本文主要是介绍详解GPT-1到GPT-3的论文亮点以及实验结论,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1. 前言
- 2. GPT-1
- 2.1 亮点
- 2.2 实验结论
- 3. GPT-2
- 3.1 亮点
- 3.2 实验结论
- 4. GPT-3
- 4.1 亮点
- 4.2 实验结论
- 5. 总结
- 6. 参考
1. 前言
Generative Pre-trained Transformer 即 GPT。这篇文章结合论文总结一些 GPT-1 到 GPT-4 的架构和性能上的差异。GPT 系列是由 OpenAI 开发的自然语言处理模型,GPT-1 到 GPT-4 的区别如下:
GPT-1: GPT-1 是 OpenAI 于2018年发布的第一个生成式预训练模型。它采用了基于 Transformer 架构,并使用了大量的预训练文本数据进行训练,但参数量相对较小,约为1.1亿。GPT-1 具有处理简单语言任务的能力,但在某些复杂语境下可能表现不佳。
GPT-2: GPT-2 是 GPT-1 的升级版本,于2019年发布。与GPT-1 相比,GPT-2 具有更大的模型规模和更多的参数,参数量到了15亿,使其能够生成更加流畅和准确的文本。GPT-2 在语言理解和生成任务中表现更为出色,并且在保持文本连贯性的同时减少了生成不合理的内容的概率。
GPT-3: GPT-3 是于2020年发布的,具有1750亿个参数,是当时最大的预训练语言模型之一。GPT-3 在语言生成、文本分类、问题回答等多个自然语言处理任务上表现出色,具有更强的泛化能力。
GPT-4: GPT-4 于2023年推出。该模型的训练数据和架构的细节没有正式公布。GPT-4 的一个突出特点是它的多模式功能。
| 模型 | 发布时间 | 参数大小 | Max Sequence Length |
|---|---|---|---|
| GPT-1 | 2018年6月 | 1.17亿 | 1024 |
| GPT-2 | 2019年2月 | 15亿 | 2048 |
| GPT-3 | 2020年6月 | 1750亿 | 1024 |
| GPT-4 | 2023年3月 | 未知 | 未知 |
如果希望对大语言模型整体有一个全局的认识,请查看:
《NLP深入学习:《A Survey of Large Language Models》详细学习(一)》
《NLP深入学习:《A Survey of Large Language Models》详细学习(二)》
《NLP深入学习:《A Survey of Large Language Models》详细学习(三)》
《NLP深入学习:《A Survey of Large Language Models》详细学习(四)》
《NLP深入学习:《A Survey of Large Language Models》详细学习(五)》
《NLP深入学习:《A Survey of Large Language Models》详细学习(六)》
《NLP深入学习:《A Survey of Large Language Models》详细学习(七)》
下面章节就各个 GPT 进行讲解。
2. GPT-1
2.1 亮点
原文《Improving Language Understanding
by Generative Pre-Training》
GPT-1 在2018年6月发布,亮点:
(1) Transformer Decoder 架构替代了 LSTM/RNN
(2) 预训练(Pre-training) + 微调(Fine-tuning) 的半监督(Semi-supervised)策略
(3)任务无关的模型架构。论文中使用的模型不依赖于为每个特定任务设计的特定架构,而是通过微调一个统一的架构来适应不同的任务,这简化了模型的开发和部署。
其中 Transformer 的详细讲解请参考:
《NLP深入学习:大模型背后的Transformer模型究竟是什么?(一)》
《NLP深入学习:大模型背后的Transformer模型究竟是什么?(二)》
「预训练 + 微调」是大语言模型训练的一种通用方法,这种方法在我看来就是解耦与统一。预训练是无监督训练,输入是大量的纯文本信息,根据语言模型训练得到一种通用模型;微调是监督训练,输入是有标注的文本内容,在预训练的模型结果下进行调整。这种方法可以将传统的多种 NLP 任务统一起来。
传统的 NLP 任务,如分类、翻译、语义识别等,需要各自建立模型。而对于「预训练 + 微调」而言,预训练得到的是通用模型,这一部分与具体的 NLP 任务解耦,而微调则实现了下游任务的特定化,两者叠加则实现了解耦与统一的目的!
GPT-1 的整体架构:

左边是 Transformer 的 Decoder 层,用于预训练;右边是不同的任务采用不用的微调策略。在研究的12项任务中,模型在9项上取得了新的最佳性能,这包括常识推理、问题回答和文本蕴含等任务。
2.2 实验结论
预训练:采用 BooksCorpus 数据集
微调:根据以下任务分别进行了测试
(1) 自然语言推理:自然语言推理(NLI)任务涉及判断一对句子之间的关系,例如蕴含、矛盾或中立。在多个 NLI 数据集上进行了评估,包括 SNLI、MultiNLI、QNLI、RTE 和 SciTail 等。实验结果显示,GPT-1 在多数数据集上超越了之前的最好结果,展示了在处理多句推理和语言歧义方面的能力。
(2) 问题回答和常识推理:在 RACE 数据集和 Story Cloze Test 上评估了问题回答和常识推理任务。GPT-1 模型在这些任务上也取得了显著的性能提升,证明了处理长期上下文的能力。
(3) 语义相似度:语义相似度任务要求预测两个句子是否在语义上等价。在三个数据集上进行了评估:Microsoft Paraphrase Corpus、Quora Question Pairs(QQP) 和 Semantic Textual Similarity Benchmark(STS-B)。GPT-1 在 STS-B 上取得了最佳结果,并在 QQP 数据集上取得了显著的改进。
(4)文本分类:文本分类任务评估了模型在判断句子是否符合语法(CoLA)和情感分析(SST-2)方面的能力。GPT-1 模型在 CoLA 数据集上取得了显著的性能提升,并在 SST-2 上达到了与最先进结果相竞争的准确率。
(5)GLUE基准测试:在 GLUE 多任务基准测试上评估了他们的方法,这是一个新近引入的多任务基准,用于评估模型在一系列自然语言理解任务上的性能。GPT-1 模型在 GLUE 基准测试上取得了72.8的总分,比之前的最好结果有显著提升。
结论:GPT-1 提出的半监督学习方法在多个自然语言理解任务上的广泛适用性和显著性能提升,验证了其作为一种有效的迁移学习策略的潜力。
3. GPT-2
3.1 亮点
原文《Language Models are Unsupervised Multitask Learners》
GPT-2 在 2019年2月发布,拥有15亿参数的 Transformer 模型。本文的亮点:
(1)无监督多任务学习(Multitask Learning)能力。没有显式监督的情况下,语言模型能够间接地学习执行多种 NLP 任务,而不需要针对每个任务进行显式监督学习。与传统的监督学习方法相比,大大拓宽了模型的应用范围。
(2)大规模数据集 WebText。创建了一个新的大规模数据集WebText,它包含了来自 Reddit 的4500万个链接的文本子集。这个数据集的多样性和规模对于训练能够处理多种任务的语言模型至关重要。
(3)GPT-2模型。GPT-2是一个具有1.5亿参数的Transformer 模型,它在多个 NLP 任务上取得了最先进的结果,特别是在零样本学习设置中。这种规模的模型能够生成连贯的文本段落,并在没有额外训练数据的情况下达到竞争性能。
以往的语言模型通常在特定任务的数据集上采用有监督学习来解决如问题回答、机器翻译、阅读理解及摘要生成等任务。这些模型在被训练的任务上表现出色,但对于数据分布或任务规格的微小变化却非常敏感,这限制了它们的泛化能力。
3.2 实验结论
GPT-2 在以下多个任务下,逐步增加参数规模进行测试(简称,大力出奇迹):
(1)语言建模(Language Modeling):首先评估语言建模上的表现。他们使用了不同的评估指标,如困惑度(perplexity),并在多个数据集上进行了测试,包括 WikiText-2、Penn Treebank 等。结果显示,随着参数规模的增加,实验结果大部分情况下会有所提升

(2) 儿童图书测试(Children’s Book Test):这个测试旨在评估对不同类别词汇(如命名实体、名词、动词和介词)的建模能力。GPT-2 在这个测试上随着参数的增加,识别准确率越接近人类水平,尤其是在命名实体和普通名词的识别上。

(3) LAMBADA数据集:LAMBADA 测试旨在评估系统对文本中长距离依赖关系的建模能力。GPT-2 在这个任务上的性能显著提高,降低了困惑度并提高了准确率。
(4) Winograd Schema Challenge:这个挑战旨在评估系统进行常识推理的能力。GPT-2 在这个任务上也取得了显著的性能提升。
(5) 阅读理解(Reading Comprehension):测试了 GPT-2 在 Conversation Question Answering(CoQA)数据集上的性能。该数据集包含来自不同领域的文档和关于这些文档的自然语言对话。GPT-2 在没有使用手动收集的问题答案对的情况下,达到了与多个基线系统相当的性能。
(6) 摘要生成(Summarization):在 CNN 和 Daily Mail 数据集上,GPT-2 展示了生成摘要的能力,尽管生成的摘要在某些细节上可能不准确,但在 ROUGE 指标上的表现接近经典的神经网络基线。
(7)翻译(Translation):GPT-2 在 WMT-14 英法和法英测试集上展示了一定的翻译能力,尽管其性能仍然落后于当前最好的无监督机器翻译方法。
(8) 问题回答(Question Answering):在 Natural Questions 数据集上,GPT-2 能够回答一些事实性问题,但其性能仍然远低于当前的开放域问答系统。
结论:GPT-2 在 Zero-shot 下,在多个 NLP 任务都有良好的表现。这些实验结果证明了 GPT-2 提出的方法是有效的,为未来的研究提供了有价值的见解。
4. GPT-3
4.1 亮点
原文《Language Models are Few-Shot Learners》
GPT-3 是于2020年发布的,采用和 GPT-2 一样的模型架构,具有1750亿个参数,亮点如下:
(1)Zero-Shot/One-Shot/Few-Shot 对比:论文评估对比 GPT-3 模型在Zero-Shot (零示例学习),One-Shot (单示例学习),以及 Few-Shot (少量示例学习)的差异。Zero-Shot 挑战模型的泛化能力,One-Shot 测试模型的快速学习和推广能力,而Few-Shot 则展示了模型在实际应用中可能遇到的有限数据情况下的性能。
(2)参数规模验证:论文展示了前所未有的1750亿参数的 GPT-3 模型,这是当时最大规模的非稀疏语言模型,比之前所有模型的参数量都大10倍以上。研究证实,随着模型规模的扩大,GPT-3 在少量样本学习能力甚至能够与专门针对任务微调的先前最优系统相媲美。
4.2 实验结论
论文在实验中详细介绍了 GPT-3 的 Zero-Shot、One-Shot、Few-Shot 在不同的模型参数规模下,在多种自然语言处理(NLP)任务上的表现。这些任务被分为不同的类别,以测试模型在语言建模、问答、翻译、常识推理、阅读理解等多个领域的表现。
(1)语言建模、完形填空和完成任务:GPT-3 在传统的语言建模任务上的结果:

Few-Shot 的效果最好,而 Zero-Shot 在某些数据集下的效果下逼近当前最好的微调模型。

随着模型参数规模提升,评测的准确率也提升;在大规模参数的模型下,Few-Shot 效果最好,即大规模的模型更容易发现内部的规律,泛化效果更佳。
(2) 闭卷问答:在不需要额外信息,仅依赖模型内部知识来回答问题的闭卷问答任务中,GPT-3 展示了强大的能力,尤其是在 TriviaQA 和 WebQuestions 数据集上。

随着模型参数规模提升,评测的准确率也提升。
(3)翻译:GPT-3 在多种语言对的翻译任务上表现出色,即使是在 Zero-Shot 和 One-Shot 学习设置下,也能达到与先前未监督神经机器翻译(NMT)工作相当的性能。


随着模型参数规模提升,评测的准确率也提升
(4)Winograd-style 任务:在 Winograd Schemas 和Winogrande 数据集上,GPT-3 在确定代词指代方面取得了进步,尤其是在 Zero-Shot 和 Few-Shot设置下。


随着模型参数规模提升,评测的准确率也提升。
(5)常识推理:在常识推理任务(如PIQA)上,GPT-3 在 一些数据集上,如 ARC和 OpenBookQA,表现仍然有待提高。

(6)阅读理解:GPT-3 在一系列阅读理解任务上,包括CoQA、DROP、SQuAD 2.0等,展现了与人类水平相近的性能,尤其是在对话式阅读理解任务上。
(7)SuperGLUE基准:在 SuperGLUE 基准测试中,GPT-3在多项任务上都取得了良好的成绩,显示出在语言理解方面的全面能力。

(8)自然语言推理(NLI):在自然语言推理任务上,如 ANLI,GPT-3 仍有提升空间。但随着参数提升,到175B后,增加 Few-Shot,评测准确率提升明显。
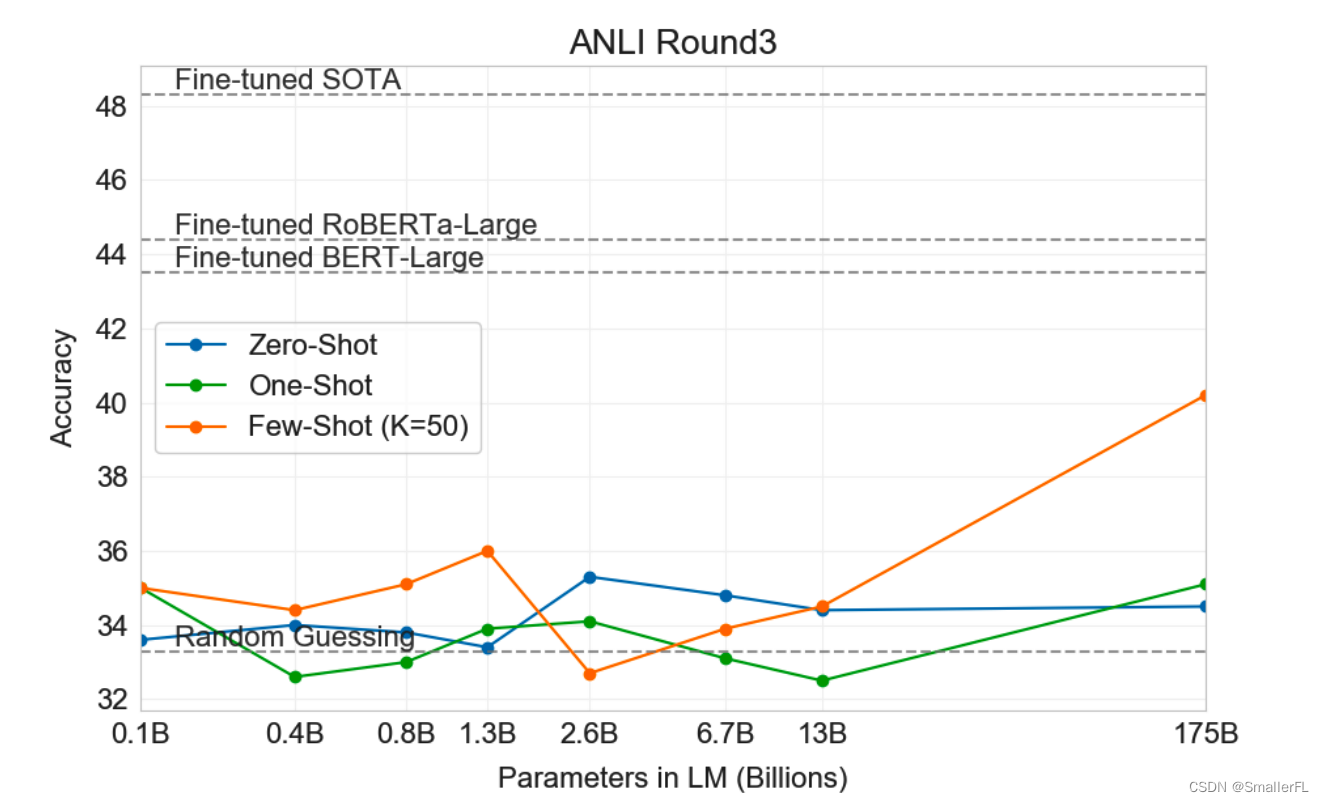
(9)合成和定性任务:作者设计了一系列合成任务来测试 GPT-3 的能力,包括执行算术运算、解决字谜、使用新词汇和生成新闻文章等。GPT-3 在这些任务上的表现证明了它在理解和生成类人文本方面的强大能力。
结论:GPT-3 验证了参数规模越大,模型效果越好;Zero-Shot 的情况下,模型测试越好说明模型泛化能力越好;一般情况下,模型测试效果:Few-Shot > One-Shot > Zero-Shot。
5. 总结
- GPT1:采用 Transformer 模型,Pre-Training + Fine-Tuning
- GPT2:参数提升到15亿,并且没有用微调(即,Zero-Shot),测试模型的多任务学习能力
- GPT3:参数进一步提升到1750,测试了 Zero-Shot、One-Shot、Few-Shot 的在各个数据集的测试结果
总而言之,GPT1-3 论文说明了“大力出奇迹”,模型的泛化能力随着参数规模增加而逐渐提升!
6. 参考
《Improving Language Understanding
by Generative Pre-Training》
《Language Models are Unsupervised Multitask Learners》
《Language Models are Few-Shot Learners》
欢迎关注本人,我是喜欢搞事的程序猿; 一起进步,一起学习;
欢迎关注知乎:SmallerFL;
也欢迎关注我的wx公众号:一个比特定乾坤
这篇关于详解GPT-1到GPT-3的论文亮点以及实验结论的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






