本文主要是介绍高通量培养组学筛选,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目前二代高通量测序已经成为研究人体、动物、植物等菌群结构常用的一种方法,该方法仅仅可以得到样本中微生物的种类和相对丰度,而无法拿到具体菌株。
微基生物专注微生态研究和应用,不仅具有二代高通量测序平台,而且还建立了菌群需氧/厌氧分离培养平台,为客户提供高效的需氧/厌氧菌的非靶向分离培养服务,帮助客户获得粪便、肠道、土壤、淤泥等样本中大多数菌株。
可培养样本
可培养粪便、肠道组织、土壤、淤泥、植物、药品等样本中微生物
样本保存和运输
在采样之前,微基生物先给客户寄送厌氧或需氧保存液,客户可将采集的新鲜样本放入保存液中,之后将带有样本的保存液,寄回微基生物即可。
检测流程:
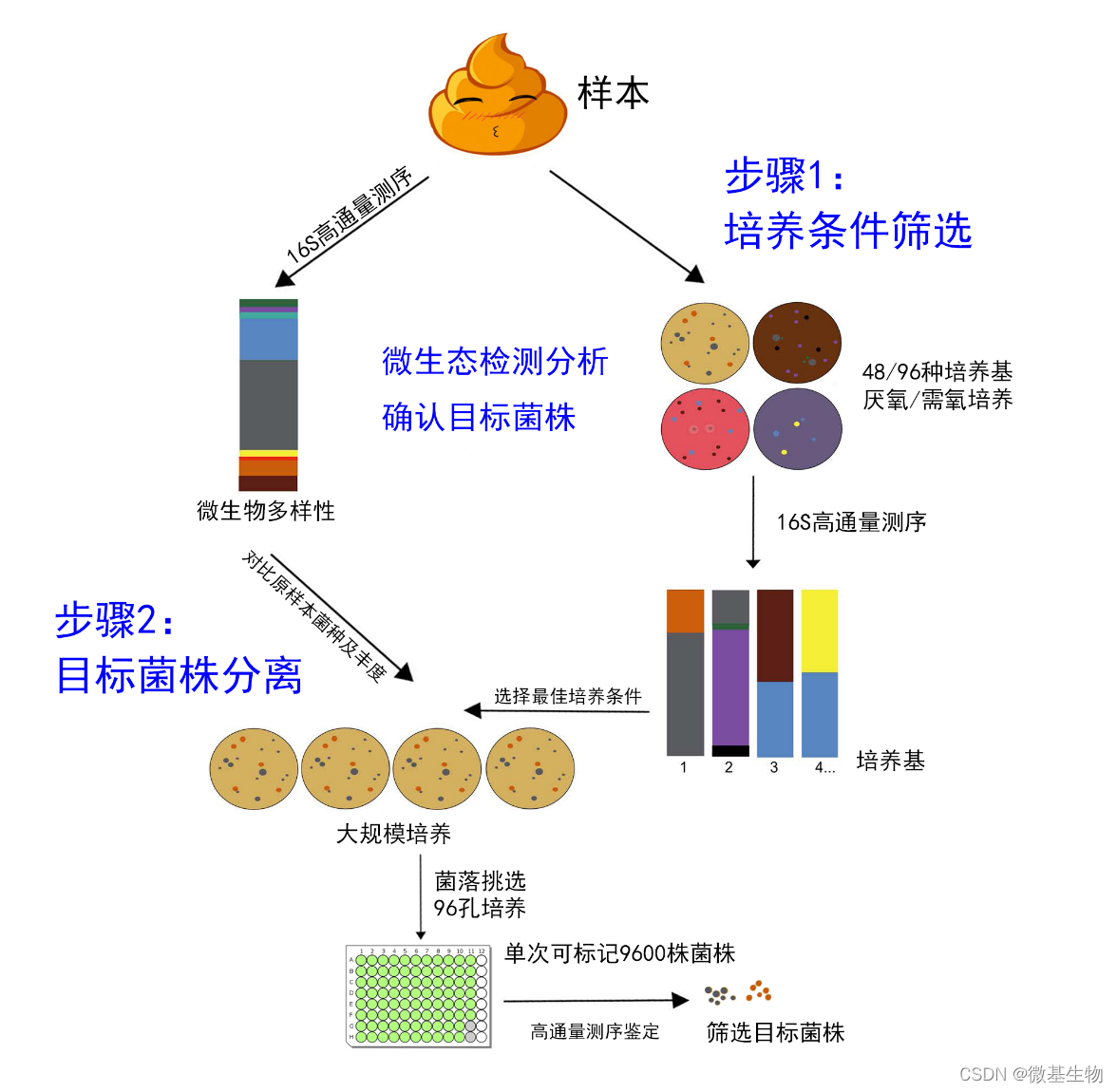
1 首先通过二代高通量深度测序技术,检测样本中微生物的种类及其相对丰度。
2 采用3种培养条件(需氧/厌氧/微需氧),48/96种培养基对样本分别进行培养,尽可能多的培养出菌株。
3 对样本中的微生物进行培养,同时利用96孔板进行大规模的分离、纯化等反复操作,尽可能纯化较多的菌株。
4 对最终纯化好的菌株进行菌种鉴定,从基因水平上再次确认菌株的分类学属性。
5 根据客户的需求,对纯化好的菌株进行扩繁培养。
这篇关于高通量培养组学筛选的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






