本文主要是介绍美团外卖基于GPU的向量检索系统实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
到家搜索业务具有数据量大、过滤比高等特点,为了在保证高召回率的同时进一步提高检索性能,美团到家研发平台联合基础研发平台基于GPU实现了支持向量+标量混合检索的通用检索系统,召回率与检索性能均有较大提升。本文将介绍我们在GPU向量检索系统建设中遇到的挑战及解决思路,希望对大家有所帮助或启发。
-
1 背景
-
2 美团外卖向量索引的发展历程
-
2.1 HNSW(Hierarchical Navigable Small World)
-
2.2 IVF (Inverted File)
-
2.3 IVF-PQ(Inverted File with Product Quantization)
-
2.4 IVF-PQ+Refine
-
2.5 基于地理位置的向量检索
-
-
3 目标与挑战
-
3.1 目标
-
3.2 解决方案探索
-
-
4 GPU向量检索系统
-
4.1 前置过滤实现方案选择
-
4.2 GPU向量检索引擎
-
4.3 向量检索系统工程实现
-
-
5 收益
-
6 展望
1 背景
随着大数据和人工智能时代的到来,向量检索的应用场景越来越广泛。在信息检索领域,向量检索可以用于检索系统、推荐系统、问答系统等,通过计算文档和查询向量之间的相似度,快速地找到与用户需求相关的信息。此外,在大语言模型和生成式AI场景,向量索引做为向量数据的底层存储,也得到了广泛的应用。
如下图所示,向量检索主要分为三个步骤:(1)将文本、图像、语音等原始数据经过特征抽取,模型预估,最终表征为向量集合;(2)对输入Query采用类似的方式表征为向量;(3)在向量索引中找到与查询向量最相似的K个结果。一种简单直接的检索方式是与向量集合进行逐一比较,找到与查询向量最相似的向量。这种方法也被称为暴力检索。在大数据量或者高维度场景中,暴力检索的耗时和计算资源消耗巨大,无法在现实场景中直接使用。
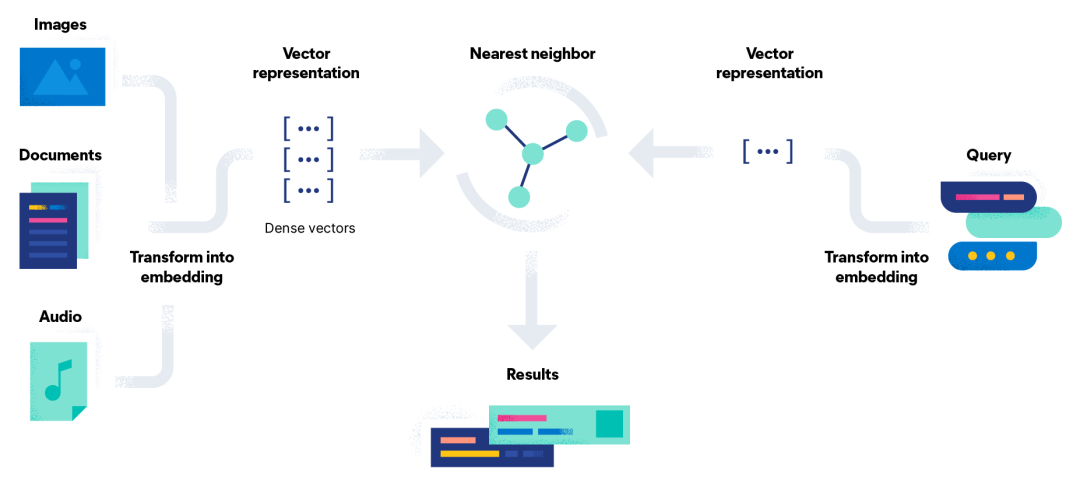
为了解决上述问题,业界提出ANN(Approximate Nearest Neighbor)近邻检索方案:通过构建有效索引,减少向量计算量,牺牲一定的召回精度以换取更高的检索速率。另一方面,研究如何通过GPU的并行计算能力,加速向量相似计算,也是一个比较热门的发展方向之一。Facebook开源的向量检索库Faiss在GPU上实现了多种索引方式,与CPU版性能相比,检索速率提升5到10倍。开源的向量检索引擎Milvus基于GPU加速的方案使得检索提高10+倍。
目前,向量检索已经广泛应用在美团外卖搜推业务各场景中。相较于其他业务场景,美团外卖业务特点具有较强的Location Based Service(LBS)依赖,即商家的配送范围,决定了用户所能点餐的商家列表。以商品向量检索场景为例:向量检索结果集需要经过“可配送商家列表”过滤。
此外,在不同的业务场景使用过程中,还需要根据商家商品的品类、标签等标量属性进行过滤。当前,美团外卖向量检索基于Elasticsearch+FAISS进行搭建,实现了10亿级别+高维向量集的标量+向量混合检索的能力。为了在保证业务高召回率的同时进一步减少检索时间,我们探索基于GPU的向量检索,并实现了一套通用的检索系统。
2 美团外卖向量索引的发展历程
在美团外卖向量检索系统的建设过程中,我们相继使用了HNSW(Hierarchical Navigable Small World),IVF(Inverted File),IVF-PQ(Inverted File with Product Quantization)以及IVF-PQ+Refine等算法,基于CPU实现了向量检索能力。在过去的几年间,我们对Elasticsearch进行定制,实现了相关的向量检索算法,在复用Elasticsearch检索能力的情况下支持了标量-向量混合检索。下面是这四种技术的简介及演进历程。
| 2.1 HNSW(Hierarchical Navigable Small World)
HNSW是一种用于大规模高维数据近似最近邻搜索的算法,它的基本思想是使用一种层次化的图结构,每一层都是一个导航小世界图,从而实现了在高维空间中的高效搜索。导航小世界图是一种有着特殊拓扑结构的图,它的特点是任意两点之间的路径长度都很短,而且可以快速找到。
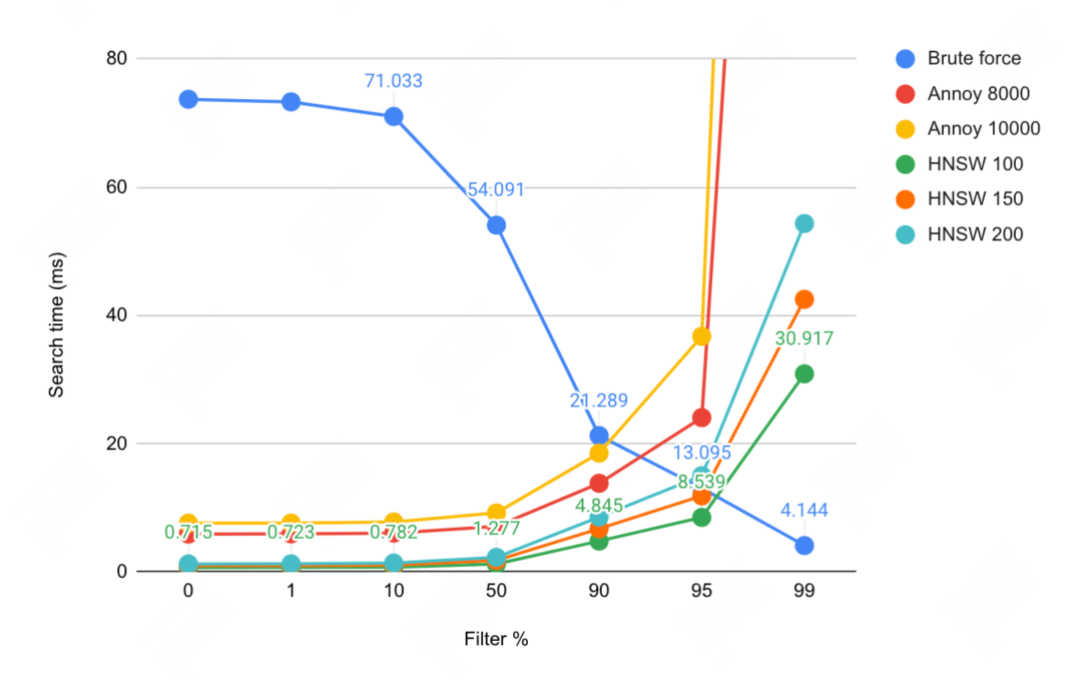
在HNSW算法中,这种导航小世界图的层次结构使得搜索过程可以从图的高层开始,快速定位到目标点的大致位置,然后逐层向下精细化搜索,最终在底层找到最近邻,在通用检索场景上有显著的优势。然而该算法在高过滤比下性能会有折损,从而导致在到家搜推这种强LBS过滤场景下会暴露其性能的劣势。业界有较多相关的benchmark可以参考,以Yahoo的向量检索系统Vespa相关博客为例,性能与召回率的趋势如下:
| 2.2 IVF (Inverted File)
IVF是一种基于倒排索引的方法,它将高维向量空间分为多个簇(Cluster),每个簇对应一个倒排列表,存储了属于该簇的向量索引。这种方法大大减少了搜索时需要比较的向量数量,从而提高了检索速度。它的缺点是需要存储原始的向量数据,同时为了保证检索性能需要将其全量加载到内存中,从而占用了大量的内存空间,容易造成内存资源瓶颈。
| 2.3 IVF-PQ(Inverted File with Product Quantization)
在候选集数量巨大的场景下,比如商品向量检索场景下,IVF带来的内存空间大的问题很快就显现出来,为了解决内存空间的问题,开始尝试使用了IVF-PQ方法。该方法在IVF的基础上,使用了乘积量化(Product Quantization,PQ)的方法来压缩向量数据。PQ将高维向量分为多个子向量,然后对每个子向量进行量化,从而大大减少了对内存空间的需求。
然而,由于量化过程会引入误差,因此IVF-PQ的检索精度会低于IVF,从而导致召回率无法满足线上要求,对召回率要求相对较低的场景可以使用IVF-PQ,对召回率有一定要求的场景需要其他解决方案。
| 2.4 IVF-PQ+Refine
为了提高IVF-PQ的检索精度,进一步采用了IVF-PQ+Refine的方案,在IVF-PQ的基础上,在SSD磁盘上保存了未经压缩的原始向量数据。检索时,通过IVF-PQ召回数量更大的候选向量集合,然后获取对应的原始向量数据进行精确计算,从而提高检索精度。这种方法既保留了IVF-PQ的存储优势,解决了内存资源瓶颈,又保证了召回率,因此在实际应用中得到了广泛的使用。
| 2.5 基于地理位置的向量检索
美团外卖业务有一个区别于普通电商的明显特征——LBS特征,用户和商家的距离在很大程度上影响着用户的最终选择。因此可以考虑在向量检索过程中增加地理位置因素,使距离用户更近的商品可以优先被检索到。通过将经纬度编码为向量,优化具体做法是将用户或商家的经纬度以加权的方式加入查询Query和候选向量中,在计算Query和候选向量的相似度时,距离因素就可以在不同程度上影响最终的检索结果,从而达到让向量索引具备LBS属性的目标。在加入地理位置信息后,向量检索的召回率有较大提升。
除了以上几种检索方式,常见的向量检索方式还有Flat(即暴力计算),可以实现100%的召回率,但是由于计算量大,其性能较差,一般仅用于小规模的数据场景。
3 目标与挑战
| 3.1 目标
在以上几个方案落地后,向量+标量混合检索、前置过滤、支持海量数据检索几个挑战都得到了解决,但是检索性能及召回率与理想目标仍有一定差距,需要探索其他可能的解决方案。考虑到美团外卖的业务场景,目标方案应该满足以下要求:
-
支持向量+标量混合检索:在向量检索的基础上,支持复杂的标量过滤条件。
-
高过滤比:标量作为过滤条件,有较高的过滤比(大于99%),过滤后候选集大(以外卖商品为例,符合LBS过滤的商品向量候选集仍然超过百万)。
-
高召回率:召回率需要在95%+水平。
-
高性能:在满足高召回率的前提下,检索耗时Tp99控制在20ms以内。
-
数据量:需要支持上亿级别的候选集规模。
在调研业界向量检索方案后,我们考虑利用GPU的强大算力来实现高性能检索的目标。当前业界大部分基于GPU的向量检索方案的目标都是为了追求极致的性能,使用GPU来加速向量检索,如Faiss、Raft、Milvus等,然而它们都是面向全库检索,不直接提供向量+标量混合检索的能力,需要在已有方案的基础上进行改造。
| 3.2 解决方案探索
实现向量+标量混合检索,一般有两种方式:前置过滤(pre-filter)和后置过滤(post-filter)。前置过滤指先对全体数据进行标量过滤,得到候选结果集,然后在候选结果集中进行向量检索,得到TopK结果。后置过滤指先进行向量检索,得到TopK*N个检索结果,再对这些结果进行标量过滤,得到最终的TopK结果。其中N为扩召回倍数,主要是为了缓解向量检索结果被标量检索条件过滤,导致最终结果数不足K个的问题。
业界已有较多的成熟的全库检索的方案,后置过滤方案可以尽量复用现有框架,开发量小、风险低,因此我们优先考虑后置过滤方案。我们基于GPU的后置过滤方案快速实现了一版向量检索引擎,并验证其召回率与检索性能。GPU中成熟的检索算法有Flat、IVFFlat和IVFPQ等,在不做扩召回的情况下,召回率偏低,因此我们在benchmark上选择了较大的扩召回倍数以提高召回率。
测试数据集选取了线上真实的商品数据,据统计,符合标量过滤条件的候选向量数量平均为250万,在单GPU上验证后置过滤检索性能与召回率如下:
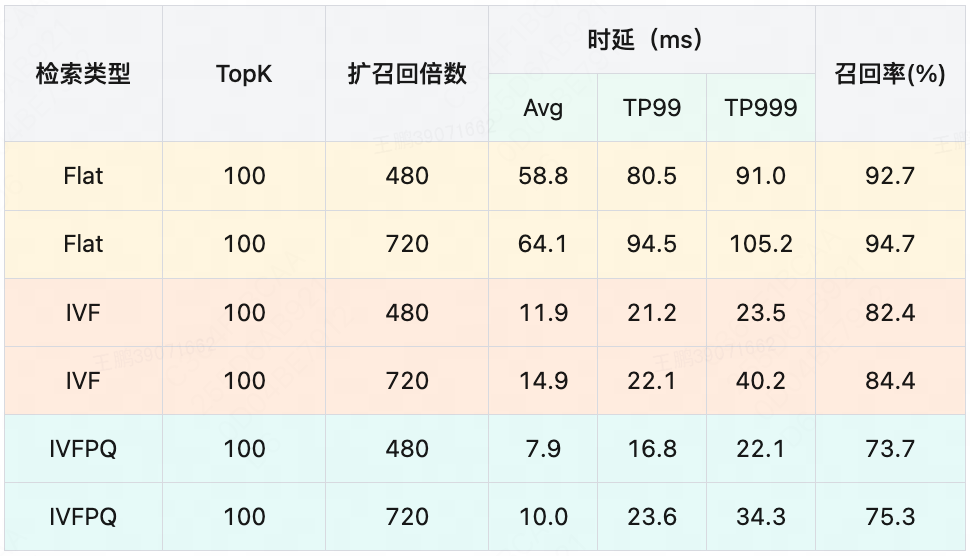
测试结果表面,以上三种算法均无法同时满足我们对检索性能和召回率的需求。其中IVF与IVFPQ召回率较低,Flat算法虽然召回率较高,但是与全体候选集计算向量相似度导致其性能较差。
举个例子,候选向量数据规模为1000万,向量维度为D。
(1)Flat是纯暴力计算的算法,精度最高,但需要在全体候选集上计算相似度,单条查询向量的计算量为1000万*D次浮点运算。
(2)IVF在Flat的基础上通过IVF倒排索引,将候选集划分成多个簇(Cluster),然后选取部分离查询向量较近的簇计算相似度,这样可以按比例降低计算量,如果将候选集分成n_list=1024个簇,每次查询只选取n_probe=64个簇,则单条向量的计算量为Flat的1/16,即62.5万*D次浮点运算。
(3)IVFPQ对比IVF算法,使用了乘积量化,将D维向量切分成M组子向量,每组子向量训练出K个聚类中心,如果M=8,K=256,则单条查询的计算量为8*256*D次浮点计算+1000万*8次查表+1000万*8次加法运算。
在Flat算法的基础上,我们考虑通过向量子空间划分的方式,将全量候选集划分为多个向量子空间,每次检索时选取其中的一部分向量子空间,从而减少不必要的计算量,提高检索性能。
考虑到外卖搜索的强LBS属性,可以基于GeoHash来进行向量子空间划分。构建索引时,根据商家的地理位置(经纬度)计算GeoHash值,将全量商品数据划分为多个向量子空间。检索时,根据用户的地理位置信息计算其GeoHash值,并扩展至附近9个或25个GeoHash块,在这些GeoHash块内采用Flat算法进行向量检索,可以有效减少计算量。这种向量子空间划分方式有效地提高了检索性能,但是存在某些距离稍远的商家无法被召回的情况,最终测得的召回率只有80%左右,无法满足要求。
综上,后置过滤方案无法同时满足检索性能和召回率的需求,而GPU版本的Faiss无法实现前置过滤功能,考虑到美团外卖的业务场景,向量+标量混合检索能力是最基本的要求,因此我们决定自研GPU向量检索引擎。
4 GPU向量检索系统
| 4.1 前置过滤实现方案选择
基于GPU的向量检索,要想实现前置过滤,一般有三种实现方案:
-
所有原始数据都保存在GPU显存中,由GPU完成前置过滤,再进行向量计算。
-
所有原始数据都保存在CPU内存中,在CPU内存中完成前置过滤,将过滤后的原始向量数据传给GPU进行向量计算。
-
原始向量数据保存在GPU显存中,其他标量数据保存在CPU内存中,在CPU内存完成标量过滤后,将过滤结果的下标传给GPU,GPU根据下标从显存中获取向量数据进行计算。
由于GPU与CPU结构与功能上的差异性,使用GPU完成前置过滤,显存资源占用量更大,过滤性能较差,且无法充分利用过滤比大的业务特点,因此不考虑方案1。
方案2与方案3性能对比与各自的优点如下所示:
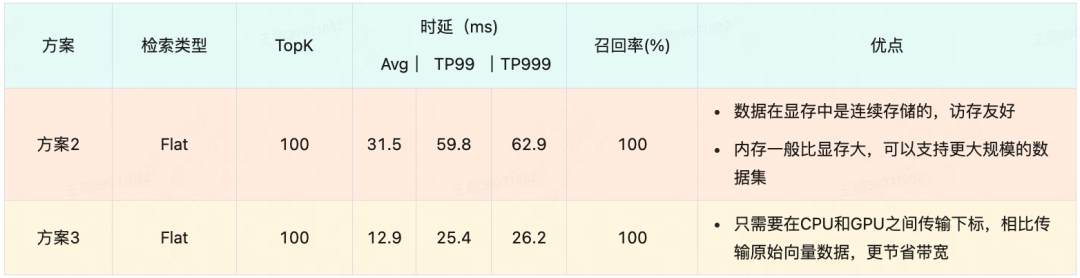
实验结果表明,方案2在数据拷贝阶段耗时严重,时延无法达到要求。因为在美团外卖的场景下,过滤后的数据集仍然很大,这对CPU到GPU之间的数据传输带宽(A30显卡带宽数据如下 CPU-GPU:PCIe Gen4: 64GB/s;GPU-GPU:933GB/s)提出了很高的要求,因此我们最终选择了方案3。
| 4.2 GPU向量检索引擎
4.2.1 数据结构
考虑到显存的价格远高于内存,因此我们在设计方案的过程中,尽可能将数据存储在内存当中,仅将需要GPU计算的数据存储在显存当中。
内存中保存了所有的标量数据,数据按列存储,通过位置索引可以快速找到某条数据的所有字段信息,数据按列存储具备较高的灵活性和可扩展性,同时也更容易进行数据压缩和计算加速。针对需要用于过滤的标量字段,在内存中构造了倒排索引,倒排链中保存了对应的原始数据位置索引信息,内存数据结构如下图所示:
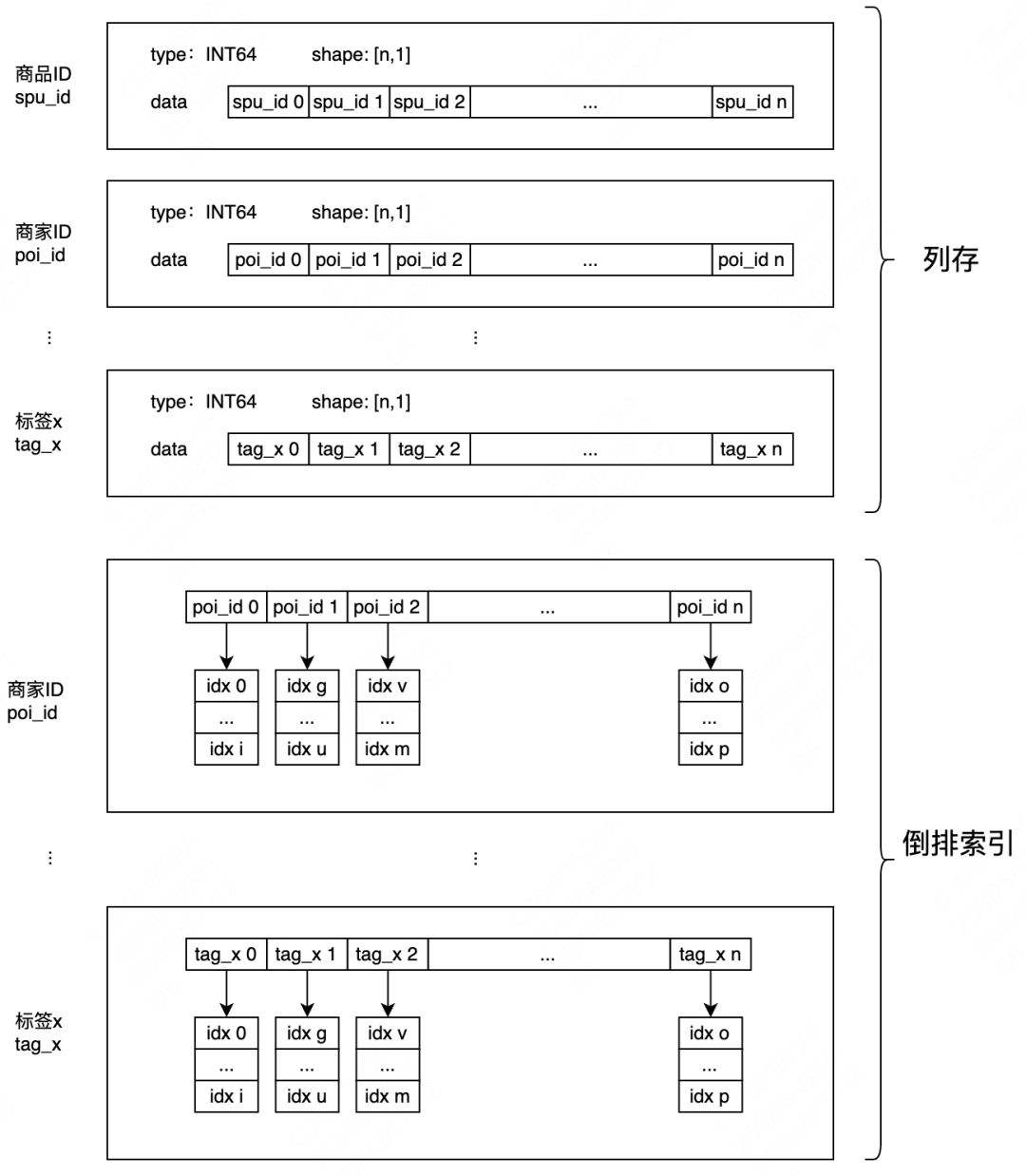
显存中保存了所有的向量数据,数据位置索引与内存中的数据一一对应,可以通过位置索引快速获取某条数据的向量信息,如下图所示:

4.2.2 检索流程
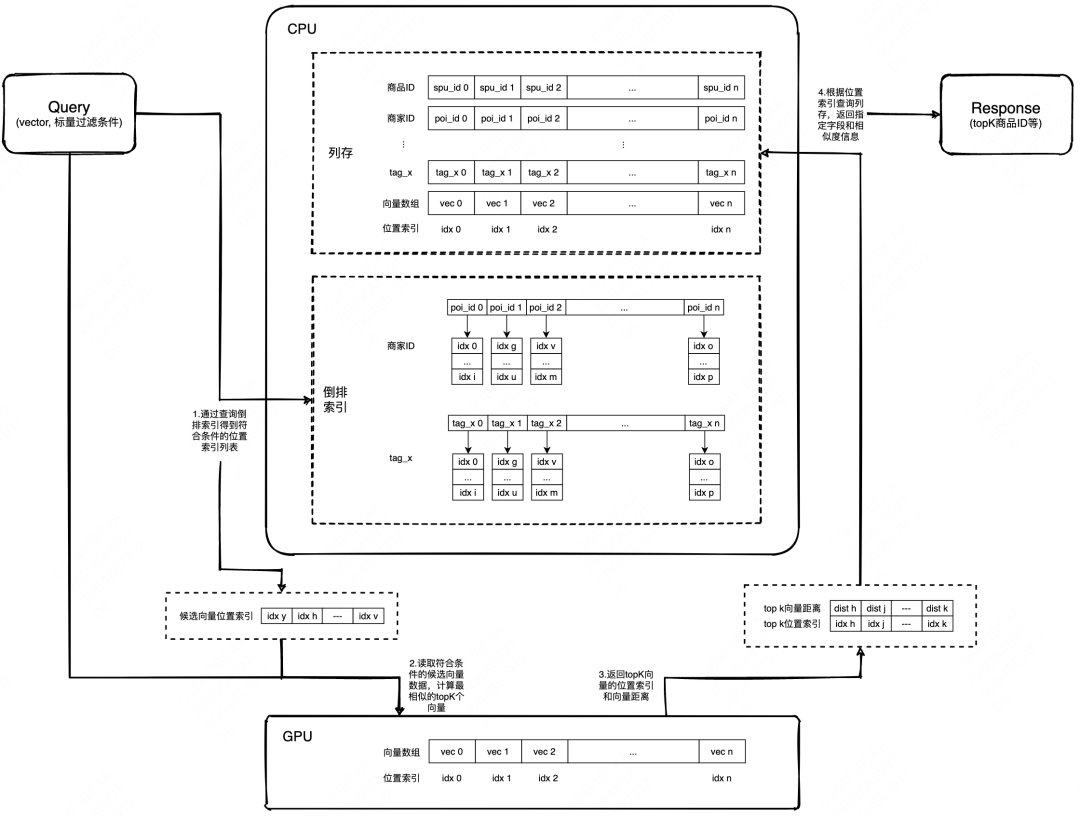
Flat暴力检索
初始化阶段,在内存中构建用于标量过滤的倒排索引,同时,将向量数据从CPU内存拷贝到GPU显存,通过位置索引进行关联。
1. 标量过滤
标量过滤过程在CPU内存中进行,通过内存中的倒排索引,可以快速得到符合某个标量过滤条件的原始数据位置索引列表,通过倒排索引的求交、求并等逻辑,可以支持多个标量过滤条件的与、或关系组合,最终,得到所有符合条件的位置索引列表。
2. 相似度计算
相似度计算在GPU中进行,通过上一步标量过滤得到的位置索引列表,从GPU显存中读取符合条件的候选向量数据,然后使用常见的向量距离算法计算最相似的TopK个向量,将检索结果下表列表回传给CPU。
3. 检索结果生成
通过上一步的检索结果下表列表,在CPU内存中获取对应record记录并返回。
整体检索流程如下:
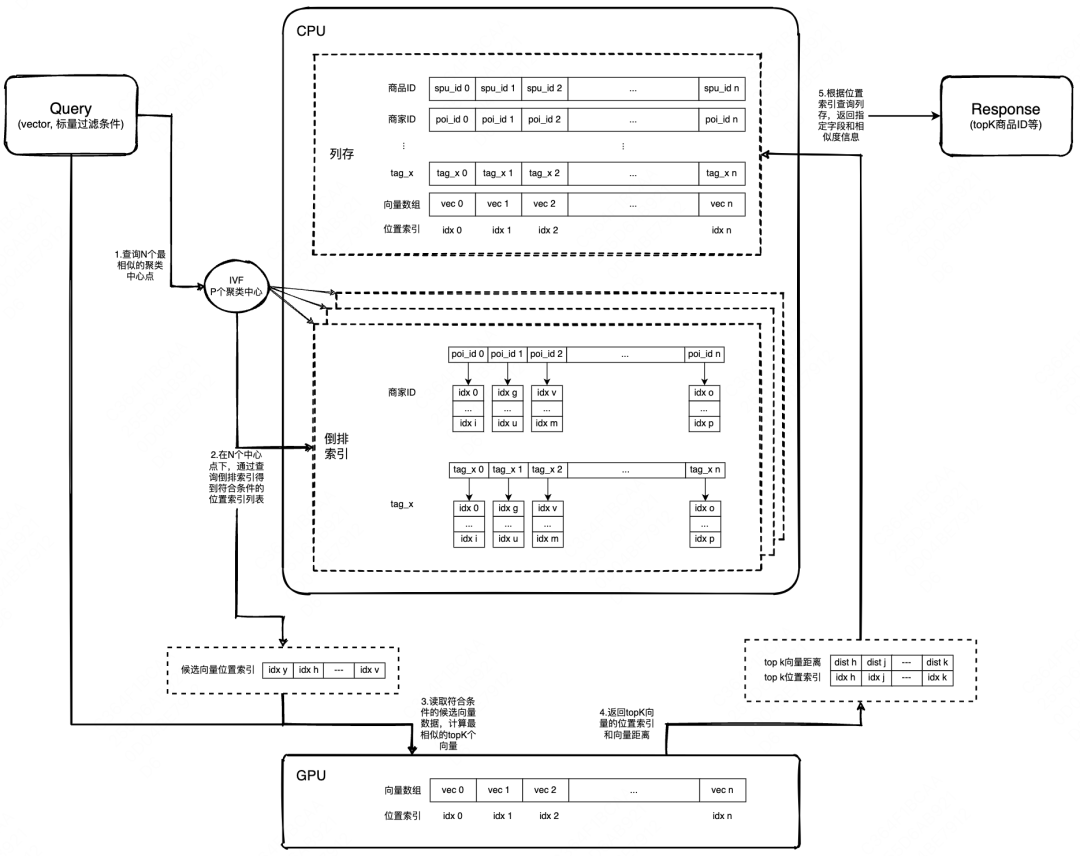
IVF近似检索
在某些场景下,我们对检索性能有更高的要求,同时对召回率的要求可以适当放宽,因此我们在GPU向量检索引擎上支持了IVF近似检索。
在初始化阶段,使用向量数据训练出P个聚类中心,并针对每个聚类中心构建局部的倒排索引,倒排索引结构与Flat方案类似,区别在于位置索引信息只保存在最近的聚类中心下。
1. 标量过滤
标量过滤过程在CPU内存中进行,先找到与query向量最近的N个聚类中心点,在这些聚类中心点下进行标量过滤,得到N个候选位置索引列表,再merge 成最终的候选位置索引列表。与Flat方案相比,IVF近似检索减少了计算量,因此能获得更好的检索性能。
2. 相似度计算
相似度计算阶段与Flat方案相同。
3. 检索结果生成
检索结果生成阶段也与Flat方案相同。
整体检索流程如下:
在单GPU上验证检索性能与召回率如下(测试数据集同后置过滤):
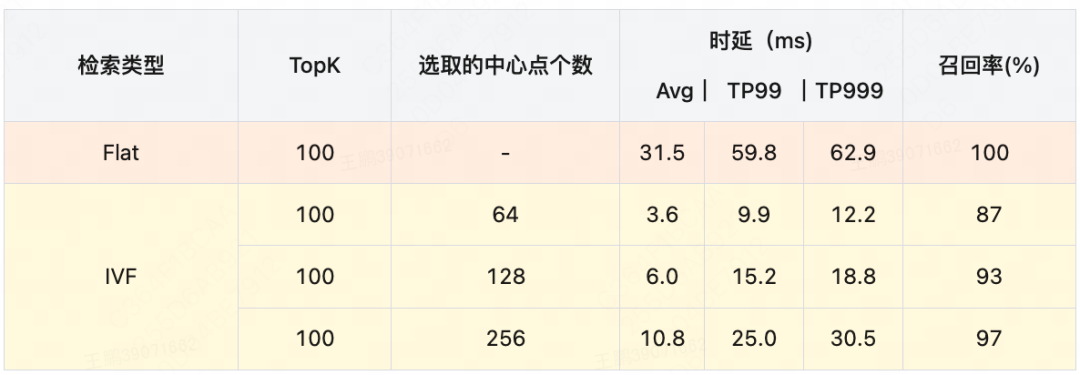
可见,无论是Flat还是IVF,在相同的召回率下,使用前置过滤的性能都要明显好于后置过滤。
4.2.3 性能优化
完成前置过滤的向量检索功能之后,我们对向量检索引擎做了一系列优化。
1. 单GPU性能优化
-
高并发支持,通过Cuda Stream,GPU可以并行处理多个查询请求,高并发压测下,GPU利用率可以达到100%。
-
通过GPU实现部分标量过滤功能,支持在GPU上实现部分标量过滤功能,向量计算与标量过滤同处一个Kernel,充分利用GPU并行计算能力(标量过滤本身是一个无状态操作,天然支持并行处理,CPU并发能力受限于CPU核数,但GPU可以支持上千个线程的并发,所以在性能上体现出明显优势)。
-
资源管理优化,支持句柄机制,资源预先分配,重复利用。每个句柄持有一部分私有资源,包含保存向量检索中间计算结果的可读写内存、显存,以及单独的Cuda Stream执行流;共享一份全局只读公有资源。在初始化阶段,创建句柄对象池,可以通过控制句柄数量,来调整服务端并发能力,避免服务被打爆。在检索阶段,每次向量检索需从句柄对象池中申请一个空闲的句柄,然后进行后续的计算流程,并在执行完后释放响应的句柄,达到资源回收和重复利用的目的。
在单GPU上性能优化后的检索性能与召回率如下(测试数据集同后置过滤):
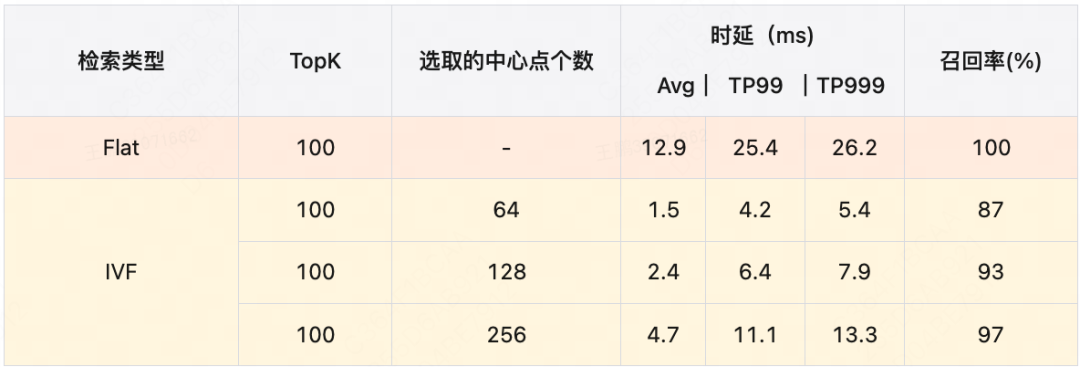
2. 多GPU并行检索
除了以上优化方案,还可以考虑将数据分片,通过多GPU并行检索,减少单卡计算量来提升检索性能;同时,多卡架构也能支持更大规模的向量数据检索。
相比多机多卡的分shard架构,单机多卡可以有效减少网络传输开销,并且具有较低的索引加载复杂度,因此我们最终选择了单机多卡的数据分片方案,单台服务器部署多张GPU,检索时并行从本地多张GPU中检索数据,在CPU内存中进行数据合并。
3. FP16精度支持
为了支持更大规模的向量数据检索,我们还在GPU检索引擎上支持了半精度计算,使用FP16替换原来的FP32进行计算,可以节省一半的GPU显存占用,经验证Flat召回率由100%下降到99.4%,依然满足需求。使用半精度之后,单机可以加载近10亿数据,足够支撑较长时间的业务数据增长。
| 4.3 向量检索系统工程实现
向量检索系统的工程化实现包括在线服务和离线数据流两部分,总体架构图如下:
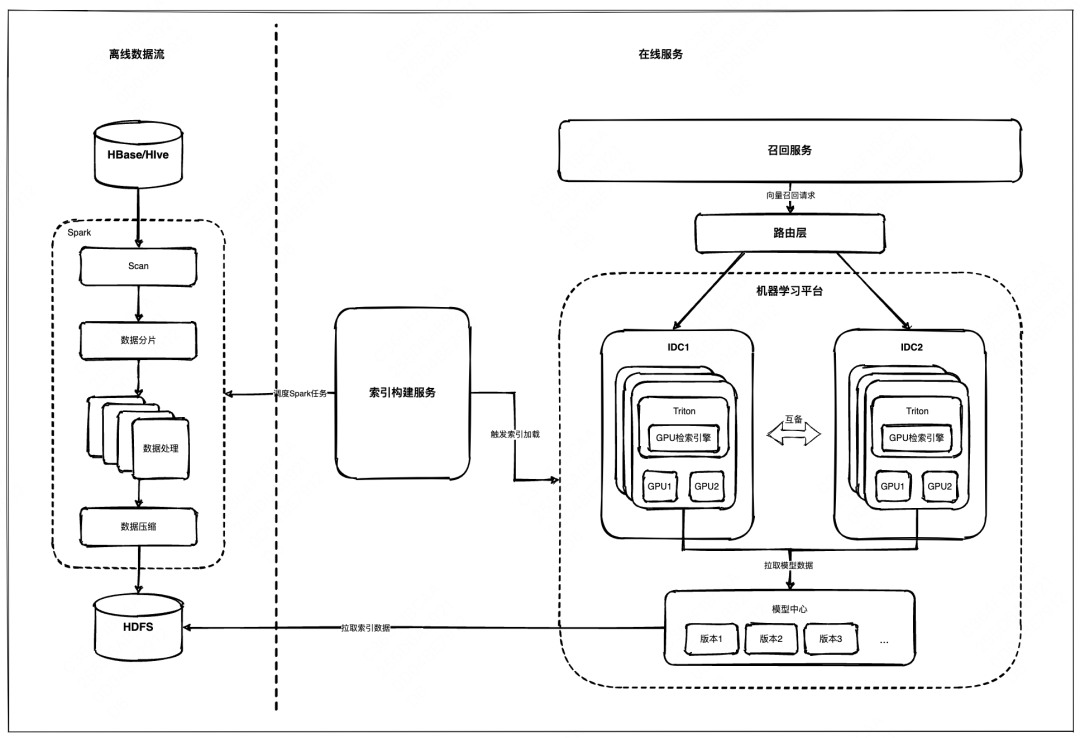
GPU 检索系统上线后实际性能数据如下(数据量1亿+):

5 收益
到家搜索团队面向在线服务场景实现的GPU向量检索系统,目前已经应用于外卖商品向量检索,向量召回链路的检索性能、召回率均有显著的提升,满足策略对召回扩量和策略迭代的需求,具体提升如下:
-
向量索引召回率由85%提升至99.4%。
-
向量索引检索时延TP99降低89%,TP999降低88%。
6 展望
-
GPU向量检索系统目前只支持T+1全量构建索引,后续计划支持实时索引。
-
GPU向量检索当前支持FLAT和IVF检索算法,后续计划支持HNSW算法,在过滤比较低的场景下可提供更高的检索性能。
-
除了GPU,后续还会在NPU等新硬件上做更多的尝试。
---------- END ----------
推荐阅读
| 美团外卖搜索基于Elasticsearch的优化实践
| 大众点评内容搜索算法优化的探索与实践
| 美团搜索多业务商品排序探索与实践
这篇关于美团外卖基于GPU的向量检索系统实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



