本文主要是介绍Python零基础从小白打怪升级中~~~~~~~SQLAlchemy的介绍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
第四节:SQLAlchemy操作数据库
一、SQLAlchemy介绍
SQLAlchemy 是 Python 中一个通过 ORM 操作数据库的框架。
SQLAlchemy对象关系映射器提供了一种方法,用于将用户定义的Python类与数据库表相关联,并将这些类(对象)的实例与其对应表中的行相关联。它包括一个透明地同步对象及其相关行之间状态的所有变化的系统,称为工作单元,以及根据用户定义的类及其定义的彼此之间的关系表达数据库查询的系统。
可以让我们使用类和对象的方式操作数据库,从而从繁琐的 sql 语句中解脱出来。
ORM 就是 Object Relational Mapper 的简写,就是关系对象映射器的意思。
pip install sqlalchemy
from sqlalchemy import create_engine# 数据库的配置变量
HOSTNAME = '127.0.0.1'
PORT = '3306'
DATABASE = 'test'
USERNAME = 'root'
PASSWORD = '123123'
DB_URI = 'mysql+mysqldb://{}:{}@{}?charset=utf8mb4:{}/{}'.format(USERNAME,PASSWORD,HOSTNAME,PORT,DATABASE)# pymysql
engine = create_engine("mysql://user:password@localhost:3306/dbname",echo=True, # echo 设为 True 会打印出实际执行的 sql,调试的时候更方便future=True, # 使用 SQLAlchemy 2.0 API,向后兼容pool_size=5, # 连接池的大小默认为 5 个,设置为 0 时表示连接无限制pool_recycle=3600, # 设置时间以限制数据库自动断开
)# 创建一个 SQLite 的内存数据库,必须加上 check_same_thread=False,否则无法在多线程中使用
engine = create_engine("sqlite:///:memory:", echo=True, future=True,connect_args={"check_same_thread": False})# pip install mysqlclient
engine = create_engine('mysql+mysqldb://user:password@localhost/foo?charset=utf8mb4')
二、创建ORM映射
创建一个类,一个类对应了一个数据库中的一张表,类的数据属性对应了表中的字段名,这个类称为映射类。根据映射类创建出一个一个的对象,每个对象对应了表中的一条实际的数据。

#1、创建基类
from sqlalchemy.ext.declarative import declarative_baseengine = create_engine(DB_URI)Base = declarative_base(engine)#2、用这个`Base`类作为基类来写自己的ORM类。要定义`__tablename__`类属性,来指定这个模型映射到数据库中的表名。
class Person(Base):__tablename__ ='person'#3. 创建属性来映射到表中的字段,所有需要映射到表中的属性都应该为Column类型:
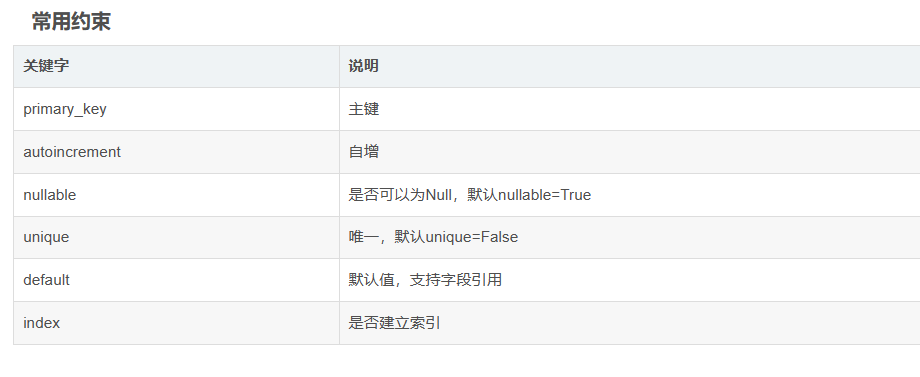
class Person(Base):__tablename__ ='t_person'#2.在这个ORM模型中创建一些属性,来跟表中的字段进行 一一 映射。这些属性必须是sqlalchemy给我们提供好的数据类型id = Column(Integer,primary_key=True,autoincrement=True)name = Column(String(50))age = Column(Integer)country = Column(String(50))# 调用 create_all 创建所有模型Base.metadata.create_all(engine)# 如果只需要创建一个模型User.__table__.create(engine)
#定义一个枚举类
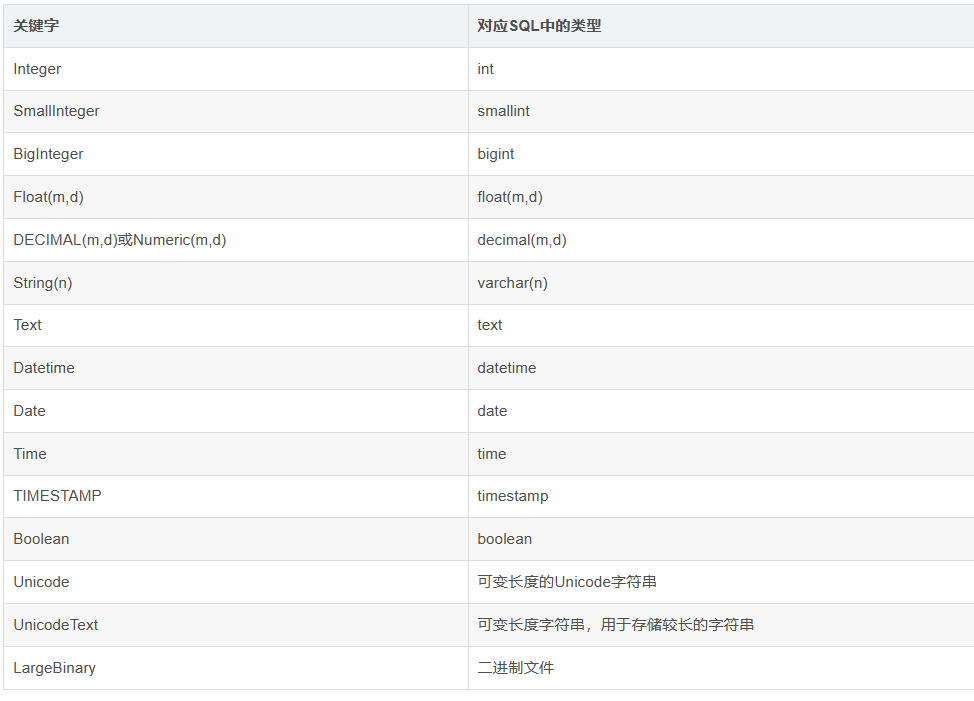
class TagEnum(enum.Enum):python="PYHTON"flask="FLASK"django ="DJANGO"#创建一个ORM模型 说明基于sqlalchemy 映射到mysql数据库的常用字段类型有哪些?
Base = declarative_base(engine)
class News(Base):__tablename__='news'id = Column(Integer,primary_key=True,autoincrement=True)price1 = Column(Float) #存储数据时存在精度丢失问题price2 = Column(DECIMAL(10,4))title = Column(String(50))is_delete =Column(Boolean)tag1 =Column(Enum('PYTHON','FLASK','DJANGO')) #枚举常规写法tag2 =Column(Enum(TagEnum)) #枚举另一种写法create_time1=Column(Date)create_time2=Column(DateTime)create_time3=Column(Time)content1 =Column(Text)content2 =Column(LONGTEXT)# Base.metadata.drop_all()
# Base.metadata.create_all()三、增删改查操作
1、建立session链接
from sqlalchemy.orm import sessionmakerDBSession = sessionmaker(bind=engine,autocommit=False, autoflush=False,future=True)with DBSession() as sess:sess.execute()with DBSession.begin() as sess:sess.execute()2、新增操作
和 1.x API 不同,2.0 API 中不再使用 query,而是使用 select 来查询数据。
<!--方式一SQL-->
insert_stmt = insert(User).values(name='name1')
with DBSession() as sess:sess.execute(insert_stmt)sess.commit()<!--未绑定参数-->
insert_stmt2 = insert(User)
with DBSession() as sess:sess.execute(insert_stmt2,{'name':'name1'})sess.commit()<!--批量-->
with DBSession() as sess:sess.execute(insert_stmt2,[{'name':'name1'},{'name':'name2'}])sess.commit()<!--另一种方式begin-->
with DBSession.begin() as sess:sess.execute(insert_stmt2,[{'name':'name1'},{'name':'name2'}])<!--方式二对象-->
obj=User(name='name2')
with DBSession() as sess:sess.add(obj)sess.commit()<!--批量-->
obj=User(name='name2')
obj2=User(name='name2')
with DBSession() as sess:sess.add(obj)sess.add(obj2)# 或者 s.bulk_save_objects([obj,obj2])sess.commit()
3、查、改和删除操作
2.0 API 中不再使用 query,而是使用 select,update,delete 来操作数据。但query仍可使用
# session.query(User).get(42)
session.get(User, 42)# session.query(User).all()
session.execute(select(User)).scalars().fetchall()# session.query(User).filter_by(name="some_user").first()
session.execute(select(User).filter_by(name="some_user")).fetchone()# session.query(User).from_statememt(text("select * from users")).a..()
session.execute(select(User).from_statement(text("selct * from users"))).scalars().all()# session.query(User).filter(User.name == "foo").update({"fullname": "FooBar"}, synchronize_session="evaluate")
session.execute(update(User).where(User.name == "foo").values(fullname="FooBar").execute_options(synchronize_session="evaluate"))
# synchronize_session 有三种选项: false, "fetch", "evaluate",默认是 evaluate
# false 表示完全不更新 Python 中的对象
# fetch 表示重新从数据库中加载一份对象
# evaluate 表示在更新数据库的同时,也尽量在 Python 中的对象上使用同样的操作这篇关于Python零基础从小白打怪升级中~~~~~~~SQLAlchemy的介绍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




