本文主要是介绍leetcode 1766,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
leetcode 1766
题目

例子
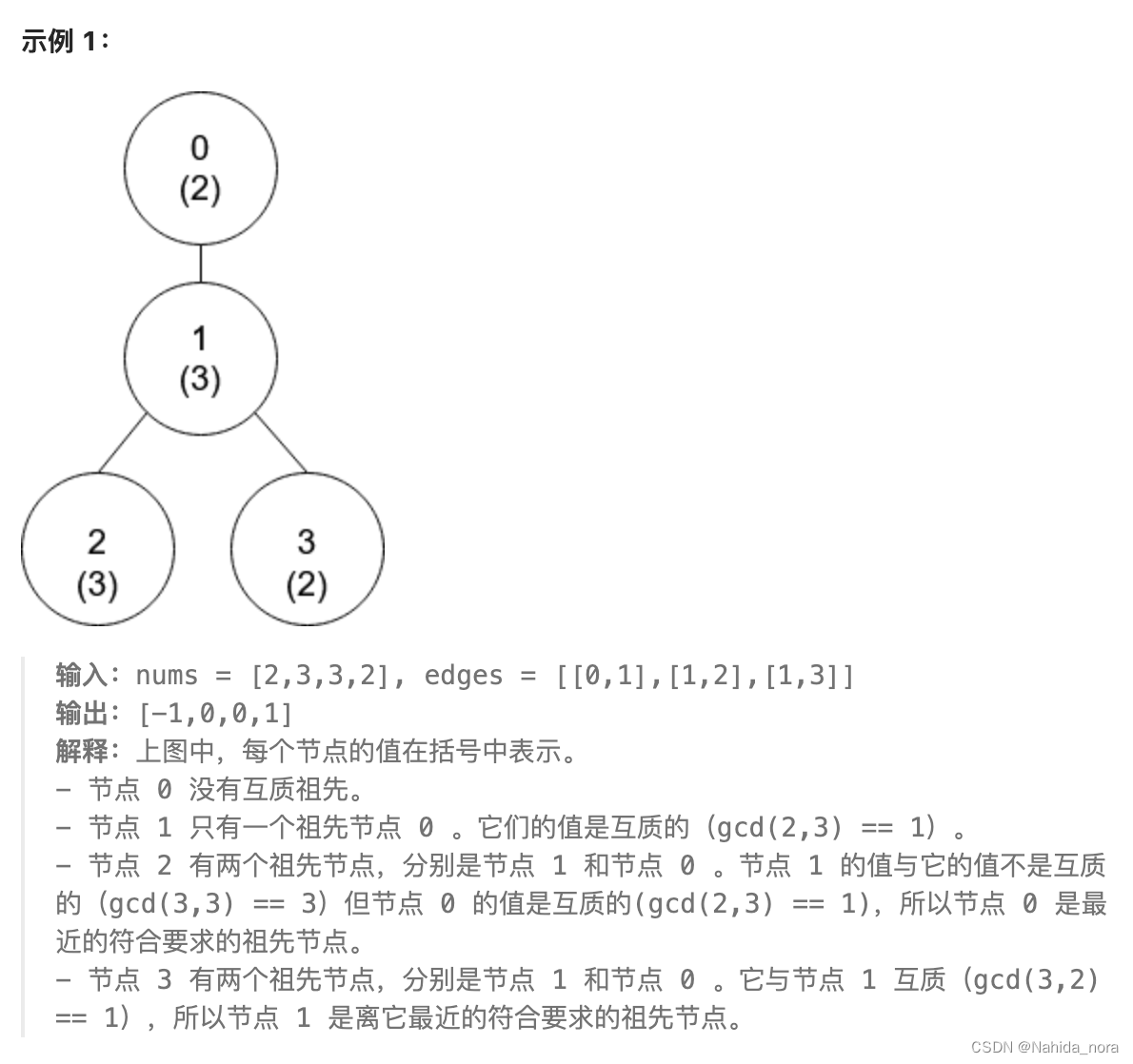
思路
将边的关系,转化为树结构。
记录val 对应的id 列表。
记录是否遍历过节点。
记录id 和对应的深度。
使用dfs, 从根开始遍历。
代码实现
class Solution {
private:vector<vector<int>> gcds;//val : the id of nodes matching the val vector<vector<int>> val_to_id;// i-th node : parent and childern of i-th nodevector<vector<int>> graph;//i-th node : depth of i-th nodevector<int> dep;//i-th node : ans of i-th nodevector<int> ans;public:void dfs(vector<int>& nums, int id, int depth){dep[id] = depth;for(int val : gcds[nums[id]]){if(val_to_id[val].empty()){//dfs 当前深度,找不到对应的gcd的值continue;}else{//获取已经遍历的节点的val的对应的id, 从根开始记录val_to_id的列表,所以back应该是最近的节点。int last_id = val_to_id[val].back();if(ans[id] == -1 || dep[last_id] > dep[ans[id]]){ans[id] = last_id;}}}val_to_id[nums[id]].push_back(id);for(int child_id : graph[id]){//等于-1没有遍历过if(dep[child_id] == -1){dfs(nums, child_id, depth +1);}}val_to_id[nums[id]].pop_back();}vector<int> getCoprimes(vector<int>& nums, vector<vector<int>>& edges) {int n = nums.size();gcds.resize(51);val_to_id.resize(51);ans.resize(n, -1);dep.resize(n, -1);graph.resize(n);for(int i=1; i<= 50; i++){for(int j=1; j<= 50; j++){if(gcd(i,j) == 1){gcds[i].push_back(j);}}}for(const auto& val : edges){// 无向图,根据dep[id] 是否为-1, 判断是否遍历graph[val[0]].push_back(val[1]);graph[val[1]].push_back(val[0]);}dfs(nums, 0, 1);return ans;}
};
push_back 和 pop_back
push_back() 和 pop_back() 是 std::vector 容器类提供的两个重要成员函数,用于向向量尾部添加元素和删除尾部元素。
push_back()
push_back() 函数用于在 vector 的末尾添加一个新元素。它将新元素插入到向量的尾部,使得向量的大小增加 1。语法如下:
void push_back(const T& value);
void push_back(T&& value);
其中,value 是要添加到向量末尾的元素。如果 vector 的存储空间不足以容纳新元素,push_back() 函数会自动重新分配更大的存储空间,并将元素添加到向量的末尾。示例如下:
#include <iostream>
#include <vector>int main() {std::vector<int> vec;// 添加元素到向量尾部vec.push_back(10);vec.push_back(20);vec.push_back(30);// 打印向量的元素for (int num : vec) {std::cout << num << " ";}std::cout << std::endl;return 0;
}
输出为:
10 20 30
pop_back()
pop_back() 函数用于删除 vector 的末尾元素,减小向量的大小。它不会返回任何值。如果 vector 不为空,则会删除最后一个元素;如果 vector 为空,则调用 pop_back() 函数会导致未定义行为。语法如下:
void pop_back();
示例:
#include <iostream>
#include <vector>int main() {std::vector<int> vec = {10, 20, 30};// 删除向量的最后一个元素vec.pop_back();// 打印向量的元素for (int num : vec) {std::cout << num << " ";}std::cout << std::endl;return 0;
}
输出为:
10 20
在使用 pop_back() 函数之前,通常应该检查 vector 是否为空,以避免未定义行为。
这些函数是 std::vector 容器类的基本操作之一,非常常用于动态管理序列的大小和内容。
容器
在 C++ 中,容器是用来存储和管理一组对象的数据结构。标准模板库(STL)提供了多种容器,每种容器都有自己的特点和适用场景。以下是 C++ 中常用的几种容器:
-
Vector(向量):
- 动态数组,大小可以动态增长。
- 支持快速随机访问。
- 在尾部插入元素的开销低,但在中间或头部插入元素的开销较高。
- 适合需要频繁对尾部进行插入和删除操作的场景。
-
Deque(双端队列):
- 双端队列,支持在两端高效地进行插入和删除操作。
- 比向量更适合在两端进行频繁的插入和删除操作。
-
List(链表):
- 双向链表,支持在任意位置高效地进行插入和删除操作。
- 不支持随机访问,访问元素的时间复杂度为 O(n),而在头部和尾部插入和删除元素的时间复杂度为 O(1)。
-
Forward List(前向链表):
- 单向链表,与双向链表相比,每个节点只保存下一个节点的地址。
- 支持在链表头部高效地进行插入和删除操作,但不支持在链表尾部直接访问。
-
Stack(栈):
- 后进先出(LIFO)的数据结构,只允许在栈顶进行插入和删除操作。
- 基于向量或双端队列实现。
-
Queue(队列):
- 先进先出(FIFO)的数据结构,只允许在队尾插入元素,在队头删除元素。
- 基于双端队列实现。
-
Priority Queue(优先队列):
- 元素按照一定的优先级顺序排列,每次取出优先级最高的元素。
- 基于堆(heap)实现。
-
Set(集合):
- 不重复元素的集合,通常基于红黑树实现。
- 支持高效的插入、删除和查找操作,元素按照升序排序。
-
Multiset(多重集合):
- 允许重复元素的集合,通常基于红黑树实现。
- 元素按照升序排序。
-
Map(映射):
- 键值对的集合,每个键唯一对应一个值。
- 支持高效的插入、删除和查找操作,键按照升序排序。
-
Multimap(多重映射):
- 键可以重复的映射。
- 键按照升序排序。
这些容器都位于标准命名空间 std 中,可以通过包含相应的头文件来使用它们,例如 <vector>、<list>、<stack> 等。每种容器都有自己的优势和适用场景,选择合适的容器取决于具体的需求和性能要求。
push_back 函数
-
void push_back(const T& value);:这个函数接受一个常量引用作为参数。当调用这个函数时,它会复制参数value的值,并将这个值添加到容器的末尾。这意味着在函数调用过程中会发生数据的复制操作,因为它是通过常量引用传递的,所以不会改变传递给函数的实参。std::vector<int> vec; int x = 10; vec.push_back(x); // 使用常量引用版本,复制 x 的值到容器 -
void push_back(T&& value);:这个函数接受一个右值引用作为参数。当调用这个函数时,它会使用参数value的值,并将其添加到容器的末尾。这个版本的函数通常用于移动语义,它不会复制参数的值,而是窃取参数的资源(例如,移动对象的所有权),因此更高效。std::vector<std::string> vec; std::string str = "Hello"; vec.push_back(std::move(str)); // 使用右值引用版本,窃取 str 的资源到容器
下面是两个版本的使用示例:
#include <iostream>
#include <vector>
#include <string>int main() {// 使用常量引用版本std::vector<int> vec1;int x = 10;vec1.push_back(x); // 复制 x 的值到容器std::cout << "vec1 size: " << vec1.size() << std::endl;// 使用右值引用版本std::vector<std::string> vec2;std::string str = "Hello";vec2.push_back(std::move(str)); // 窃取 str 的资源到容器std::cout << "vec2 size: " << vec2.size() << std::endl;return 0;
}
在这个例子中,push_back(const T& value) 将会复制 x 的值到容器 vec1 中,而 push_back(T&& value) 则会窃取 str 的资源到容器 vec2 中。
引用
在 C++ 中,引用与传递地址有些相似,但并不完全等同。引用本质上是一个别名,它是被绑定到另一个对象或变量上的名称。当你使用引用时,实际上是在操作原始对象,而不是它的地址。
与传递地址不同的是,引用不需要进行解引用操作(使用指针时需要使用解引用操作符 *),因为引用本身就是原始对象的别名,所以操作起来更加直观和方便。
另外,使用引用传递参数时,不会涉及指针的语法,从而减少了一些错误的可能性,例如空指针引用等。同时,引用在编译期间会进行类型检查,从而提供了更强的类型安全性。
因此,虽然引用有些类似于传递地址的概念,但它们之间有着明显的区别。
引用传递是一种在函数参数中使用引用的机制,允许函数直接访问并修改调用者提供的变量。通过引用传递,可以避免复制大型对象,提高程序的性能并减少内存使用。
在C++中,引用传递通常通过引用参数实现,有两种类型的引用参数:
-
左值引用(Lvalue Reference):通过使用
&符号声明的引用类型。左值引用可以绑定到具有名称的变量,包括对象、数组、函数等。在函数中修改左值引用的值会影响到调用者提供的原始变量。void modifyValue(int& x) {x += 10; }int main() {int num = 5;modifyValue(num);std::cout << "Modified value: " << num << std::endl; // 输出 15return 0; } -
右值引用(Rvalue Reference):通过使用
&&符号声明的引用类型。右值引用通常用于移动语义,允许将资源(如临时对象)的所有权从一个对象转移给另一个对象。void modifyValue(int&& x) {x += 10; }int main() {modifyValue(5); // 临时对象的所有权转移给函数return 0; }
引用传递相比于值传递有以下优点:
- 避免对象的复制:使用引用传递可以避免复制大型对象,从而提高程序的性能和效率。
- 直接修改原始值:通过引用传递,函数可以直接修改调用者提供的变量的值,而无需返回值。
需要注意的是,引用传递可能会导致函数的行为不易理解,因为函数可以修改原始变量的值。因此,建议在使用引用传递时,对函数的行为进行良好的文档说明,以避免产生混淆。
左值和右值
在C++中,左值(lvalue)和右值(rvalue)是两种用于表示表达式的属性的术语。它们主要与对象的生命周期和可修改性相关联。
-
左值(Lvalue):
- 左值是可以标识并且持久存在于内存中的表达式,通常具有名称或者可以取地址的表达式。
- 左值表达式可以出现在赋值语句的左边或者右边,因为它们代表着一个确定的内存位置。
- 例如,变量、数组元素、返回左值引用的函数等都是左值。
-
右值(Rvalue):
- 右值是临时的、一次性的值,通常不具有名称或者不能被取地址。
- 右值表达式通常是在赋值语句的右边出现,它们表示的是一个临时的、无法被修改的值。
- 例如,常量、临时变量、返回右值引用的函数等都是右值。
在C++11引入的移动语义中,右值引用允许程序员将资源的所有权从一个对象转移给另一个对象,从而避免不必要的复制操作,提高了程序的性能和效率。
总的来说,左值表示具有名称和持久性的值,而右值表示临时的、一次性的值。右值引用允许有效地管理临时对象的生命周期和资源。
lambda 与引用
当使用 Lambda 表达式时,引用捕获允许在 Lambda 函数体内访问并修改外部作用域的变量。这对于需要在 Lambda 函数内部修改外部作用域变量的情况非常有用。以下是一个简单的 C++11 Lambda 表达式示例,展示了如何使用引用捕获:
#include <iostream>int main() {int x = 10;// Lambda 表达式使用引用捕获外部变量 xauto lambda = [&x]() {// 在 Lambda 函数体内部访问和修改外部变量 xstd::cout << "Inside lambda, x = " << x << std::endl;x += 5;};std::cout << "Before lambda, x = " << x << std::endl;// 调用 Lambda 函数lambda();std::cout << "After lambda, x = " << x << std::endl;return 0;
}
在这个示例中,Lambda 表达式 lambda 捕获了外部变量 x 的引用。Lambda 函数体内部可以访问和修改变量 x 的值。当调用 Lambda 函数后,会输出修改后的 x 值。
输出将会是:
Before lambda, x = 10
Inside lambda, x = 10
After lambda, x = 15
这里,在 Lambda 内部访问的 x 是外部的 x,并且通过引用捕获可以在 Lambda 内部修改外部的变量。
这篇关于leetcode 1766的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







