本文主要是介绍谷歌送上主播福利,手机拍视频实时换背景,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!


YouTube stories 中的神经网络视频分割(加特效)
AI 科技评论按:视频分割是一项用途广泛的技术,把视频的前景和背景分离之后,导演们、视频制作者们就可以把两者作为两个不同的视觉层,便于后续的处理或者替换。对背景的修改可以传递不同的情绪、可以让前景的主人公显得去了另一个地方,又或者增强这条视频消息的影响力。不过,这项工作传统上都是由人工完成的,非常费时(比如需要逐帧把里面的人描选出来);省时的办法则需要一个专门的电影工作室,布置绿幕作为拍摄背景,从而实时替换成别的需要的内容。
不过,以往复杂的背景分割工作,现在仅仅靠一台手机就可以完成了!谷歌今天在 YouTube app 中的 stories 里集成了一个新的视频分割功能,在手机上就可以准确、实时地分割视频的前景背景。这个功能是专门为 YouTube 视频作者们设计的,在目前的 beta 版中 stories 作为新的轻量级视频格式,可以让视频作者们替换以及更改视频背景,不需要专门的设备就可以轻松增加视频的创作价值。谷歌也发布了一篇博客对其中的技术细节作了介绍,AI 科技评论编译如下。
任务目标
谷歌的研究人员们借助了机器学习的力量,把这个任务作为一个语义分割问题来考虑,并设计了卷积神经网络来达到目标。具体来说,他们针对手机的特点设计了适用的网络架构和训练过程,遵循着这几个要求和限制:
作为在手机上运行的解决方案,它需要足够轻量,运行速度需要比目前最先进的照片分割模型快 10 倍到 30 倍。对于实时推理任务,所需的模型计算结果的速度至少需要达到每秒 30 帧。
作为视频模型,它应当利用视频的时间冗余性(相邻的帧内容相似),自己展现出时间持续性(相邻的输出结果相似)
作为基本规律,高质量的结果也需要高质量的标注训练数据
数据集
为了给机器学习流水线提供高质量的训练数据,谷歌标注了上万张照片,其中包含了各种各样丰富的前景(人物)姿势和背景内容。标注内容里包括了精确到像素的前景人物的图像结构,比如头发、眼镜、脖子、皮肤、嘴唇等等,各类背景则统一标注为「背景」,标注质量在人类标注员的交叉验证测试中取得了 98% 的 IOU。

一张仔细标注为 9 个类别的训练样本示例;前景元素的标注区域直接覆盖在图像上
网络输入
这个视频分割任务的具体定义是对视频输入的每一帧(RGB 三个通道)计算出一张二值掩蔽图。这里需要解决的关键问题是让计算出的不同帧的掩蔽图之间达到时间持续性。现有的使用 LSTM 和 GRU 的方法虽然有效,但对于要在手机上实时运行的应用来说,需要的计算能力太高了。所以谷歌研究人员们想到的替代方案是把前一帧计算出的掩蔽图作为第四个通道,和新一帧本来的 RGB 三个通道一起作为网络输入,从而实现时间持续性。如下图
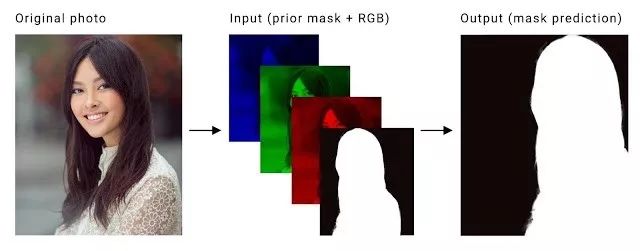
一帧原始图像(左图)会分离为三色通道,然后再加上前一帧图像算出的掩蔽图(中)。这些会一起作为神经网络的输入,用来预测当前帧的掩蔽图(右图)。
训练过程
对于视频分割任务,我们希望达到帧与帧之间的时间连续性,同时也要照顾到图像中内容的突然变化,比如人突然出现在摄像头视野中。为了训练模型能够鲁棒地处理这些使用状况,谷歌的研究人员们对每张图像的真实背景分割结果做了各种不同的处理后再作为来自前一帧的掩蔽图:
空的前一帧掩蔽:这种情况用来训练网络正确分割视频的第一帧,以及正确分割视野中新出现的物体。这模拟了某人突然出现在摄像头视野内的状况。
仿射变换过的真实背景掩蔽:轻微的变换可以训练网络据此进行调整,向前一帧的掩蔽适配。大幅度的变换就训练网络判断出掩蔽不适合并抛弃这个结果。
变换过的图像:对视频的原始图像做薄板样条平滑,模拟摄像头快速移动和转动时拍摄出的画面

演示实时视频分割
网络架构
根据修改过的输入/输出格式,谷歌的研究人员们以标准的沙漏型分割网络架构为基础,做了如下改进:
使用大卷积核、4 或者更大的大步距在高分辨率的 RGB 输入帧内检测物体特征。对通道数不多的层做卷积的计算开销相对较小(在这种情况下就是 RGB 三个通道的输入),所以在这里用大的卷积核几乎对计算需求没有影响。
为了提高运行速度,模型中结合大步距和 U-Net 类似的跳跃连接,激进地进行下采样,同时也在上采样时保留低层次的特征。对于谷歌的这个分割模型,有跳跃连接的模型的 IOU 要比没有跳跃连接的大幅提高 5%。
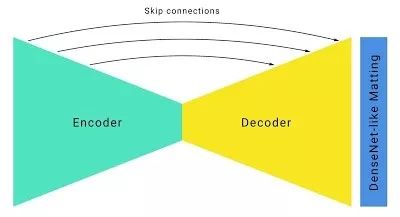
带有跳跃连接的沙漏型分割网络
为了进一步提高速度,谷歌研究人员们优化了默认的残差网络瓶颈。在学术论文中,研究者们通常喜欢在网络中部把通道数缩减为 1/4 (比如,通过使用 64 个不同的卷积核把 256 个通道缩减为 64 个通道)。不过,谷歌的研究人员们认为他们可以更加激进地缩减通道,可以缩减为 1/16 甚至 1/32,而且并不会带来性能的大幅下降。

大比例压缩的 ResNet 瓶颈
为了美化图像边缘、提高图像边缘分割的准确率,在整个分割网络之上增加了几层全分辨率的密集连接 DenseNet 层,这种做法和神经网络匹配很相似。这种技巧带来的模型总体数值表现提升并不大,仅有 0.5% IOU,但是人类视觉感知上的分割质量提升很明显。
经过这些修改之后,网络在移动设备上的运行速度非常块,不仅在 iPhone 7 上有超过 100 帧每秒、Pixel 2 上超过 40帧每秒的速度,而且还有很高的准确率(根据谷歌的验证数据集达到了 94.8%),为 YouTube stories 功能提供了各种丰富流畅的实时响应效果。

视频分割团队的近期目标是在 YouTube stories 功能的小规模开放期间进行更多测试。随着分割技术改善、拓展到更多标签的识别分割,谷歌的 AR 服务中未来也有可能会把它集成进去。
via GoogleBlog, AI 科技评论编译。



这篇关于谷歌送上主播福利,手机拍视频实时换背景的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![C#实战|大乐透选号器[6]:实现实时显示已选择的红蓝球数量](https://i-blog.csdnimg.cn/direct/cda2638386c64e8d80479ab11fcb14a9.png)
