表现形式,而算法则有很多种,一种程序的实现可以有各种方式。。。
程序?进程?数据结构?又有什么关系。。。
程序是各种逻辑控制加各种数据结构组成的,看看每天写的程序,除了if 就是else,除了for就是while,除了break就是continue。。。千奇百怪的控制流,而其中流淌的则是各种算法,这种才是生命,才是灵魂。。。
运行一个进程,其实就是一个程序的实例,那么运行同一个程序两次呢?依旧会运行两个进程,进程只是CPU的一种抽象,从而形成多道程序设计的假象,当然,多核的CPU可能不在此列。。。
为什么有了for循环,还需要while循环?
在python中,for循环可以用在很多地方,例如序列是根据下标来访问的,字典是根据键来访问的,也可以根据值来进行迭代,在for循环中,使用的各种可迭代的对象,只是一种值得迭代方式而已。。。而while循环则不同,必须有个判断条件,也就是结果为True或者False,while循环可以实现无限循环,而for不行,while循环还能实现计数循环,然后break跳出循环,这种for也是可以实现的。。。
我们每天可能接触各种各样的不同的数据结构,只是我们不知道而已,例如number,float,list,tuple,dict,set,frozenset,其实数据结构可以脱离语言而存在,而对于高级语言来说,提供了很多高级的数据结构,从而让编程更加容易,这也就是为什么java越来越流行,而c,c++等各种入门的门槛比较高了。。。
数据结构只是一种内存的表现形式,例如线性表,也就是python中的list,tuple,java中的ArrayList,用连续的内存来存放相关的数据,而这种方式的存储,是其最大的优势,也是最大的缺陷。
list,tuple采用连续的内存来保存一块数据,从而如果内存还剩下100M,我现在要申请100M的内存,而内存中并不一定是连续的,从而导致内存不足的报错。
采用连续的内存来保存一块数据,从而在访问数组元素的时候,总是能根据index进行随机访问,随机?random access,那么什么是顺序访问。。。所谓的随机就是得到了一个index,然后能找到这个对象存放的地址,然后访问其值,而对于顺序访问来说,必须先找到第一个,然后找第二个。。。随机访问在数组的访问的时间复杂度为O(1),也就是常量的访问时间。。。
采用连续的内存来保存一块数据,并且是有顺序的存放的,从而会导致在删除数据,插入数据的时候,需要将数据进行搬迁,也就是按位后移。。。从而导致了复杂度在O(n),最坏时间复杂度和平均时间复杂度。。。

删除的时候,也是一样的,要将所有的数据前移,从而时间复杂度也是O(n)。。
从而在选择list的时候,必须是要查询比较多的情况,而对于增加,删除是比较少的情况。。。
但是这种情况也是可以改善的,对于list来说,如果每次都插入的时候是在最后一个元素,也就是append的时候,这种情况就无需移动数据,从而时间复杂度在O(1),而对于删除来说,每次是最后的元素,也是O(1)。。
还有一种情况就是,如果对于序列来说,是不需要保证顺序的,那么在插入数据的时候,可以直接将数据的位置进行更换,从而达到复杂度为O(1)。。

线性表使用连续的内存。。。而在linux系统中,进程看到的内存根本就是假的。。。
linux中,使用的内存,是进程所拥有的单独的虚拟地址空间,独占的式的存在,并不知道其他进程有多少内存,虚拟内存通过映射到实际的物理内存,可能是连续的?也可能不是连续的。。。
所谓的连续,到底连续还是不连续。。。Emmm,很难搞清楚。。。
在使用list的时候,list和tuple其实两者的结构是差不多的,但是两者的区别在于,一个是可变的list,一个不可变的tuple,从而list提供了增删改查的操作,而对于tuple,则仅仅提供了查的操作。。如果进行了其他的操作,那么就是创建了一个新的tuple对象而已。。。
使用一个数据结构,其实也就是使用它的各种方法来进行操作。。。而对象,也只是一个数据结构而已,使用的也是各种操作,从而达成自己的想要实现的目的。。。

看看list的操作方法,append,count,时间复杂度O(1),而对于extend,index,insert,pop,remove,reverse时间复杂度基本都在O(n),sort为O(nlogn)。。。数据结构只是内存的一种表现形式,而这种表现形式则提供了各种操作,这些操作中又反应了各种算法。。。
选用什么数据结构来存储,list适合于有顺序存储的一类数据,用的很多了。。。
list,占用的是连续的内存,从而在生成list的时候,如果一下创建一个很大的列表,那么会有速度上延迟,从而一种改进的方法是使用xrange,生成器,每次只创建一个,从而大大的节省了内存。。。
其实对于基本的数据类型来说,一种类型就规定了一种操作的方法,看看各种list类型,dict类型,操作均是不相同的,从而使用的方法也是不一致的,只有说,在合适的场景使用合适的数据结构。
对于list来说,如果存储各种数据类型的话,那么又能有两种方式(二维数组)。。。

而一种则是如下:
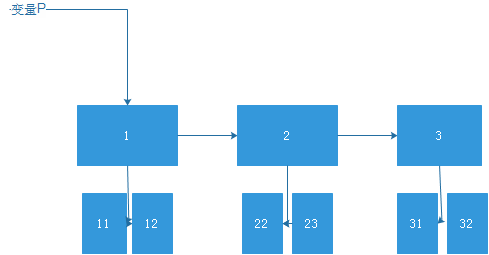
第一种是一体式的存储结构,也就是全部在连续的内存之中,而第二种则是分离的存储结构,在每个元素里面存储一个引用,指向另外一块连续的内存,来存储数据,这个时候,可以保持变量的id不变,而内部的元素发生变化,例如tuple t = (1,【123】),在不变对象中可以使用可变的对象。。。
使用不同的方法,得到相同的目的。。。顺序表也就是数组,其实就是达到随机访问的时间复杂度为O(1)。
为啥我上班总感觉我没脑子呢。。。放在家里了?Emmm。。。没有过,也没见过。。。哈哈
为什么不想要的失去之后,还会念念不忘呢?是因为没找到更好的替代?还是因为不是真不想要,而是想要的不够多?贪欲?
最好的也是最差的,其实都是还是带着镣铐跳舞,在各种限制之下做的更好。。。明明知道有很多限制,如果你将所有的关注力都放在限制之中,那么可能就陷入了死循环,永远想改变不可能改变的事。。。更多的应该关注在如何做成,如何能达到自己想要的目标。。。
连续不连续。。。放在连续的内存中,不灵活,就像你写代码的时候,你需要大片的时间来思考,而有一件事打断你,就中断去处理一下,然后。。。这个内存又再次申请,又再次迁移数据,再次释放空间。。。耗费资源。。。像不像CPU切换,但是CPU切换无所谓啊,进程反正要等待IO,切换就切换咯。。。
那么不连续?用链表的方式?。。。嗯,比较灵活,所以就有了碎片的时间,可能干各种事儿,但是不好的地方在于,容易生成内存空洞。。。fire in the hole。。。
这篇关于闲聊数据结构之list的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




