本文主要是介绍【I/O】基于事件驱动的 I/O 模型---Reactor,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Reactor 模型
BIO 到 I/O 多路复用
为每个连接都创建一个线程
假设我们现在有一个服务器,想要对接多个客户端,那么最简单的方法就是服务端为每个连接都创建一个线程,处理完业务逻辑后,随着连接关闭线程也要销毁,但是这样线程创建和销毁,不仅会带来性能开销也会带来资源浪费,如果同时有几万个连接,创建几万个线程是不现实的。
使用线程池优化
我们很容易想到使用线程池来优化,也就是不再为每个连接都创建一个线程,而是创建一个「线程池」,将连接分配给线程,然后一个线程可以处理多个连接业务,不过这样的话又会有一个新的问题,当一个连接对应一个线程的时候,线程的处理流程一般是 read -> 业务处理 -> send,当没有数据可读的时候,线程会阻塞在 read 上,所以我们在使用线程池的时候,如果某个线程阻塞在了 read 上,它是没有办法继续处理其他连接的业务。
要解决这一问题,我们需要将连接改为「非阻塞」的,然后线程不断轮询调用 read 操作来查看是否有数据可读,但是轮询也是需要消耗 CPU 的,同时一个线程管理的连接越多轮询的消耗也就越大。
I/O 多路复用
线程池带来的问题在于,线程不知道当前连接是否有数据可读,因此需要不断的轮询进行 read 操作去检测哪个连接有数据可读。I/O 多路复用可以很好的解决这一问题,I/O 多路复用使得只有当连接上有数据的时候,才去发起 read 操作,I/O 多路复用会用一个系统调用函数(select() poll() epoll() )来监听我们所关心的连接,通过系统调用可以从内核中获取多个事件。
在获取事件时,先把我们关心的连接发送个内核,在有内核进行检测:
- 如果没有事件发生,线程只需要阻塞这个系统调用,而无需像前面的线程池方案那样轮询调用 read 操作
- 如果有事件发生,内核会返回产生了事件的连接,线程就会从阻塞状态返回,然后在用户态再处理这些连接的业务即可
Reactor 模型
Reactor 模型: I/O 多路复用监听事件,收到事件后,根据事件类型分配给某个线程。
Reactor 主要由 Reactor 和 处理资源池 两个核心部分组成:
- Reactor 负责监听和分发事件,事件包括连接事件、读写事件
- 处理资源池负责处理事件,如 read -> 业务处理 -> send
单 Reactor 单线程
三个对象 Reactor、Acceptor、Handler
- Reactor 对象的作用是监听和分发事件
- Acceptor 对象的作用是获取连接
- Handler 对象的作用是处理业务

select、accept、read、send 是系统调用函数,dispatch 是事件分发操作
流程:
- Reactor 对象通过 select 监听事件,收到事件后通过 dispatch 进行分发
- 如果事件是建立连接的事件,则交由 Acceptor 对象进行处理,Acceptor 对象会通过 accept 方法获取连接,并将连接注册到 select 上,然后创建一个 Handler 对象来处理后续的响应事件
- 如果不是连接创建事件,则交由对应的 Handler 对象来进行处理
- Handler 对象通过 read -> 业务处理 -> send 的流程来完成完整的业务流程
单 Reactor 单线程方案,所有的工作都在一个线程上完成,实现简单,但有两个缺点:
- 只有一个线程,无法利用多核 CPU 的优势
- Handler 对象在业务处理时,整个线程无法处理其他连接的事件,如果业务耗时比较长的话,会出现响应延迟
单 Reactor 多线程
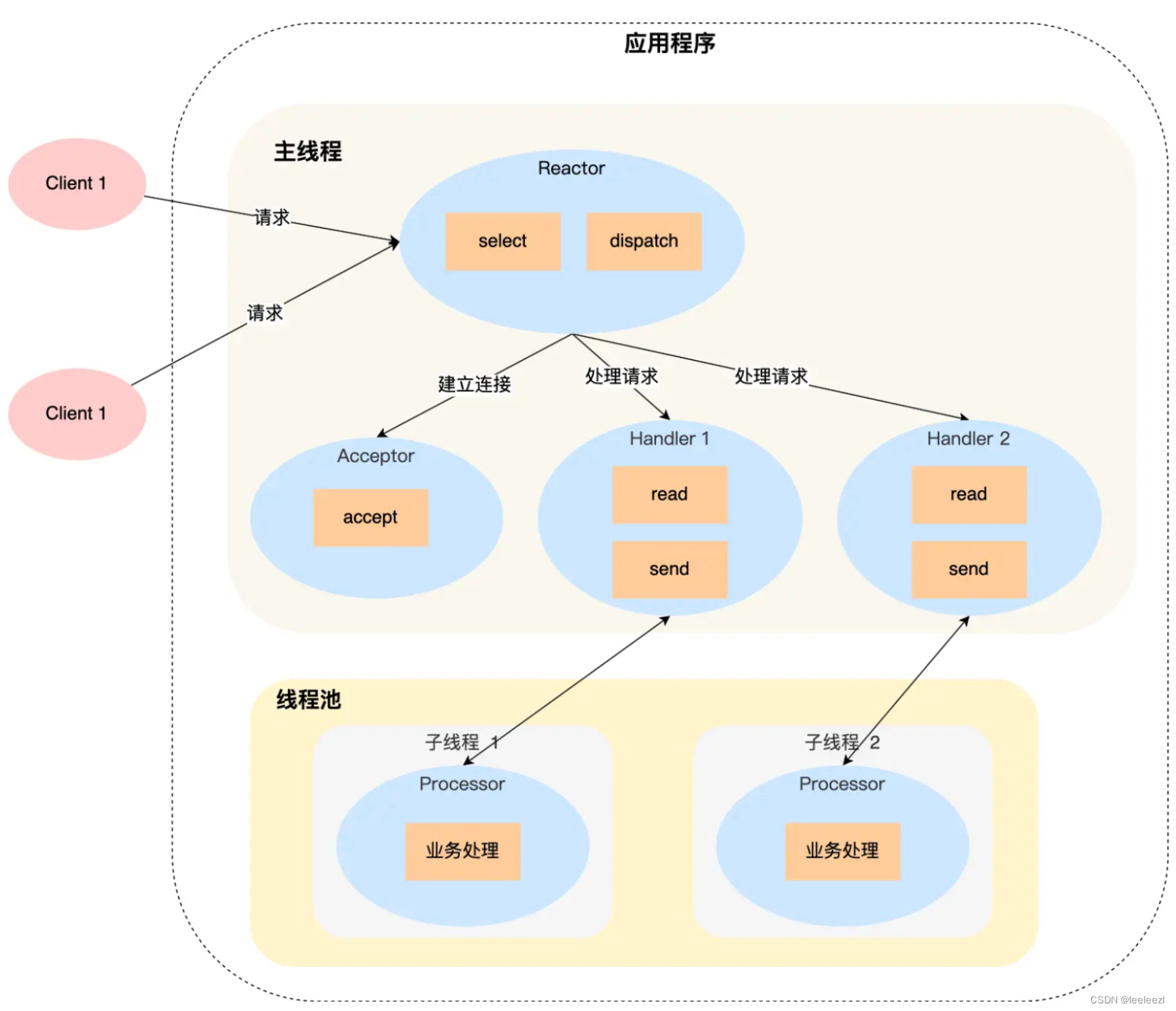
流程:
- Reactor 对象通过 select 监听事件,收到事件后通过 dispatch 分发事件
- 如果是连接事件,则将其分发给 Acceptor 对象进行处理,Acceptor 对象通过 accept 方法获取连接,并将连接注册到 select ,然后创建一个 Handler 对象来处理后续的响应事件
- 如果不是创建连接事件,则交由对应的 Handler 对象进行处理
- Handler 对象不再进行业务处理,只负责数据的接收和发送,Handler 对象通过 read 方法读取连接中的数据后,会将数据发送给子线程里的 Processor 对象进行业务处理
- 子线程的 Processor 对象就进行业务处理,业务处理完成后,将结果发送给主线程中的 Handler 对象,接着由 Handler 对象负责将结果使用send方法发送给客户端
单 Reactor 多线程方案能够充分利用多核 CPU 的能力,但是即使业务处理是采用线程池多线程的进行,但是最后还是要靠主线程的 Handler 进行发送,这就带来了 多线程共享数据竞争 的问题,要避免这个问题就不得不在访问共享数据是加上互斥锁,来保证在任一时间内只有一个线程访问共享数据。
单 Reactor 单线程方案还有一个问题,一个 Reactor 担任事件的监听和分发任务,而且是在主线程中进行的,在面对瞬时间的高并发场景,很容易成为性能的瓶颈
多 Reactor 多线程
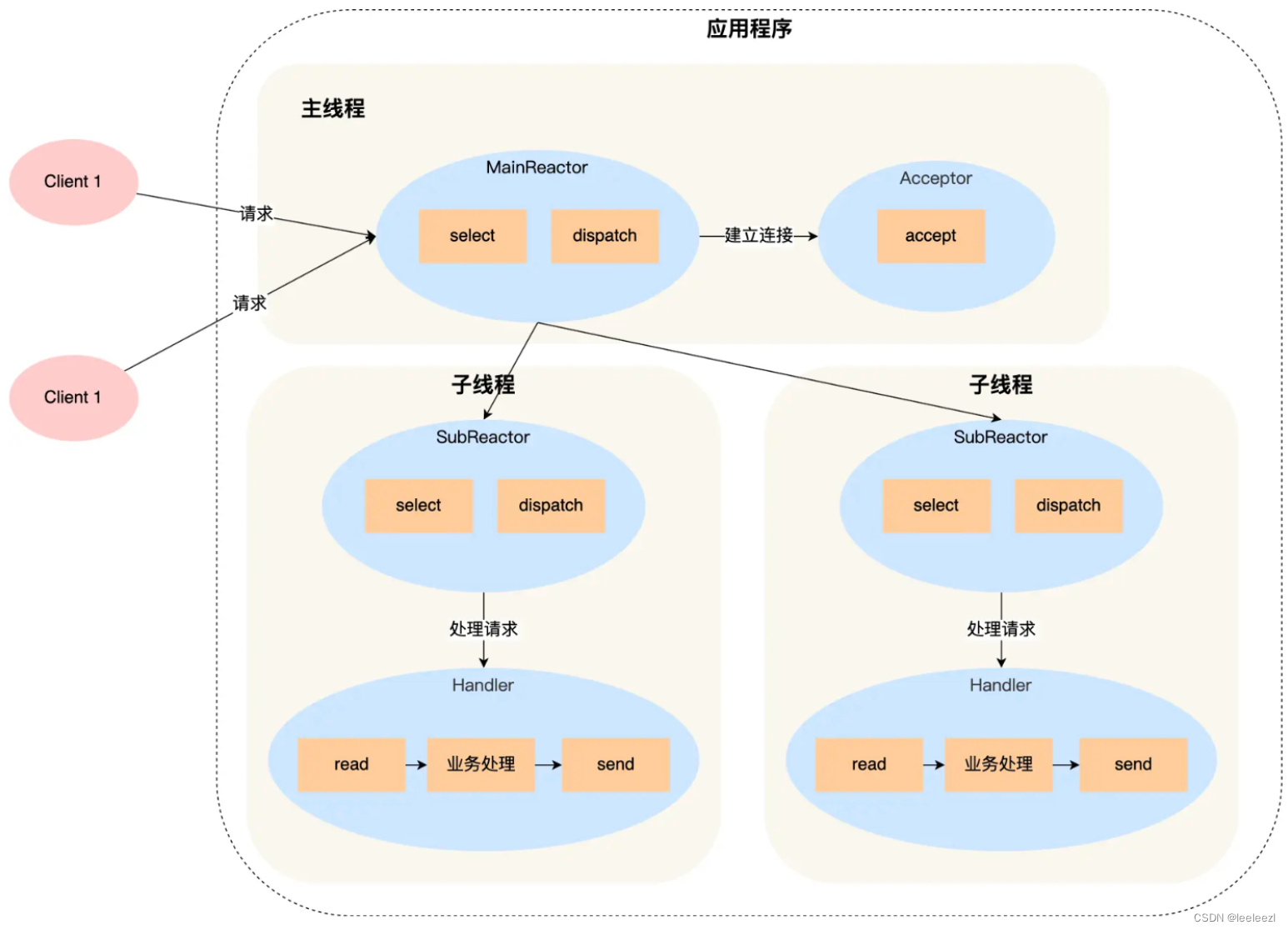
流程:
- 主线程的 MainReactor 通过 select 只监听建立连接事件,收到事件后交给 Acceptor 对象,Acceptor 对象通过 accept 获取连接,随后 MainReactor 将新的连接分配给某个子线程
- 子线程的 SubReactor 对象将主线程分配的连接注册到 select 上继续进行监听,并创建一个 Handler 对象进行后续连接的响应事件
- 如果有新的事件发生,SubReactor 会调用对应连接的 Handler 进行事件响应
- Handler 对象通过 read -> 业务处理 -> send 的流程来完成完整的业务流程
优点:
- 主线程和子线程分工明确,主线程只负责接收新连接,子线程负责负责监听连接的读写事件以及后续的业务处理
- 主线程和子线程的交互也很简单,主线程只需要把新的连接传递给子线程,子线程无需返回数据,直接可以在子线程中完成数据的处理和发送给客户端
这篇关于【I/O】基于事件驱动的 I/O 模型---Reactor的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








