本文主要是介绍从图割到图像分割 - 多层图图割,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
从图割到图像分割(三)——多层图图割
完整的了解了图割方法处理图像分割之后,在已有的graphcuts开源代码的情况下,接下来就是自己创作的时间了。
如前面所说,图的构建是很有讲究的,何时采用四邻域,何时采用八邻域,何时采用K近邻,再何时采用全邻域?
这些都是很有讲究的,很多人就是在这上面稍加改动,就能发一些顶级文章。不过确实,通过 Maxflow/Mincut 处理图像时,对图的构造是非常敏感的,哪怕是你改动 Tlink 与 Nlink 的比例,都能产生很大的影响。但敏感归敏感, Maxflow/Mincut 求取的全局最优解,恰是许多研究或能量优化函数中所梦寐以求的。

图论方法在交互式分割中,总是将图像分割成前景和背景两类,即用户选定前景,或用户选定前景/背景,或用户选定背景。然而,很明显,在自然图像中,很多情况下并非只有两类,需要选定多类才能达到较好的分割效果。
由两类扩展成多类,是我导师提出来的想法,并完善,通过多层图方法完成图像中多类的交互式分割。
其中,多类分割的实现方法,也是在最初Graphcuts源码上进行改进,具体可见我的github,MulitLayerGraph。这份代码的主要思想是源自我导师,主要工作是我素未谋面的师兄常峰写的,师兄写的代码比较乱,有些小bug,并且不是用模板来实现的,鉴于我在研究此类问题,并且算是对这类问题非常熟悉了,所以将代码全部重构一下,用模板写了并放在github上面。
从别人的源代码我学到了很多东西,而自己却没有什么贡献,一直感到很惭愧,这份代码应该是我github上面算法含金量最高的了。
多层图的构建
首先,要了解经典Graphcuts是多少层,它是多少层?是两层,即将目标分为两类;
然后,要明白Tlink的含义,Tlink一般都是通过已观测的信息,所以将目标分为两类时,其Tlink都是通过已观测信息得到的;
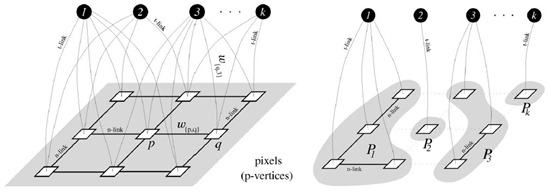
其次,将以上的两类变成多类,则通过多类观测的信息,构建多类图(这个多类最初在Boykov的文章中乘坐MultiGraph),长得类似这个形状,可以通俗的认为是有多个源点的图,其对Multi-Label问题的优化可具体看Fast Approximate Energy Minimization via Graph Cuts;
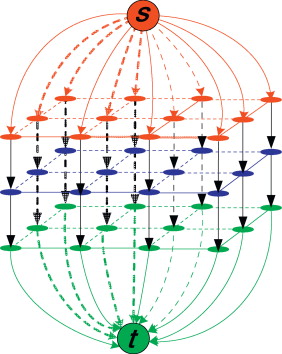
我们提出的是MultiLayerGraph,如文章最开始的图所示。每一层(红,蓝,绿)内部的构建都是相同的,如之前的博文所述Nlink,那么上图认为是几层图呢?直观上要么是三层(s,t不算)或五层(s,t各算一层)。然而实际是四层!
Graphcuts类方法分割得到的类数,取决于Tlink的层数
我们假定,Tlink表示的都是相似性的倒数,即越相似,Tlink越小,考虑到最大流最小割算法切断的是最小权值,所以最相似的肯定越可能被切断!
于是乎,我们就采取这样的策略:构建N层图,比如上述的四层图;然后根据观测信息设置每层的Tlink;最后,执行最大流算法,并观测当前节点的Tlink是在哪一层被切断!
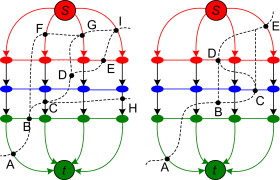
多层图一个标准的割应该如右图左边的,右边是不对的,并且通过算法是不能得到的。
如何判断Tlink是在哪里切断的呢?
这就源自最初的Graphcuts算法了
在开源的Graphcuts算法中,在计算最大流时,一直维护着两颗“树”,一棵是由S延伸出来的;一棵是由T延伸出来的。在最后时刻,由这两棵树交界的部分形成最小割。
那么就有这样一个特点,假设当前Tlink被割断,则上面一个点肯定来自S树,下面一个点肯定属于T树。所以通过这个特点,可以判断在哪切断的 :)
这实际上是一种近似的方法,为什么这么说呢?
上面的网络流图中,每一层的节点实际上都是相同的,不同的是Tlink有多层,所以完成一次分类,产生了一些额外的“边”需要计算进来并考虑切断。
不过这个误差不太好估计。
总的来说,图割的结果很取决于参数,一般来说,所有Tlink会统一权值的计算方法,所有Nlink也会统一权值的计算方法;然而Tlink与Nlink的比例该如何设定?
一般只有实验中来知道吧。
这篇关于从图割到图像分割 - 多层图图割的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







