本文主要是介绍XSKY解读FAST‘20 论文 《关于如何高效率的对文件目录树进行快速克隆操作》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
XSKY解读FAST'20 论文 How to Copy File 《关于如何高效率的对文件目录树进行快速克隆操作》
01导读
这篇发表于FAST20会议的论文,是关于如何高效率的对文件目录树进行快速克隆操作,由来自北卡罗来纳大学教堂山分校的Yang Zhan,Yizheng Jiao以及 罗格斯大学,佩斯大学,石溪大学,VMWare研究中心的相关研究人员合作开发完成的。
本文并非是这篇论文的完整翻译稿,只是对里面的一些重点内容进行解读,有些地方解读不一定准确,建议感兴趣的同学结合原版论文一起阅读,以帮助大家拓宽思路。
文章中所用图表,除非特别注明,都来自于原版论文。
02概述
作者在一开始先介绍了快速克隆的背景和重要性。随着虚拟化的广为流行,各种应用对快速克隆都有着很强的需求,典型的,如快速创建虚拟机,就需要快速克隆出虚拟机的“root filesystem”即一个image磁盘文件。而在容器场景下,如docker会非常频繁的对一个特定的文件系统目录树进行快速拷贝,这些都需要高效的克隆机制。
针对于这些应用场景,现有的文件系统已经实现了一些“逻辑拷贝”功能,有别于“物理拷贝”,逻辑拷贝一般在实现时只进行一些元数据级别的拷贝,而只有在后续的修改中,才按需对文件数据进行拷贝并修改,这种功能称作COW(copy-on-write),这种方法在拷贝的时效性和空间的利用率方面都得到了较大的提升,因此现在已经成为克隆的基础技术。在实现时,一般存在着基于block粒度的COW和基于file或者dir级别的COW,比如btrfs和xfs使用的cp –reflink技术。
这里作者指出,对于经典的COW技术,主要存在着“拷贝粒度”的问题,比如对于基于file级别的COW,一次微小的修改就可能导致昂贵的拷贝,比如1G大小的文件,只修改其中的1个字节,也会触发1G文件的拷贝。这会极大的增加初次COW写入时延,而且也不可避免的造成了空间上的浪费。反之,如果拷贝粒度过小,则初次COW写入时延有保证,但却容易造成碎片化(想象一下1个很大的文件,4K拷贝粒度,随机写入则会造成很多个4K COW块),后续顺序读的时候,因为这些4K数据并不是连续的,则读取速度会很慢。因此这里作者提出了自己对高效克隆的看法,需要满足如下4个特性才能被称作是合格的,作者称为“Nimble clones (敏捷克隆)”
- 必须能快速的完成克隆操作。
- 必须有良好的read locality (读取局部性),这样逻辑上相关的文件集读取起来会比较快,同时经过COW后,性能也应该保持一致。
- 必须有良好的写性能,不管是对克隆前的文件集和克隆后的文件集进行写入。
- 空间利用率必须要好。写放大应该尽量保持比较低的水平。
作者在图1举例了现有的几种支持COW文件系统在多次克隆操作并且修改其中一小部分内容后,使用grep查询文件内容的衰减情况:
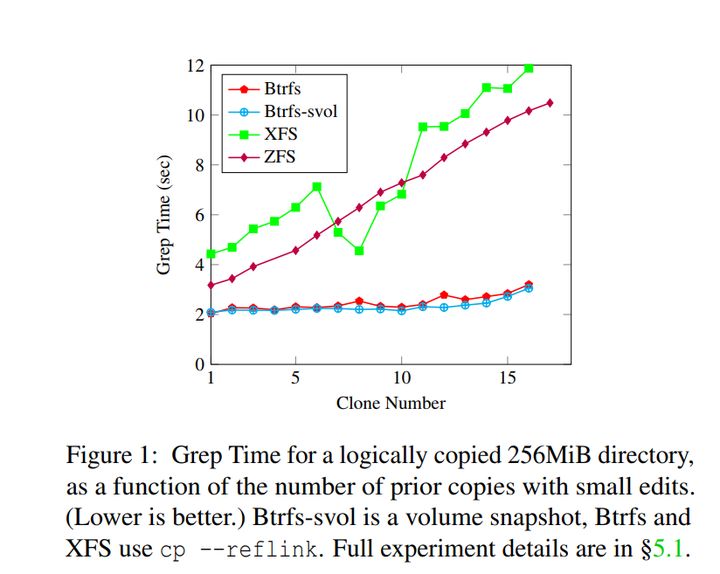
从图中可以看出,在每次克隆和修改之后,读性能都会衰减。看XFS和ZFS的结果,16轮后大概有3~5倍的衰减。Btrfs表现的好一些,大概只有50%的衰减。总体来看,这几个文件系统都出现性能单调递减的特征。
因此作者认为,这里的关键之处是应该将COW中的copy和write的大小进行解耦,即不应该使用一样的大小,如果是进行大的文件修改,那copy大块然后再覆盖写大块当然是合理的,但是如果是微小的修改,显然,应该将这次微小修改暂存起来,让多次微小修改进行聚合,在达到一定数量后,再批量处理显然会更合理一些。
这篇论文在现有的BetrFS基础上,实现了一种高效的克隆机制,以同时满足前述的Nimble clones需要具备的特征。作者引入了称作CAW(Copy-on-Abundant-Write)的技术,以暂存微小数据修改,等合适的时机再进行COW。另外,这篇论文在3方面对原来的Bε-tree数据结构进行了改进与增强,1.将原来的Bε-tree树结构改造成Bε-DAG结构(directed acyclic graph,有向无环图),以满足对整棵树进行更好的遍历。2.引入了GOTO message,可以快速的持久化克隆操作。3.引入“translation prefix(前缀转换)”,用来满足对“延后数据拷贝”和 部分共享数据的查询。在引入这些优化和改进后,实验结果显示,对不同的模型,至少有33%到6.8倍的性能提升。
论文的贡献点归结为:
- 设计和实现了Bε-DAG数据结构,作为Nimble clones的基础。该方法扩展了Bε-tree,用来聚集小的修改,再择机进行批量写入。
- 写优化的克隆实现。在进行克隆操作时,仅需简单的向DAG root节点写入一个GOTO message消息。
- 量化的渐进分析表明,增加克隆不会影响其它的操作。克隆算法开销是对数级别的。
- 全面的测试表明,优化过的BetrFS并没有对原来的BetrFS基线产生不利的影响,而在clone特性上,对比传统的支持克隆特性的文件系统,在性能上有3-4倍的提高,而对比不支持克隆特性的文件系统,则有2个数量级的提高。
03BetrFS背景知识
为深入理解这篇论文,需要先理解BetrFS的背景知识。BetrFS是该团队开发的一个用于研究型的文件系统,从2015年到现在,作者团队已经基于该文件系统发布了多篇论文,详情请参考BetrFS官网。
BetrFS是一个内核态的基于KV存储的本地文件系统。不同于传统的文件系统,如XFS,Ext4,这些文件系统都是基于inode和B-tree(或B-tree变体)来管理和组织元数据和文件系统数据的。而BetrFS是基于Key-Value的,它有2个KV stores。其中,元数据KV存储的是 文件全路径(fullpath) 到 文件系统元数据(struct stat)的映射。数据KV 存储的是 {fullpath+block number} 到 4K block的映射。
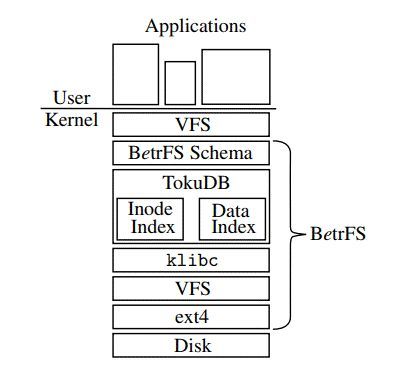
图片来源:附1
BetrFS后端使用的KV存储是基于TokuDB的内核修改版本,虽然是KV存储,但Bε-tree在实现上与我们常见的基于LSM的levelDB或者rocksdb不同,它在内部实际上比较类似于B-tree数据结构,可以称作是一种Better tree。
在附1中,作者团队详述了这种树的优点以及对于BetrFS的写优化。其中最关键的地方就是,这棵树在设计的时候,在树的node节点上预留了buffer空间。如下图,pivots与传统B-tree上的key一样,用来存放关键字key。而buffer则可以用来暂存一些对文件写的小IO,然后从root node上逐渐向叶子节点“流动”。一般的,设计node大小为2M~4M大小,这样在buffer空间将要写满的时候,才往下一级进行flush写入,这种优化能将小io写入转变成大块io写入,因此极大的提高了小IO写入的性能。
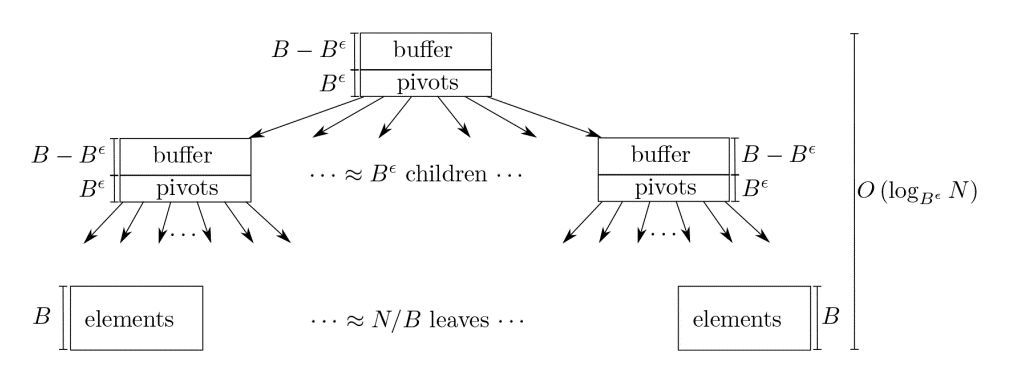
图片来源:附2
range查询
因为采用了基于fullpath的KV存储,比如基于下面的文件名,在存储时都有相同的前缀,所以在实际算法运行中,基本都会落在同一个node上,因此在做range查询时,比如遍历目录下面的所有子目录或者文件时,落在磁盘上的IO,也将会是连续的,所以遍历速度会很快。同时,在删除操作中,也比较容易对删除流程进行优化,比如设计一个delete message,实现标记删除,然后后续在进行删除操作。

基于fullpath的 rename操作
对于基于fullpath的文件rename操作来说,是比较有挑战性的。回想一下,在Bε-tree中,所有key都是全路径的,因此在rename一个文件夹时,比如文件夹A rename成B,那么A下面所有子文件夹和子文件的key都要做对应的修改。作者团队在 附3 的论文中给出的解决方案是使用range rename操作,这种方案的关键之处在于在内部存有一个指针,用来指向文件夹源和目的的子树,range rename的操作可以转换成将这个指针转向,即所谓“pointer swing”,后续子树会进行自愈,以达到rename的目的。关于这种方法的更多细节,请参考附3论文,这里不再展开。
掉电恢复一致性问题
文件系统掉电恢复一致性向来是文件系统值得研究的一个关键问题,典型如ext4,xfs都使用了journal机制和事务性来保证在异常掉电时,文件系统依然能正确恢复,从而达到一致性的状态。BetrFS的Bε-tree也使用了类似的机制,对Bε-tree进行的任何修改,都需要提前记录日志,Bε-tree会周期性的进行checkpoint,比如每60s 进行一次checkpoint,完成后,会修剪redo log。在异常掉电时,依靠回放redo log来达到一致性的状态。
04Cloning in BetrFS 0.5
这一章作者介绍了如何在BetrFS中实现克隆特性,首先作者先从克隆最基础的语义开始讲起
克隆操作语义

克隆动作是原子的,即要么成功要么失败,不允许有中间状态。
从KV-store的key空间角度来看,clone(s,d)意味着拷贝所有以s为前缀的key到新的以d为前缀的key,另外,它还会同时删除原来的以d为开头的key。
Lifted Bε-DAGs
克隆的本质是要在Bε-tree树上增加新的edge,以使得在访问克隆后的文件夹时,能通过某种方法访问克隆前的数据(克隆后的数据在不修改内容前,都是完全共享的)。在Bε-tree这样的数据结构上访问,是做不到这点的,因此,需要对Bε-tree进行改进,以支持共享访问,而DAG(有向无环图)可以完成这个功能。如下图所示,底层的node节点在DAG数据结构中,是可以被上面两个路径来访问的。
图片来源:附4
在对Bε-tree进行改进时,作者强调需要解决3个问题:
1、因为对node可能有来自多个路径的访问,所以需要对node维护一份引用计数,引用计数并不存放在node本身的数据结构中,而是存放在专门的 node translation table 中,这样在修改引用计数时,并不需要更改node数据结构本身,避免了需要加速解锁等操作,以便于提升性能。
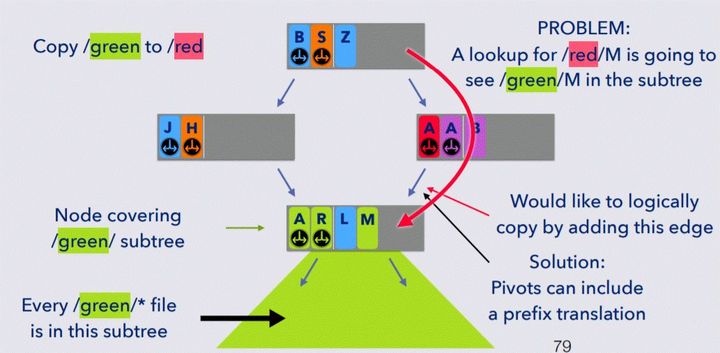
2、问题2是在Bε-tree中,node通常设置的比较大,如2M~4M大小,这样也就意味着1个node上会有很多key值。因此,共享target node意味着会有一些冗余的key也会被共享,例如如下图2所示:
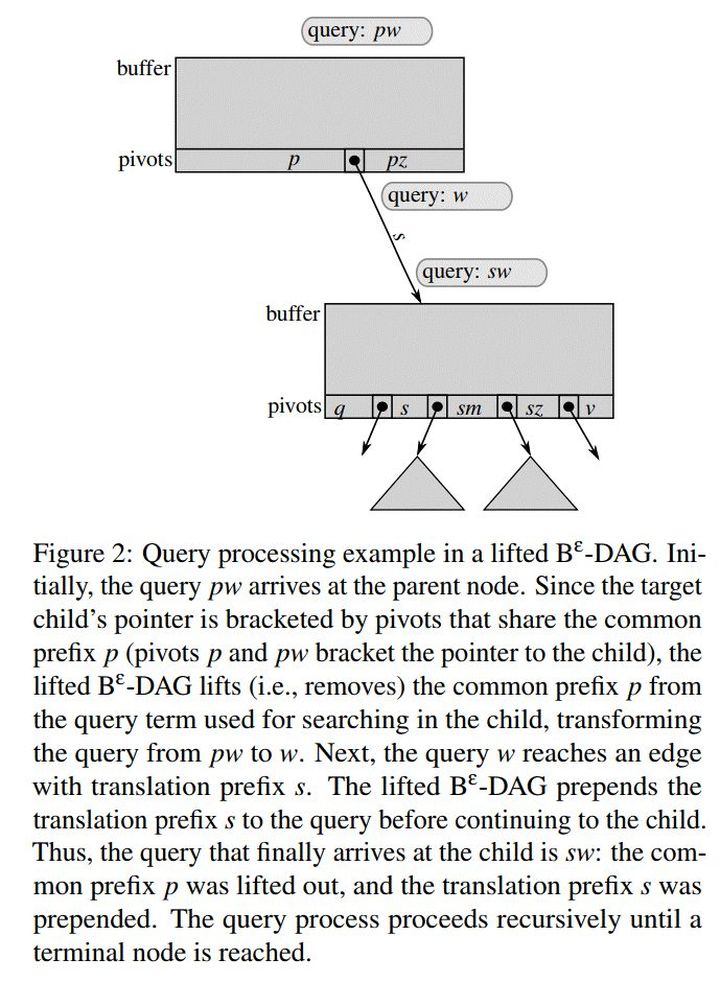
底下的node包含了所有以s为前缀的key空间,但同时也包含了以q和v开头的key,而这些key是冗余的,不应该被访问到的。因此,作者在这里对pivots域内的key使用了过滤技术,以用来过滤那些冗余的key。
3、使用translation prefix(前缀转换)技术,还是如上面图2所示,在将s开头的目录转换成以p开头的目录后,会在上面的节点上插入指针,指向下面的节点,那后续查询pw时,在pivots找到指向下面的节点,但因为是clone过来的,所以这里需要进行translation prefix,即先去掉p,在下面节点查询时,按照sw进行查询。这种转换只是临时的,因为克隆最终完成时,需要将节点变成一般的节点,后文会有描述。
Creating clones with GOTO messages
论文接下来讲述创建克隆的过程。首先,如下图3所示,要clone所有以s开头的key到以p开头的key,则需要先找到所有以s开头的key node的父节点,称作 LCA (lowest-common ancestor);
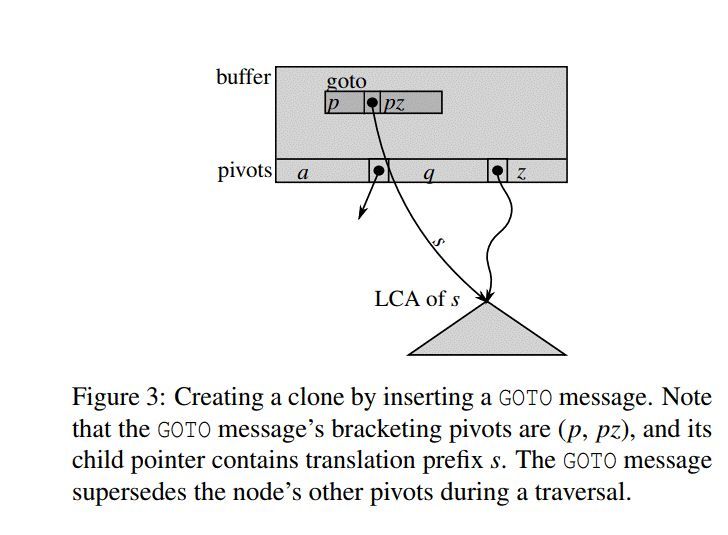
接着要做的是一次flush操作,即将从最开始的root节点到LCA之间节点暂存的所有以s开头的key都持久化下来,以保证LCA是完整的包含了以s开头的完整key空间。待flush完成后,再向root节点插入一条GOTO message,则完成clone过程。
那么这个GOTO message是做什么用处呢,这个是克隆动作本身的关键。它的组成大概是这样的:
(a,b) - hight - dst_node
(a,b) 表示覆盖的key空间, hight表示的是到target node的高度,dst_node表示目标 target。
比如,若要查询的key为x,则先判断x是否落在(a,b)指示的key区间,如果落在这个区间,则接着会直接到dst_node 处继续进行查找。换句话说,goto message能够改变查找方向。
Flushing GOTO messages
GOTO message可以通过flush的方式,从root node向下面的node滑动。通过这种消息机制,可以将DAG中的遍历寻址信息编码进来,这样可以非常高效的完成克隆操作。GOTO message强大之处在于之后发生的所有查询,都因为GOTO确定的新的路径而发生了改变,换句话说,GOTO message能隐含的删除原来的所有以特定前缀开头的key空间。
Converting a GOTO
Goto message的转换过程和flush过程类似,在向下层滑动的时候,都会涉及到对重叠区的key空间的合并和处理,如下图:

左边,区间 (pab,t) 包含了pivots区域内的 (pz,r), 因此在将goto message转换成标准 pivots时,会将原来的(pz,r) key空间删除掉,将 (pab,t)空间加入进去。
而在部分重叠的情况下,还要更为复杂一些。比如上图左边的(pa,pz) 和(r,w)的部分重叠于 (pab,t)。

在经过处理后,要注意的是 (pa,pab)这个空间的key,要加上前缀as2,因为在老的空间 (pa,pz), 向下查询时,前缀是s2,但经过转换后,pa前缀被去除,必须要把a加上才能和原来的key一致。这个是所谓的”lifted Bε-tree”技术,在作者团队的附3论文中有详述。
Flushes, splits, and merges
论文接下来讲节点的flush,split和merge。从较高层次上看,需要2个过程:
1、需要将children node转换成 simple children
2、再执行标准的Bε-tree flush,split 和merge过程
Simple child的定义是该node引用计数为1,并且其边指向的child没有 translation prefix。
在child都simple化后,Bε-DAG就形式化为 Bε-tree了,因此可以使用Bε-tree的方式进行节点的flush,split和merge。
有至少两种场景都需要将一个节点simple化。第一种情况是其parent节点在buffer空间中累积了足够多的修改,需要执行CAW操作时。第二种情况是后台的heal线程在调整target的fanout时,需要进行split和merge操作,从而引发将节点simple化。注意,Simple化一个节点是在 flush, split 或者merge的过程中进行的。
Simple化一个节点时,首先要做的就是先进行一次private 拷贝节点,如图5所示:
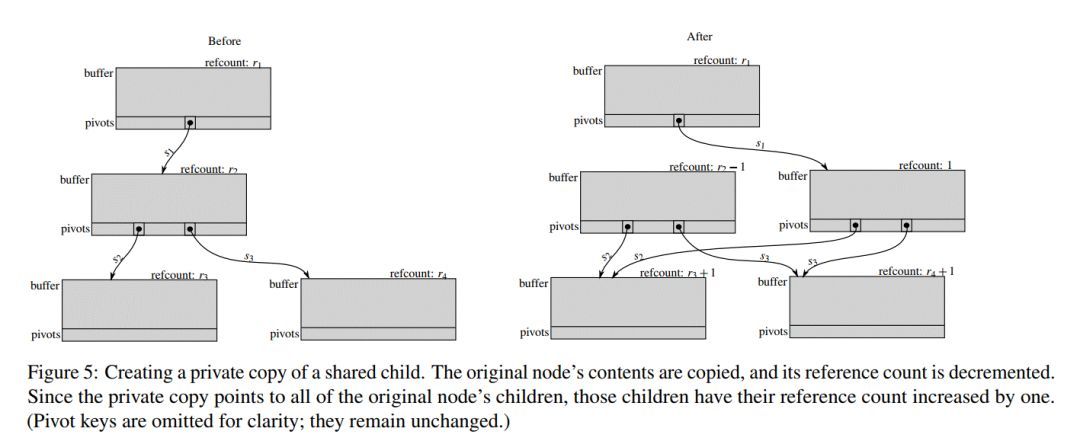
得到这个private node以后,就可以对这个node进行“整理”,如下图,最左边的是最初的private node,里面的一些key空间是冗余的,会被删除,中间的图即是删除掉冗余key的图,最后,translation prefix也会被删除。
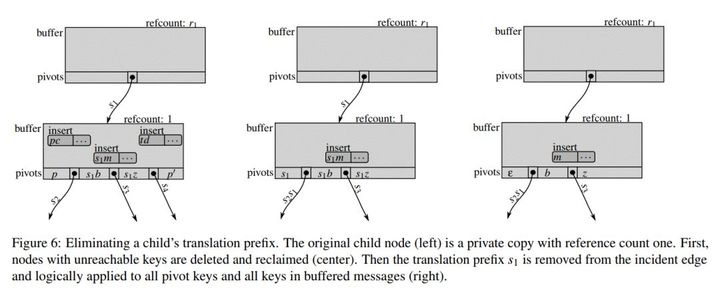
值得注意的是,这些复杂的步骤只是在clone以后,有数据写入时,而且达到一定条件后才触发的,或者是在后台为了平衡Bε-DAG状态而进行的。对于那些未修改的共享node,是不需要进行这些复杂的过程的。
05算法渐进分析
对Bε-DAG的渐进分析表明,插入,查询,和克隆的复杂度都只与Bε-DAG的高度有关,它的渐进复杂度与lifted Bε-tree是一致的。可以这样考虑,如果我们将GOTO message都flush下去,转换成一般的pivots,这样消除掉GOTO message后,再断开共享的node链接后,就会形成一棵Bε-tree,这棵树的高度最高也就和Bε-DAG的高度相同。
Bε-tree和Bε-DAG的高度都是 O(logB N), 前者N是指tree的key number,后者的N是指clone前的key加上clone的key个数。
查询:因为Bε-DAG的高度是 O(logB N),因此IO查询代价也是O(logB N)
插入:插入的复杂度和Bε-tree也是一样,为:
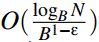
克隆:克隆的过程可以分为2个阶段,第一个阶段是在线的,第二个阶段是后台的。在线阶段只包含将LCA以上的含有s的消息flush到LCA上和向root node上插入一条GOTO message的代价。这个代价是O(logB N)级别,后台处理阶段主要是后台进程将GOTO message向下flush,并且最终转换为一般的pivots。其算法复杂度也是O(logB N)级别。
06评估分析
论文在评估分析一章中给出了性能测试结果,主要回答了如下几个问题:
- BetrFS 0.5中实现的克隆特性是否满足如下这4个设计目标:能高速创建克隆吗,读满足局部性原理吗,满足快速写吗,空间浪费如何;
- 引入克隆特性,是否会对以前版本的性能造成冲击;
- 克隆特性是否能提高真实应用的性能。
作者对比了如下文件系统:baseline BetrFS(指没有克隆特性的BetrFS 0.4版本), ext4, Btrfs, XFS, ZFS, and NILFS2。
克隆性能
在克隆性能测试中,作者选择的是 单个目录下创建8个子目录,每个子目录下1个4M大小的文件,然后对这个目录进行克隆,在每次克隆后,向clone后的每个文件写入16字节(4KB对齐),以模拟小块IO修改。
图7-a是clone延迟结果,图7-b是做16字节修改的写时延,图7-c是grep clone文件的读时延:
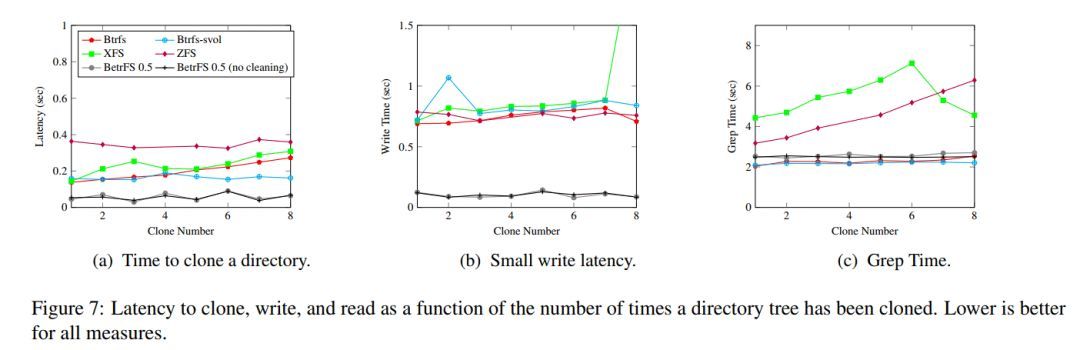
在对比文件系统中,Btrfs使用基于reflink和volume snapshot两种模式,XFS使用reflink模式,ZFS使用volume snapshot模式。对于BetrFS,使用了禁止后台处理的 no cleaning模式和允许后台处理的正常模式。从结果可以看出,禁止后台处理模式和正常模式在性能表现基本一致,只是在空间利用率方面会产生一些波动。
分析创建clone的时延,BetrFS大概只需要60ms的时延,这个结果比XFS快33%,比基于svol的Btrfs快58%,比起ZFS,则是有一个数量级的提高。另外,在多次clone后,BetrFS性能基本不会发生大的变化,而Btrfs和XFS则随着克隆数的增多,时延会逐渐增大,大概在8轮之后,时延就显示出翻倍了。
在写时延方面,BetrFS性能是其它文件系统性能的8~10倍,这主要还是得益于BetrFS的CAW特性,其它文件系统基本都是COW类型的。另外随着clone数的增加,所有这些文件系统基本都没有明显的写性能损失。
在读时延方面,因为grep操作基本属于scan类型的操作,BetrFS表现的很稳定,不会随着clone数的增加而衰减,而XFS和ZFS有着比较明显的衰减趋势,Btrfs也会衰减,但不是太严重,8次clone后,Btrfs-svol类型的衰减大概在10%,Btrfs文件类型的衰减大概在20%。另外作者也指出,在17次clone后,Btrfs衰减大概到了50%(图中没有画出)。
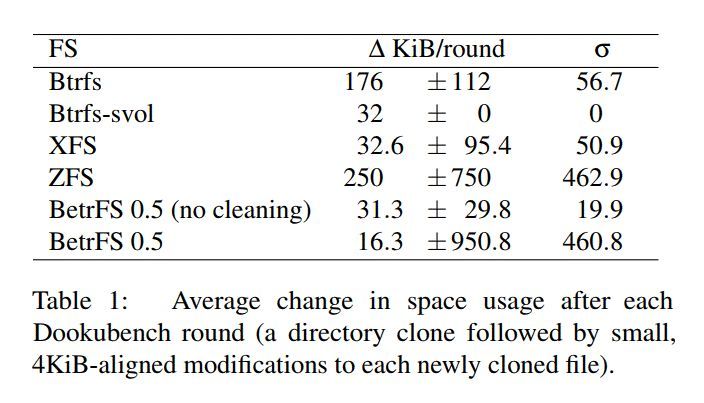
下面表1显示的是空间开销,可以看出,每次clone修改,BetrFS 引入的开销只有16K左右,比其它文件系统都要好很多,另外,因为BetrFS后台的clean动作,会导致空间利用率有波动,在no clean模式下,空间开销会稳定在32K。总之,结果表明,在空间开销方面,BetrFS完成了预期的目标,不会对空间造成浪费。
那么,BetrFS在其它文件操作模型下表现如何呢,作者也选取了一些用例进行评测。
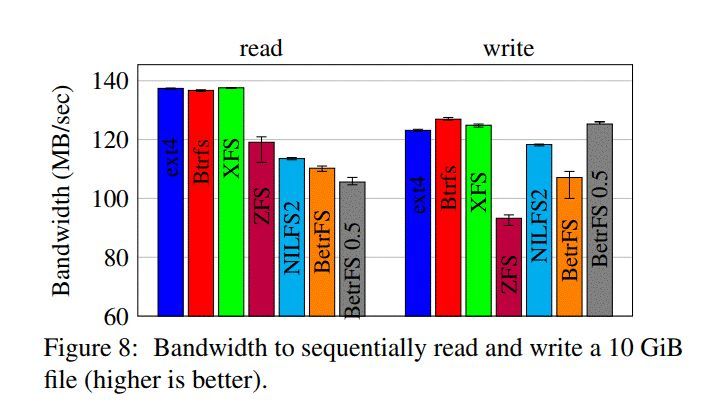
顺序IO
在顺序读写IO方面,都能达到一个可以接受的性能。读性能方面,比最快的ext4文件系统,大概慢19%,在顺序写方面,比最快的Btrfs大概只慢6%。
随机IO
在随机读写性能测试中,作者选择 向一个10G大文件中随机进行 256K 个 4字节的读写,写入时是带上fsync标志以保证持久化到磁盘。
结果表明,对于随机写,BetrFS 0.5比传统的文件系统大概要快39到67倍,而比起不带clone的BetrFS 0.4,大概只慢了8.5%。而对于随机读,BetrFS 0.5 比 最快的Btrfs只慢了12%。

TokuBench测试
作者使用TokuBench软件进行海量文件创建测试,大概创建3百万个200字节的小文件,分布在多个子目录中,每个子目录保持一定的平衡度,即不超过128个子目录或者128个子文件。结果表明,在海量小文件创建方面,BetrFS0.5和BetrFS0.4性能基本一致,比起Ext4文件系统,提高了大概95倍。
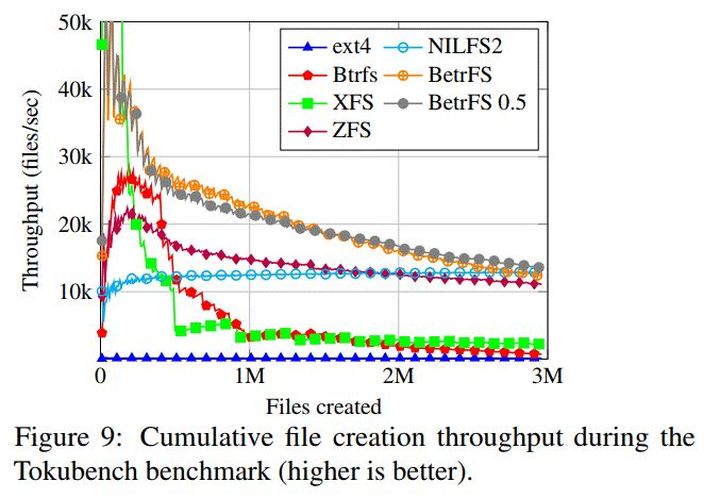
目录操作性能
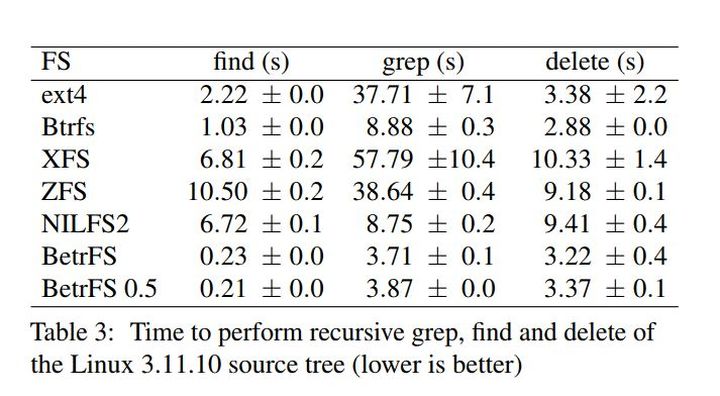
在目录操作性能测试中,主要进行了递归的grep,find和delete操作,结果如下表所示,BetrFS 0.5和BetrFS 0.4性能基本一致,不会因为clone的引入而对性能有所损失,而比起传统的文件系统性能,都是有数量级的性能提高。
具体应用的性能评测
在具体应用程序的评测方面,作者选取了 git clone,tar,rsync,IMAP server进行测试,结果如下:
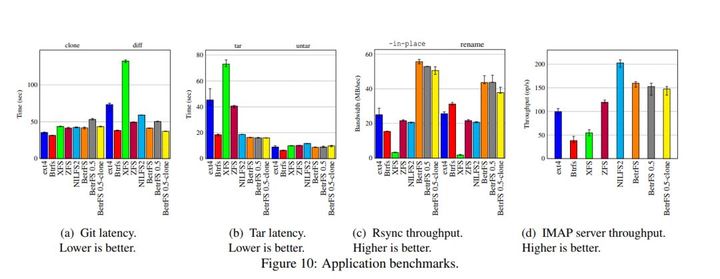
图中的 BetrFS 0.5是在还没有克隆过的目录里面执行, BetrFS 0.5-clone 是在克隆后的目录里面执行。
从结果可以看出,BetrFS在大部分场景中,都获得了最好的性能。在极个别场景中,BetrFS会有稍微的性能损耗,但也都是在可接受范围内。
容器场景
作者在 Linux Containers (LXC)场景中测试了clone的真实表现。容器后端默认使用Dir后端,这个后端内部实现为使用rsync进行复制目录,另外还可以定制自己的后端,在定制后端里面,可以高效的使用自己的clone机制。

如表所示,BetrFS实现的容器后端克隆特性比ZFS和BetrFS要快好几倍,比起传统的Dir实现,则是好几个数量级的提高。
07结语
通过将CoW特性中的copy和write进行解耦,作者团队在已有的BetrFS之上,开发出了具有高效率的clone/读/写以及高效的空间使用率的新的文件系统。从性能测试结果以及真实应用的表现来看,都完成了这些看似矛盾的目标。同时,使用的一些如诸如小IO汇聚,批量写入,Bε-DAG等数据结构与技术都是比较通用的技术,可以用于任何以Key-value store为基础的应用软件上,而不仅仅只是文件系统。
附1:FAST15 BetrFS: A Right-Optimized Write-Optimized File System(http://supertech.csail.mit.edu/papers/JannenYuZh15a.pdf)
附2:An Introduction to Bε-trees and WriteOptimization(https://www.usenix.org/system/files/login/articles/login_oct15_05_bender.pdf)
附3:The Full Path to Full-Path Indexing(https://www.usenix.org/system/files/conference/fast18/fast18-zhan.pdf)
附4:How to Copy Files slide(https://www.usenix.org/sites/default/files/conference/protected-files/fast20_slides_conway.pdf)
附5:原始论文链接 how to copy file(https://www.usenix.org/system/files/fast20-zhan.pdf)
发布于 2020-06-03
https://zhuanlan.zhihu.com/p/145642958
这篇关于XSKY解读FAST‘20 论文 《关于如何高效率的对文件目录树进行快速克隆操作》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





